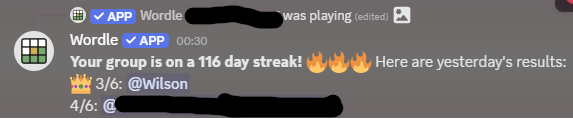
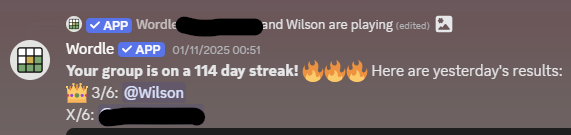
I saw someone else do a write-up of their homelab so I thought I’d do a short one of mine.
Hardware
It’s pretty basic. When I rebuilt my workstation I took the old machine, gave away the graphics card to a friend, and installed ubuntu server on it. It has a i7-8700 on it and 64GB of ram and sits in a closet just below my router (a Unifi Dream Router 7, to be honest I didn’t think home routers could be so good). That router also can serve as a VPN so I can be on my LAN while not at home.
Hestia
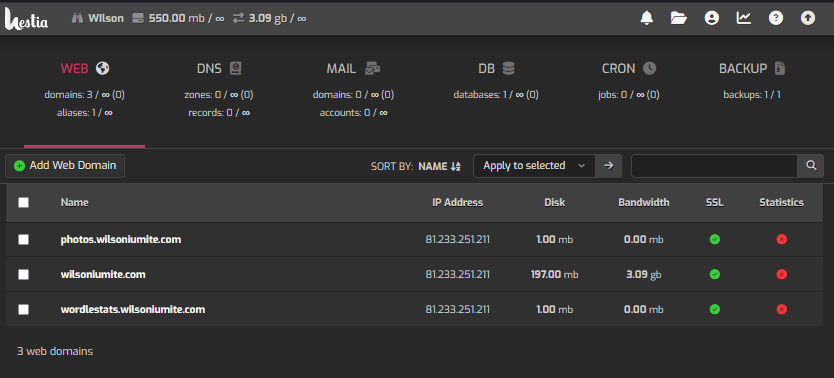
I wanted some way to host a blog and originally set up hestia to orchestrate the whole thing. It’s a bit overkill for what I need (I don’t use DNS or Mail or lots of the other cool things, and I’m the only real user), but it works pretty well. From there, I manage 3 domains that point to different services.
wilsoniumite.com – This blog, a wordpress site
photos.wilsoniumite.com – Immich
wordlestats.wilsoniumite.com – A wordle bot
This blog
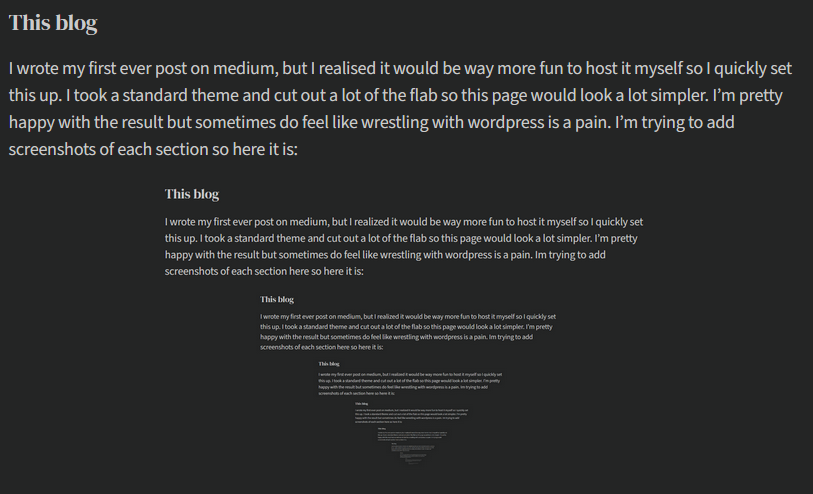
I wrote my first ever post on medium, but I realised it would be way more fun to host it myself so I quickly set this up. I took a standard theme and cut out a lot of the flab so this page would look a lot simpler. I’m pretty happy with the result but sometimes do feel like wrestling with wordpress is a pain. I’m trying to add screenshots of each section so here it is:
Immich
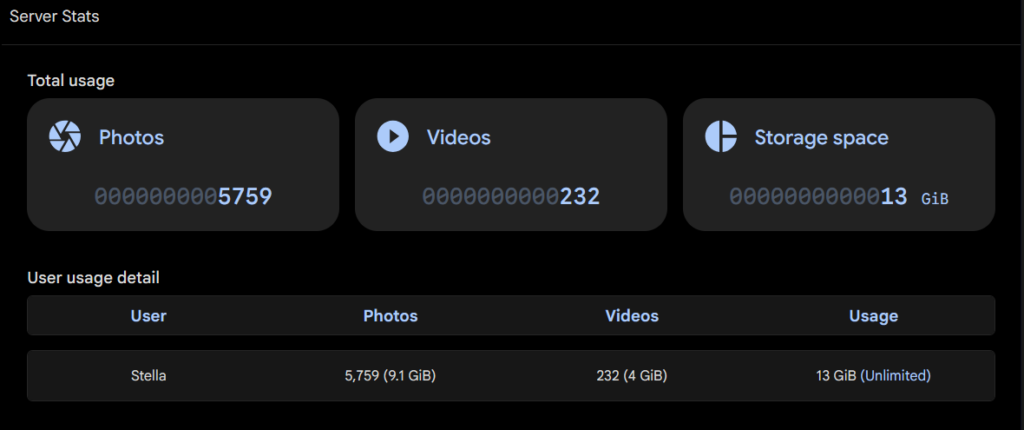
That other homelab post mentioned Immich and it seemed like such a good idea. I was already annoyed that google constantly complained I was using too much storage for my photos, and honestly I didn’t want to trust them with it anyways. Immich is great, I just need the app on my phone and it works exactly like google photos except way more fun and I get a terabyte of storage (or a bit less, my NVMe is 1TB).
wordlestat
I made a discord bot that is now used by a few dozen guilds to create leaderboards for wordle results. I wrote about it here. When people interact with the bot discord forwards that request to my endpoint and the Node server handles it.
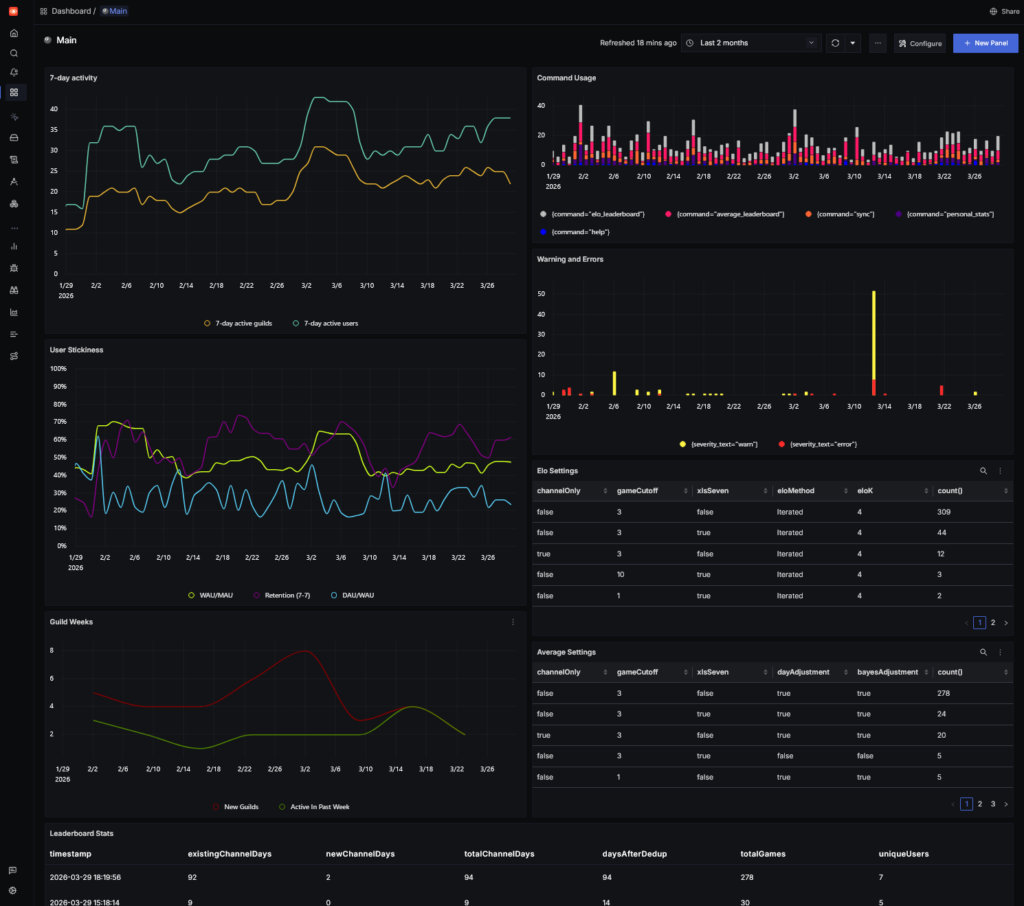
Signoz
The wordle bot had some teething issues and I wanted to be able to observe usage in more detail, so there is an unexposed signoz instance that gathers logs from that, as well as general metrics from the server like cpu and ram usage. It’s been really useful in tracking the usage of the bot, here’s an example of the dashboard:
Restic & Hetzner
I realised it would be very sad to lose this blog, the wordle bot, and my image library, so I finally set up an off-site backup of everything. For just a few euros a month I copy it all over to a datacenter in Finland. Worth it for the peace of mind. With that said, I should probably be using backrest rather than setting all this up manually.
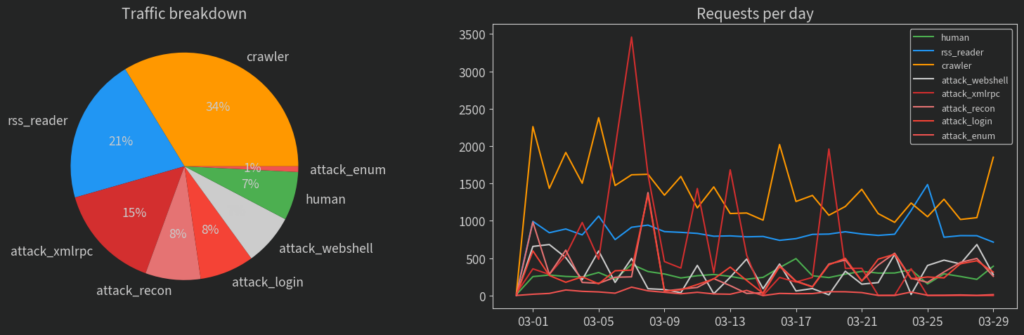
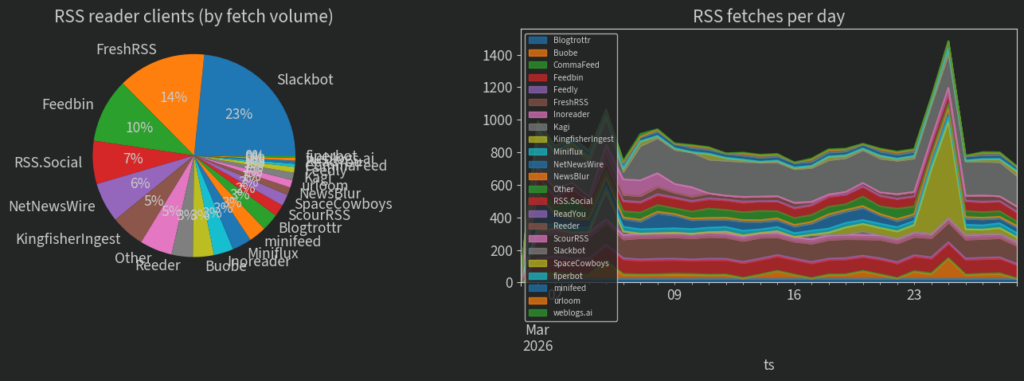
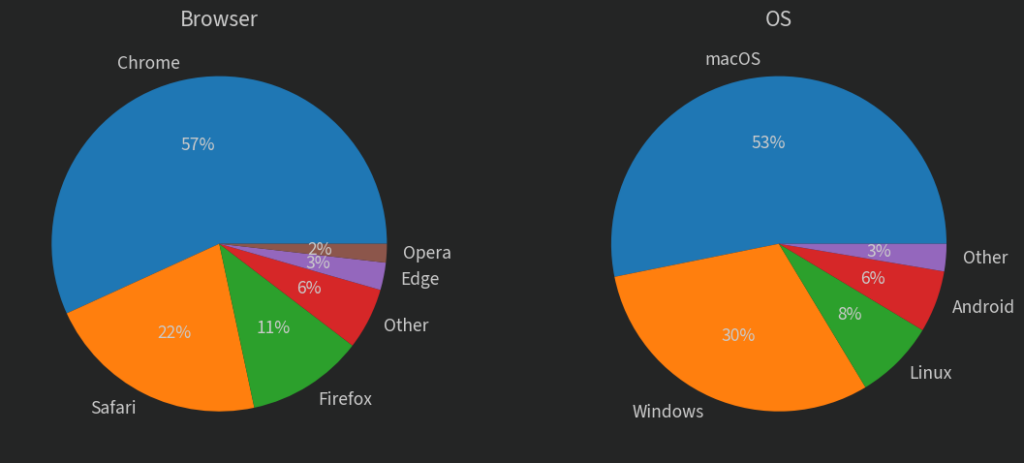
What kind of traffic do I get to my blog?
I thought I’d add a little addendum with some analysis of the log files for wilsoniumite.com. I’ve done my best to filter out bots properly, but I think a lot of them still snuck through. Here’s the breakdown (from a month where none of my posts have been popular anywhere):
She had landed on the other side, just in the same way she had a few hundred, perhaps thousand times before. A small piece of wood that was just long and stable enough to support her weight as it spanned a gap three times longer than herself. It was a warm day, the sun in just the right position to align with this part of the meandering river below, heating the stones of the bridge she now traversed the underside of. A mix of old growth vegetation and wooden scaffold made this edge of the village perfect for her, obstacles and paths she knew, her whiskers brushing against the stone on her right as she made her way up the far side of the span.
She’d come now to the highest point, and could look both ways toward the few houses of the village, or toward the trees of the forest line. One way lay the house she’d spent many years in. By no means an unhappy place, it was warm year round, and there lived a kind young boy that took care of her, fed her, housed her. It seemed almost unfair to think nonetheless of what might be on the other side of the bridge. Something new, different, obviously not quite as safe as where she’d come, and yet still someplace almost as right for her as home. She’d thought many times about this, of going further, every day while following this path around the bridge contemplating if this day would be the one. What was it she still needed? No piece of truly new information would come to her any more on these rounds. No amount of further assessment would make the unknown more known to her. As she sat there, upon the cold morning brick with the sun against her fur, it felt that the only sensible thing left to do was to flip a coin, and simply decide which way. Or, well, not a fair coin. It was obvious on which side it would land, it’s just that she had to believe there was nothing more to be gained from trying to further work out the perfect course of action. All that remained for her, Ozana as she called herself, was to hop off those final bricks of the bridge, and begin trotting toward the trees.
A simple model of how the economy works is it’s some kind of rewards system. You do something good that other people will pay you for and you are then rewarded with money. You are a smart engineer and your boss gives you a raise, you’re a smart entrepreneur and VCs give you tons of money. That money entitles you to stuff, the idea being that there is only so much stuff, yachts, housing, fancy clothes, holidays, and you are rewarded for being good at something by being first in line to get that stuff in lieu of someone else getting it. And then we say that this encourages people to work hard and be smart, and that is good for society overall. This is perhaps true to a degree but it is in many ways the less interesting (and less important) part of what “the economy” is.
Instead, we should think of it as a preference aggregator. From the perspective of extraction of raw resources, we have a few fairly simple rules.
Some resources are genuinely scarce, such as oil and precious metals, and not only is extracting them hard but their deposits will not last forever, in some pure sense of what earth as a ball of rock in space can eventually provide.
Some resources seem scarce but really aren’t, like food. Arable land is limited but methods of growing more food with less water and land use do exist, and given that agriculture is a single-digit percentage of GDP, if we wanted to grow more food, we just could. The same is true of a lot of other things like most building materials, iron, cement, wood, many other consumer goods, and, yes, even housing.
Substitutes exist. There’s always talk of if scientific progress can develop new substitutes for some resource we use that we are worried about using (like cobalt for batteries or neodymium for magnets) but the issue is much less if the science can be done versus if there is economic incentive (preference) to find it (or just use something that’s marginally more expensive). Substitutes aren’t the only way either, designs can be made that just don’t incorporate certain materials, if only the economy wanted it to be that way.
Yes I know I’m anthropomorphizing the economy but bear with me, the point I’m trying to make is that people buy stuff and they buy what they need and thereafter what they want. What they want then influences what the economy produces and if you want a healthy economy you have to give people the power (money) to buy what they want and I know this all just demand-side economics but again, with me please, bear.
When we say we want “growth” we want more of those raw resources and we want those raw resources to be turned into cool useful stuff and we want that to be done in an efficient way in which we are not chucking silicon into the ocean (cough cough or data centers where they won’t get used cough). People go on and on about how to incentivize new businesses and ensure high employment and deregulation and subsidies but there is another perspective that I’ve already written about on this blog and it’s so good I’ll just copy it:
Imagine a world in which all work is automated. There’s still money, people, and stuff to be bought. There are companies, but they are AI run, with robotic workers and legal-entity owners (not owned by people). This isn’t the same idea as a post-scarcity economy, there are still limits on the amount of stuff that can be made and there are equilibriums to be found in balancing how much food we should grow vs how many yachts we should build. So, we still want an economy in this world, we want people to express what stuff they want, and then they buy that stuff and the free market makes more of that stuff if demand is high. The usual. Here’s the question: Where do the people get the money to buy things with?
“But we don’t live in that world!” I hear you cry. Indeed, even if AI could do every job no doubt some humans, lavishly wealthy and/or powerful, would be at the head of it all (private or government, someone is in charge1). Still, we are heading in that direction and ultimately that is a good thing. People, by and large, don’t like working. Some work is very rewarding, and I do not doubt that many jobs would still get done by people who love them, even for no pay, if their other needs and wants were met. Many would still work less though, and some not at all, or do things that we would not today classify as “work”. With that in mind and with a historical perspective the measure of human progress and prosperity is largely a story of receiving more stuff for having done less work, and we can do that. More infrastructure can be built, more advanced farms, industries, cities, for a population that probably will be under control in the coming decades/centuries.2
The problem we need to solve then is a simple one: Where do the people get the money to buy things with? We discard the notion that the economy is some sort of rewards system and it becomes what it truly should be, a preference aggregator. Then, we just need to give people money somehow, let them buy stuff, and get some of that money back from the sellers of that stuff so we can give it to people again in one nice big circle. To give people money, we want a universal basic income (UBI). This kind of policy has been gaining popularity recently and it is so simple it hardly needs any explanation. You get money for existing. That’s it. Maybe you get some more if you have some particular need, like a disability, but you could also just have universal healthcare for that. Maybe you can also still work for a job for someone or some entity, that doesn’t sound so bad, I see no reason to make it illegal. To get money out of the “rest” of the economy, we need some sort of tax. We can’t just take all of a company’s money or profits since our industries will never be static, they’ll have to expand, shrink, make bets using extra cash and have a cushion if those bets are wrong. At some point though, in a fully automated world, it has to get back into the hands of people. If our legal entity constructions just accumulate wealth, the system will break just as badly as it is doing right now. Last time I wrote about this I leaned heavily on VAT as the solution, but to be honest I leave that problem to policy people that are smarter than me.
What I can’t get over is how obvious all of this seems to me these days. Everyone thinks of “the economy” as something else, something where work is an integral part and you get paid for good work. Of course, we still need good ideas, and so encouraging that through “reward” is a good thing, but when someone like Musk can say “cars, but they drive themselves” or “rockets, but they land themselves” and get a bajillion dollars I just think we are leaning way too heavily into the “rewards” side and are just forgetting that people need to buy stuff and they need money to buy that stuff and we are trying to automate away everything and that is not a bad idea per se but holy shit we need to think about how that society needs to be structured really really right now.
Perhaps some decentralized system is possible but that does feel hard to even envision. I do encourage anyone to try though. ↩︎
I know I’m glossing over a lot of things here. The world may literally end because of war or climate change or societal collapse or whatever, but in terms of “can we build a society that gives people lots of stuff they want”, the argument I’m making is that it’s very possible but we need to rethink our economies. ↩︎
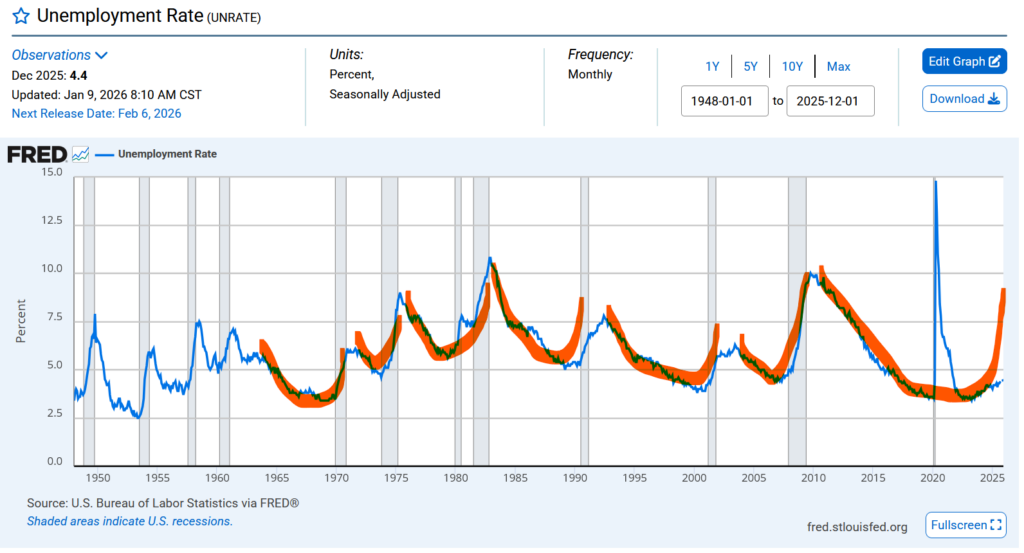
Last year I predicted there would be a significant (2008+) economic crash that year. The year is now 2026 and I was wrong. At the time my main argument was essentially this:
The unemployment rate just follows these smooth curves, covid was an exception, and it was due to jump again. Not very scientific I know. There was another important graph of course:
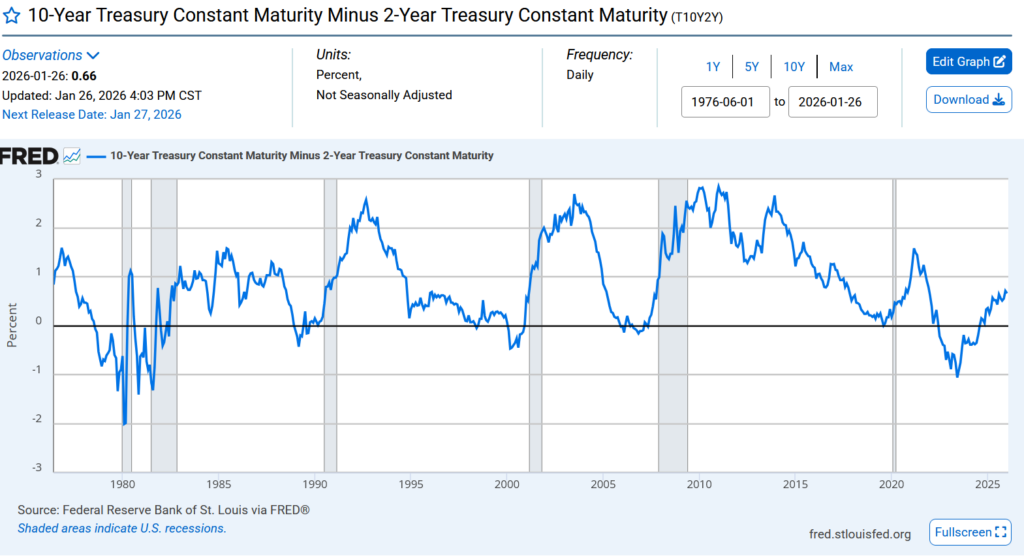
Where classically an inverted yield curve has been a recession predictor. This one is a little more involved, but essentially the US government borrows money and normally what makes sense is that the government needs to pay more money every year in interest if it wants to borrow the money for longer. If, for some reason, the market says “no actually we will take a lower fee if you take our money for longer” that is an inverted yield curve, and here that is shown by the difference between the interest on a 10 year loan and a 2 year loan being negative. Why this would predict market crashes is a complex topic and I encourage you to read around about it. It isn’t perfect of course, and one “feature” is that it isn’t “wrong” yet, at least unless we don’t get a crash within the next few years.
But come on.
It surely will be this year.
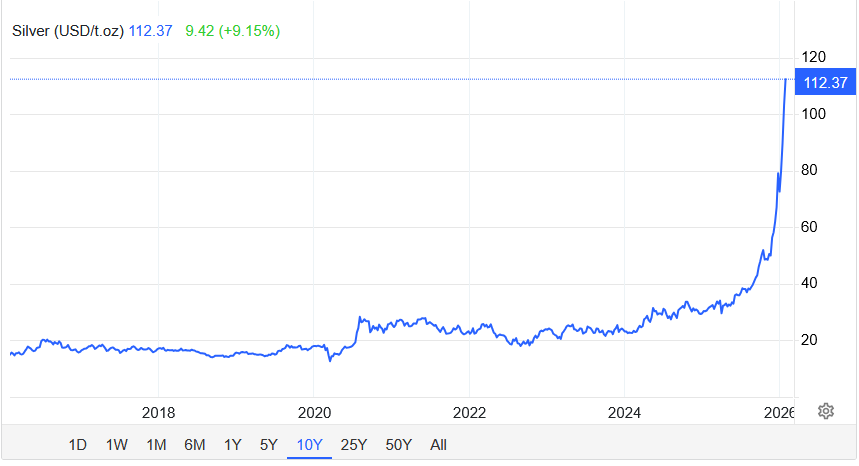
Here’s the current price of silver. Gold looks kinda similar (but smoother, I chose silver because it looks dramatic, but maybe it got you to read this further so that’s a win in my book). People buy precious metals when they might be worried about the value of fiat currencies, like, I don’t know, the dollar. Are people worried about the dollar?
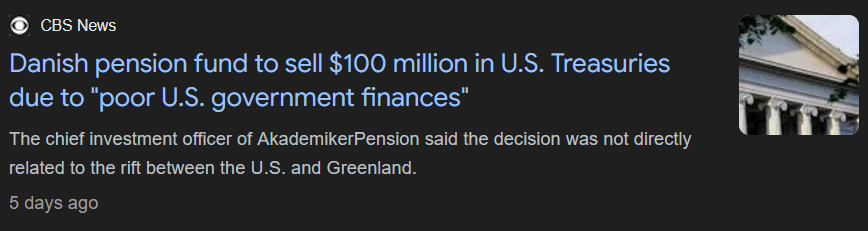
To be honest I’m glad we are the ones getting out of that market first. Why might people be worried about the dollar?
Eh, I don’t know, there are lots of possible reasons and maybe you can think of some. The actual point is this:
US government debt has been a worry for a while. That worry doesn’t matter so long as people have faith in it, but it does matter insofar as it makes a possible debt crisis deeper. The bigger they are, the harder they fall.
There are one or more bubbles in the stock market. Almost everyone agrees that AI is a bubble. It funds itself in a circular fashion, and capex cannot be recovered with profits any time soon, even with optimistic outlooks. Other stocks may also be well overvalued, with sky high PEs and nonsensical business models (meme stocks are just the worst offenders)
It feels as though all we need is a spark. And yet, many sparks seem to have come and gone. Big market moves, in stocks or yields, that have recovered. Tariff and invasion threats, protests, you name it, they might move the needle but it always seems to move back. So, perhaps we won? Perhaps we built our markets so stable that they are these days impervious? That sounds silly on its face, and the two reasons I’d actually give are:
Markets are just slower moving than ever before, big players just like to sit on their big piles of money, and it’s much easier to just assume the needle will go back and then everyone pats you on the back when it does. No client likes a skittish fund manager that ends up always being wrong
This is the 11th time that tariffs have happened, and it just isn’t surprising anymore.
Which is to say that no individual decision maker wants to be the first mover, so the market does not move.
A year ago there were a few signs. Right now, it feels like everything is primed to blow. Is that new? Do I always just feel that way? Am I just a broken clock that’s going to be right today? Maybe, but I damn well intend to be right at some point.
(This post is about how I created a discord bot that calculates a wordle leaderboard from messages posted by the official NYT wordle discord bot. A chunk of the post is just explaining how the rankings are calculated, since sometimes it produces some interesting results. If you just want the bot, the link is here)
A few months ago The New York Times introduced a discord bot where you can play Wordle. This is, frankly, a great idea. The initial success of wordle was, in my opinion, because it was naturally something you would talk about with friends, and then those friends would try it if the hadn’t heard of it. This was because there was only one wordle a day, “have you done todays wordle?” is something I’ve found myself saying both to those who I know play it and those who may not have ever heard of it. This isn’t unique to wordle, like, there are daily-only crosswords, but what usually happens when such a game goes online is that it allows you to play again and again and again. “Here’s 1000 different crosswords! With themes and difficulty levels! Please stay on our site and see all our beautiful ads!”. So wordle was new, fun, short (faster than Sudoku or a crossword), and had a natural transmission method. If you still doubt the popularity of wordle, just google it and look around on the results page.
So creating a discord bot was an obviously good idea. Now you could play the game “with” your friends. You implicitly remind eachother to play from the message pings of others playing, and if you miss those, you’ll probably wake up to an @mention from the wordle bot, as it summarises yesterday’s scores and presents a winner, just in time for you to play today’s wordle. I found myself playing the wordle in bed in the mornings, just to wake myself up.
What it didn’t really have was any good way to compare yourself to others. Sure, you could see each day’s results, but nothing else. Perhaps the most obvious metric is average score, just take every days score, 1-6, sum them up, and divide by the number of days. Sadly, this isn’t available with the NYT discord bot??? Instead, I’m greeted with:
So you’re telling me that now that I’ve played a few dozen days, and am actually interested in my average, you want me to play another few dozen on your website (because ofc the data isn’t transferrable that would be too convenient) to get a score, and now I can’t play it on discord with my friends anymore??
Nah. Playing on discord is great and I want to keep doing that. I can solve this problem for them, all the data is right there. Each day, there’s that summary I mentioned. It looks like this:
At first, I definitely did not use discord chat exporter because that would be against discord’s ToS. No, I of course manually copy pasted all those messages into a nice json file that I could then read in python and calculate some stats. Yep, definitely. Anyways, I used this data to do all the further developments of the wordle leaderboard, and then later I wrapped it all up in a discord bot which I’ve shared the link to at the bottom of this post. But imagine this is all for the bot since it all works the same way.
Here’s the first problem with just using average scores to calculate a leaderboard:
1. Some people don’t play much
Ok here’s an example leaderboard:
@busyperson: 3 games, 3.66 average
@poorsoul: 115 games, 4.03 average
Well ok you got a 3 one time and two 4s, does that really mean you deserve the top spot? We could just filter out people with, idk, less than 5 games, but “you had a lucky streak” is going to feel like a problem for a while. So what to do? The problem we face is we don’t have enough data. Maybe @busyperson really is that good, maybe they got lucky, 3 games is just not enough to know. Reasonably, we can manage this uncertainty by estimating how well the average player performs, and making it so that people with fewer games are somehow dragged towards this average. This is called shrinkage, and we can apply it to our results. An added bonus is this is symmetrical, so some unlucky person who only played three games and got only 5s will have their score improved.
Let’s say that the average average score is 4, and that the variance of the average player scores is 0.1. Then, we would calculate the @busyperson’s adjusted score like this
Essentially we calculate how much of the data we use from the players actual average, and how much we just use the population average. This drags that player towards the average of 4.
2. “I didn’t finish the wordle”
So, what happens if you don’t manage to get the wordle word in six guesses? Well, according to the wordle bot, you get X/6:
So, what happens if you start playing the wordle, make a couple guesses, and then decide you don’t want to finish it?
You also get X/6
This is a problem. It would make sense that for people who use up all six guesses and still don’t get the answer, you might give them a score of 7, dragging up their average significantly. But for those that just decided to quit, should we really penalise them so harshly? If we just ignore them, then there is a strategy whereby if you’ve used say, 4 guesses, and not succeeded, you could just not finish the game that day to “protect” your average. I couldn’t come up with a good answer for this. so the bot supports both treating X as 7 or ignoring those games entirely.
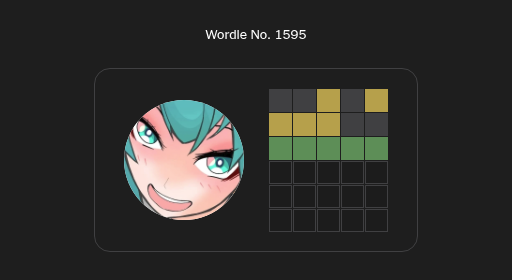
3. Some days are harder than others
Ever had a wordle game like this?
It’s one where even if you find quite a few correct letters, there’s still so many possibilities that finding the correct one is really hard. There are some strategies to deal with this, like recognizing that the number of options is high and using a word that isn’t a possible answer, but eliminates a lot of other possibilities. Even so, it’s fair to say that some days are more difficult than others. what if, by luck (or observing other players results as they play!), some player avoids those hard days? Can we adjust for that?
This fix can be done quite easily. If we know the average score overall, then for a given day, if most people did worse than that, it’s a hard day, and if most did better, it’s an easy day. We can take the average score for the day, and subtract the overall average to get an adjustment number we can apply to every players score. If everyone plays every day, this does not do anything to the ranking, but if you skip hard days, everyone else’s score might be a bit better than yours.
Ideally for this to work well, you want a lot of players. If there are only two players on a day then the “day difficulty” probably isn’t very accurate. But it’s still an adjustment you might want to have so I included it in the bot.
4. You can’t trust timestamps
So how does the bot actually work? What it does is scan all the messages in a channel, find all the summary messages, and use the results to calculate a leaderboard. Thing is, it’s nice if we can get results from more than one channel (for example, if your server owner got so annoyed with you playing wordle every day in general and created a dedicated channel for it (this has happened multiple times in servers I’m in)). If you load and use results from multiple channels, you need to not duplicate results you’ve already seen and combine the summaries that are unique into one full dataset of results. For uniqueness you need some ID, and I thought timestamp date would be a good one. It’s not. Of course timestamps would fail me:
I don’t know what schedule the wordle bot uses for these summaries, maybe I could work it out, but trying to fudge it while still using timestamps seemed like hell. So I chose a different hell. Here’s an example of the images that come with each summary:
Enhance
Before you ask, yes, adding OCR (Optical Character Recognition) did slow down the process of scanning messages significantly. But it works reliably and gives me nice unique IDs I can use for all results, regardless of channel or server or timestamp, that can be saved to the DB.
5. What if we use Elo Ratings
So far we’ve been calculating an average score and making some adjustments to that to create a leaderboard. But this isn’t the only way. If you’ve read some of this blog you should be aware of my fondness for Elo ratings, which you might know best as the chess rating system. Could we use that here?
Of course we can what kind of question is that!
Every summary, we pretend it’s actually n(n-1)/2 pairwise games where n is the number of players that day. Your performance is compared to everyone else that day and your Elo is updated for each comparison. How does it work though?
Let’s say just two people play on a given day, and one gets 3/6 and the other gets 5/6. We could say person A wins, since they got a better score, and then the Elo update equation looks like this:
The players new rating is equal to their current one, plus K times the difference between their score and their expected score. K is just a value you can set. It’s sometimes 32 for e.g. chess, it defaults to 2 for the bot. The expected score E_A is calculated based on the two players ratings, you can see more details here, but essentially if your score was good (e.g 1), and your expected score was 0.5 (let’s say you have the same rating as the other player), then your rating will go up by K/2. it’s also symmetrical, so the other players rating will go down by K/2.
Here I said that we would use a score of 1 for a “win”, but the Elo update equation allows us to actually do better. Here, S_A is the score the player got in the game, (1 – the other players score) and of course we can use 1 for a win and 0 for a loss and 0.5 for a draw. However, for any pair of results the difference could range from 5 (or 6 if using X is seven) to -5 (or -6). If we could linearly space these, so 5 => 1, -5 => 0, 0 => 0.5, and then everything in between, we could have more granular information for the Elo update. This means if you get 2/6 and someone gets 6/6, you will “take” much more of their rating than if you get 3/6 and they get 4/6.
OK great, so each day you iteratively update the Elo’s and bam, you get a nice score. It naturally benefits players who play a lot (or put another way, doesn’t allow lucky players to get to the top in a couple games!), because if you want a high elo you will have to work your way up, just like in chess or other competitive ranked games. It also handles day difficulty nicely, because if everyone did poorly (or well) on a day, your ratings actually won’t change much, it’s only the relative difference between players that causes a rating change.
So we’ve found the best method yeah?
6. The MAP Elo rating
There’s one slight problem with the iterated Elo method and that is that it favors “newer” data. This isn’t actually a problem because people get better over time and we probably want their Elo to reflect their current skill, not necessarily the full average. Some people have a rough start, should we really penalize them for that?
Yes
……
Well ok, maybe not, but let’s at least consider one more possible way of creating this leaderboard.
Consider that we would like to use Elo ratings, but we don’t want to update it each game. We want an algorithm that considers all your results at the same time (removing the recency effect). To do this we recognise that when we compare two elo ratings, we get that estimated score E_A. What if we could work out all the elo ratings so that the difference between all the E_As and the actual results were as small as possible?
We totally can and this is called the Maximal Likelihood Estimate (MLE). i.e. we are maximising the likelhood that the estimated score E_A is equal to the actual results that person A got. There are algorithms we can use that, after certain number of rounds of calculation, will converge to a set of Elos for all players that minimizes the result/expected result difference.
There’s just one problem, what if someone plays once, against only one other person that day, and gets a perfect score? This is unlikely in this case of wordle, but it could happen, and essentially the MLE Elo rating for that lucky individual becomes infinity. I wrote about this problem in more detail in my post on ranking people with LLMs.
Look, we know nobody is infinitely good at anything, even the best players sometimes lose. If only there was some way to encode this prior knowledge about players into our algorithm for calculating their Elos with global result data…
The MAP (Maximum a Posteriori) estimate is a way to take a prior estimate of the distribution of player Elos and update them based on global result data. It’s not that different to the idea or the MLE, but it’s a tad more mathematically involved. You can read about it here, specifically equation 27.
Why use this? well, if you want to consider all data equally, and you have a lot of it, it can avoid problems where, say, you’ve had an unlucky streak of games the past 5 days. You can sortof achieve this in the iterated method by lowering K (making each step smaller), but the purest way is the MAP Elo.
How does the bot work though?
All of these methods and ideas I ended up including in the discord bot which you can add to your server with the link here. Because of the somewhat dirty method of collecting data it uses, it needs both the read message content and server members “privileged” intents (the latter I need because for some reason quite often the wordle bots @user links don’t convert properly to user IDs (they aren’t highlighted), I then use server members to find the actual names of users and match the failed @s to IDs (IFF a user hasn’t previously used a nickname, in which case we are out of luck 🙁 ))
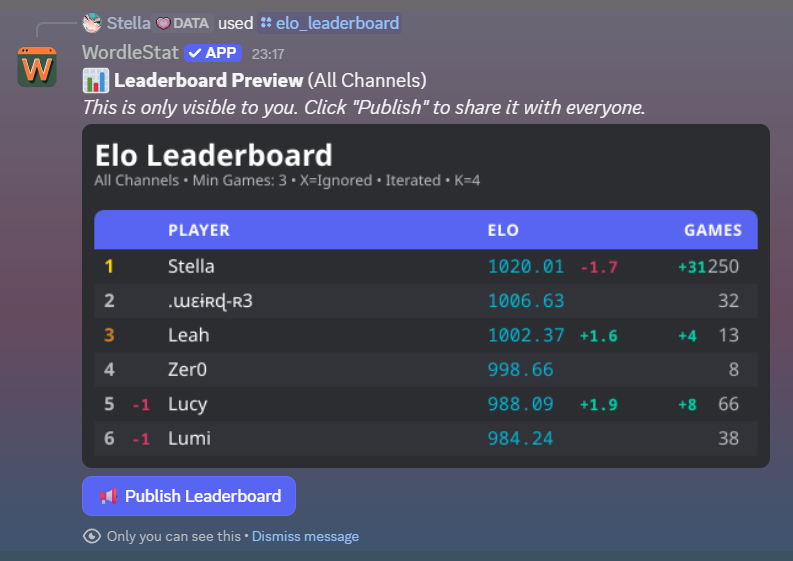
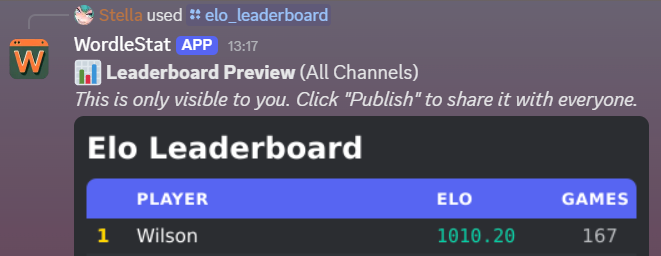
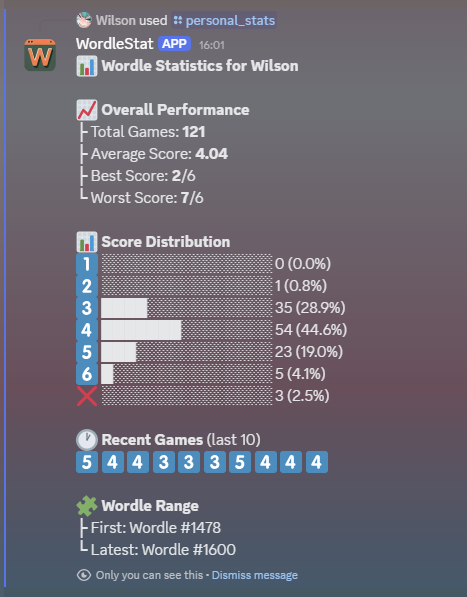
From there, you can use /sync to read channel messages, /elo_leaderboard or /average_leaderboard to generate a leaderboard, with all the settings I’ve talked about, and /personal_stats to see, well, personal stats. It looks like this:
The bot itself uses express, running on node in a docker container with a postgres db to store results.
Email me at wilson@wilsoniumite.com if you need any help!
Final thoughts
As I was working on this I was reminded of that quote “there are three kinds of lies: lies, damned lies, and statistics”. Each leaderboard, with different methods or settings, looks different. People can jump half a dozen places based on the settings used. None is “clearly” better than the other, and the underlying wordle game is of course easy to cheat at anyways. But nonetheless, I thought this was fun and the leaderboards are definitely nice when oneself is on the top :D.
When I really got into writing code (big projects, or for work), I really started using libraries. For so many problems, there was already a library that would help me with it. From doing maths fast with numpy to padding strings with left-pad, there was almost always a library that could help. Even now half the time you want to integrate your app with some other application it ships its API as a small library of useful functions. As much as I do like writing code to solve difficult problems, the project manager in my head is telling me “don’t reinvent the wheel”, so naturally I use a lot of libraries.
My favorite libraries were always the ones that were nice to me. They would let me pass in data in lots of ways and specify tons of options.
They would check lots of things for me often, and early in their call stack so that when I inevitably did something wrong, the error message could contain lots of contextual information. Sometimes they’d even tell me what code to run!
I was taking all this in. And of course, I would also learn how all this is best done by reading the libraries’ code. I might read it to solve a particularly tricky bug, to get around some poor documentation, or perhaps just out of curiosity. There in the open source I could see just how library code looks, and it looks a certain way:
(This is the first bit of case handling in tqdm, a library that creates a little progress bar for your for loops.) Look at that! Check everything! Some if statements here, some type conversions there, exception handling, default values and assumptions galore. Don’t get me wrong, this is good code! Never have I been upset with the behavior of tqdm, it’s great. It works, it allows me to override what I need to, it gracefully handles what details it cannot work out itself.
So what’s a young coder such as myself to do? All these libraries I love have shown me the path forward. Sure, it’s a little extra work, but we do that work now to save us time in the future, no? Of the little other code I’m exposed to, it’s all bad and hard to read and so why not take inspiration from what is, to the untrained eye, the only way to write good stuff? We’re not building exactly the same type of programs as a library, but I’m still writing stuff that other devs will use and that’s kind of like a library. The choice seems obvious.1
Libraries have an unfair advantage in this clash of perceptions though. Two of them, in fact.
They have hundreds if not thousands of users. These users will test edge cases for you, finding bugs faster. The ones you end up using in particular are popular just because they survived when other competing libraries didn’t. As such, it almost doesn’t matter how hard the library was to write or even maintain, the quality of the product is what won out.
They are overrepresented. How many of the lines of code in the world are in libraries, compared to how much of the code you have seen or interact with? This is a selection bias, most similar to the friendship paradox. They have many users, so many people have interacted with more library codebases than simple chance would allow.
It’s not just me. Over and over I see people leave university and their small script projects and start asking “what does real good code look like” and this is the direction they go.
But let’s say instead you’ve read this and think, OK, fine, most code isn’t like a library. But shouldn’t it still aspire to the same standard? It’s GOOD CODE!
YAGNI and YAGWI
The obvious first criticism is You Aren’t Gonna Need it (YAGNI). Those libraries are like that because disparate users really do have different use cases and even a small convenience can matter a lot if it affects many people. A few dozen people in your team including yourself just aren’t as important. Once your code is in production maybe that assertion you made really doesn’t serve much of a purpose. Sure, down the line it will probably need to be maintained and that assertion might make it easier to catch some edge case, but it’s not as likely as you think.
But there’s another reason: You Aren’t Gonna Want it. This means that writing library code may lead to a codebase as a whole that is actually worse, harder to maintain. What we are partially talking about here is the robustness principle: “be conservative in what you do, be liberal in what you accept from others”. Specifically, about being liberal in what you accept. People have already written about how it isn’t always a good idea, but the gist of it is that when you allow for lots of different options and inputs, people are going to use them, and then you need to support them all, and that’s more effort than it is worth. If one of your colleagues asks “hey can you have the code take two lists instead of a dict I can’t be bothered to make it a dict” just say no. Their convenience is not worth it, at least not yet. Sometimes, sure, you’ve gotten the same unreadable error for the 20th time? Catch it earlier and make it readable. But the key is to build things when you truly need them. One day, if your code really solves some hard problem in a beautiful way, you can turn it into an actual library and distribute it to the world! By then, I assume you know what you are doing anyway.
So what does good code look like?
That’s pretty hard to answer. Lots of things matter for good code, this post is more about what not to do. But the core idea that “not writing library code” points to is: simplicity is valuable. We already mentioned YAGNI as a general concept but there are more good blog posts out there of things you can think about.
Let’s get more abstract
I want to put code on a spectrum, that ranges from “active” to “inactive”. Inactive isn’t the best name (sorry), it’s not meant to mean code that isn’t running or in use, it’s just not active.
There are two ways code can be “active”:
It’s being heavily maintained. New features, significant bug fixes, refactoring and the like. This is what we might call “active development”, it’s what we think about most naturally.
It’s regularly being called in a lot of new places. The code itself may not be changing much, but many developers are interacting with it for the first time, putting it through its paces regularly.
(There is arguably a third way, where users are putting code through its paces as they use an app in myriad ways, but for the purposes of this discussion it isn’t relevant)
The more active your code is, the more it will benefit from looking like library code. public facing actual library code is extremely active.
In general, code transitions over time from active to inactive. Unless you are actually writing a library, at first the code itself will no longer be under active development, and then later the code that uses your code won’t be under active development. At that point it begins to become inactive. Given that natural transition from active to inactive, in some sense, it might be optimal for code to start out as library code and slowly transition to being simple, static, no error checking and no frills code. Intuitively this makes sense: while people are developing on your code, give them nice error messages if they use your thing wrong. As soon as the program at large is “done” (insofar as that is possible for any code, another topic) then that input checking code doesn’t have as much value, perhaps less value than its cognitive weight. Actually doing this isn’t realistic though. We’re going to write it one way and that’s going to stay, or even go in the opposite direction as it accrues new frills and features. Oh well.
I didn’t have much more to add to that, it was just a final thought. Thanks for reading this, I hope it resonated a bit or at least was somewhat interesting.
There is also something to be said of straight complexity. Libraries are hard to read, because the do tend to be big. Lots of code, complex architectures and structures, the works. But If they are doing it, and they are popular and have great programmers maintaining them, why shouldn’t we all do the same? ↩︎
These are all garbage tier emotions. I never want to feel them and I don’t want people around me to feel them either.
What purpose do they serve??? Evolutionarily, I guess there are things we shouldn’t like and therefore avoid. “Opening this coconut thing is frustrating, stop doing it, you’re wasting your time” or whatever. “That person betrayed you and or your tribe, you should punish them the next chance you get, which should disincentivize people from being bad”. Sure. Except like, are these feelings really that useful anymore? In the modern age? Do we need to subject ourselves to an experience that shortens our lifespans, creates enemies, makes us give up and be miserable?
Nah. They suck. Nobody can convince me they’re worth it. Sure some extreme cases may exist but come on, I could do without them most of the time. 90% of the damn time I’m not even in a position to turn anger or whatever else into anything remotely useful. Wouldn’t it be genuinely wonderful if kind, good, happy content generated the most engagement? Maybe then these sucky emotions wouldn’t be magnified 100 times by all the rage bait we put on the internet?
“Oh but Wilson you sure do sound angry now, isn’t that a bit hypocritical huh?”. It’s manufactured. Irony. I’m playing it up to prove a point to myself and maybe it sounds funnier that way.
But also have you considered maybe I feel like resolving Poppers paradox of tolerance?? Being angry about being angry is the only thing I want to be angry about? Yeah, that makes me feel better about myself.
Last year I created a fun little experiment where I asked a bunch of LLMs to rank 97 hackernews users using their comment history based on whether they would be good candidates for the role of “software engineer at google”. (yes yes, seems silly I know, you can read part 1 and part 2 but they are long).
In it, I had a persistent problem of bias. I had arranged the comments in an interleaved fashion like this:
Person one: What makes you think that? Person two: When I was a lad I remember stories of when... Person one: Great post! I particularly like the things and stuff ...
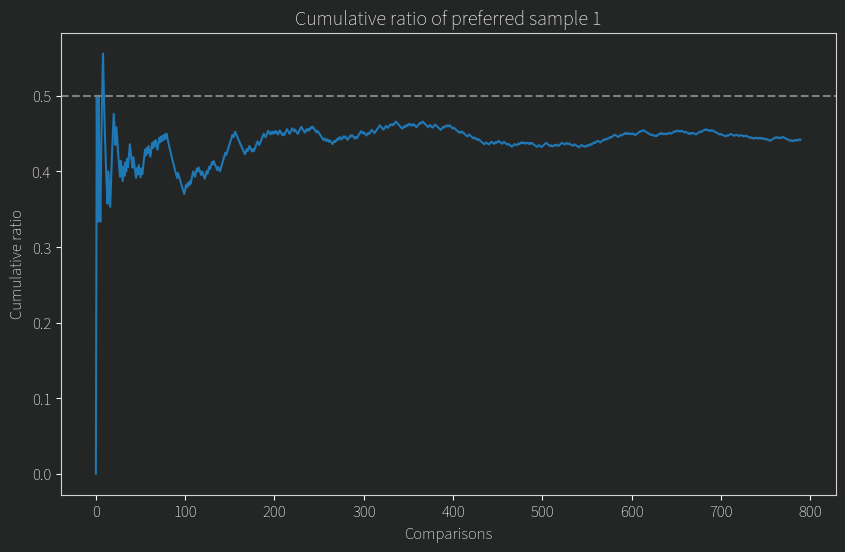
The users aren’t responding to each other, that’s just how I arranged the comments in the prompt. I didn’t give the model the users names for obvious reasons. Then the model says who it prefers, and using many pairwise comparisons we can come up with a ranking (similar to the way chess rankings work). However, I noticed an odd bias. Even though which user was named “Person one” in the prompt was random, the model still preferred whoever got the name “Person one” slightly more often than not (or for some models, preferred “Person Two”). This is dumb. There is no reason to prefer them for being called “Person One”. It should be considering things like, would they be a good colleague etc. In the end, I evaluated all my models across all 8000 games each played, including some dummy models like one that always chooses “Person One” and one that alphabetically ranks the users. I then compared the ratio of “Person One” as it converged across the games played. Here’s what that looks like:
The models should hover around that white dashed line. But they don’t. This isn’t just bad luck. The two tailed p-value is vanishingly small after 8000 games for this sort of result (except for the alphabetical model, understandably).
This was very frustrating and I tried a number things to reduce the bias (messing around with prompt formulation etc), but couldn’t get it much better. No matter. I pressed on and found interesting results anyways and wrote about them. The bias wasn’t that bad and, since the order was randomized, it becomes random error, diluted by a larger and larger number of games.
That bring us to today and as-yet unfinished work where I’m asking people (real ones, I promise) to rank TTS voices based on attractiveness.
What better way to do ranking than pairwise comparisons, I thought?
Guess what.
Go on. Guess.
Surprising? Ok, maybe not in retrospect. So what if humans who can’t distinguish two TTS voices have a bias toward the sample presented to them on the right hand side of the screen. Indeed, “preferring stuff on the right hand side” has even been studied [1].
And, I’ll admit, the TTS voices do sometimes sound pretty similar.
Still, to me, this is a little bit cathartic because a) I was quite frustrated by the LLM bias and b) some commentators also said this invalidates the results, which hurt a little. Of course, this bias is still bad, and highlights the need to have things like large sample sizes and randomization. I won’t go much further and get too abstract here, but if there’s another, broader takeaway you could have, it’s that a lot of the safeguards and policy we have to manage humans own unreliability may serve us well in managing the unreliability of AI systems too. Maybe. We’ll have to see.
The recent release of DeepSeek-R1 made a pretty big splash, breaking into the mainstream news cycle in a way that the steady model releases we’ve had for a couple years now did not do. The main focuses of these stories were that 1. it was cheap and 2. it was chinese, forcing the market to reconsider some of it’s sky-high valuations of certain tech stocks. However, there are other interesting things to consider.
What I was impressed by are the different ideas tested in the R1 paper. Epoch AI has an extremely good writeup that made it far more digestible for me, noting that there were a number of architectural improvements they’ve contributed (over multiple papers, not just R1). Many of these improvements are “intuitive in hindsight”, but I want to talk about one of the methods they use in particular. DeepSeek-R1 was trained by using a reinforcement learning algorithm which started with their classic style model, DeepSeek-V3. They gave it math and coding problems with exact solutions, encouraged it a tiny bit to reason (essentially to make sure it used the [think] and [/think] tokens), and then gave it a reward when it got the right answer. As one hackernews commentator put it “The real thing that surprises me (as a layman trying to get up to speed on this stuff) is that there’s no “trick” to it. It really just does seem to be a textbook application of RL to LLMs.”
One of the key challenges with this is having those exact solutions. Largely, we can only choose problems that have solutions you can compare against or check rigorously. For maths, it might be a number. For code, it may need to pass a runtime test. This is good but you can imagine a huge number of reasoning tasks (perhaps the most interesting ones) that don’t have clear answers. How best to run a particular business? What architecture, language and patterns should we use for a software project? What is the path forward for reasoning in LLMs? These are all questions you could ask deepseek, but how would you know what reward to give it? Well, what if we got deepseek to do it. Ask it, “How good is this answer?”
You can’t ask a model to train itself!
In the DeepSeek-R1 paper they write “We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline” Which is, indeed, a challenge. We’ve talked a lot about how slop proliferating on the internet could lead to a poisoning of LLM training data. We’ve seen how models, even if they know they are wrong, can end up going in circles trying correct themselves. What could the models possibly teach themselves that which they don’t already know? Here are the two key challenges with this idea.
The model can’t teach itself new facts. If it doesn’t know something, judging its own reasoning process isn’t going to magically introduce those facts. It also can’t (in a simple implementation) test ideas to produce new facts.
The model might collapse or reward hack. This might mean that if the reward step begins to reward something meaningless like niceness, the model will just become nicer, not smarter.
The first is not actually that big of a deal. DeepSeeks own research shows that most of the necessary facts are already present in the model, and what it needed was a training process to recall, consider, and reason around the facts it already knows.
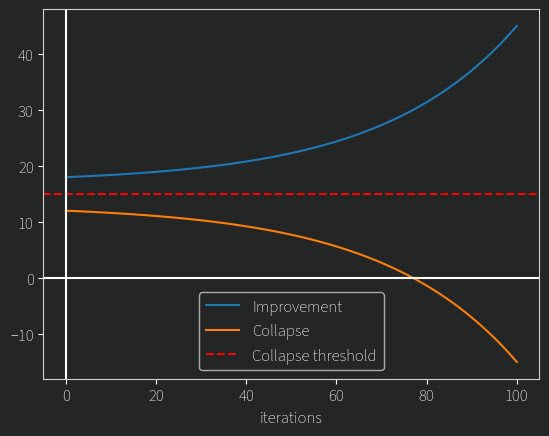
The second challenge is much more interesting. If you start with a somewhat competent model, you might expect that it would view a “nice” but poorly reasoned answer poorly, since it has low informational content. One would hope that this would only improve the scrutiny the model would give to answers over time. To reward hack, the model would have to engage in poor reasoning, since in the question we asked, we “wanted” a sincere answer. We as humans can look at two chains of thought and roughly say which contains substantively better reasoning. If the model can do the same, it might just be able to continue getting better at this. What I’m trying to get at is that there may be a “collapse threshold”
If the model starts out competent enough, it may be able to over time RL its way to being even better at reasoning, on basically any problem we give it.
Another important component that may make this work better is inference time compute. OpenAIs o3 has different compute levels corresponding to how much compute the model is given, essentially how long it is allowed to think for. You reasonably could give the reward step more compute than the problem step, on the basis that then you are trying to distill better reasoning into fewer reasoning tokens. This is very similar in idea to distillation of big models into smaller ones, but instead it is distilling long inference compute into short inference compute.
This will most likely reach some diminishing returns, unlike the naive graph I have, but we could augment the process with the ability to test. Lots of reasoning steps, both in solving and reward stages, could be “tested”, in that the model may want to search something or run some code. That may prove prohibitively slow, I’m not sure, but that might be mitigated by just asking the model to only reward tests that are necessary, and then both the problem and reward stages should end up learning to be lean in their usage of tests. It also still hinges on the model having a good intuition of what necessary searches means.
I’ve no idea if any of this actually works, I’ve only trained a few little toy models myself, and I’ve seen firsthand how they can collapse in all sorts of ways, but I do think ideas like this are worth trying. These are the ideas that are outside the reach of most research because they are premised on the fact that we can iterate on a huge and already very capable model. If it does work though, I do think it could lead to some significant improvements.
(This was originally written as an assignment for my masters studies, I thought it might be interesting, read at your own risk etc.)
Are we offsetting or accelerating the green transition?
Prices for green energy are coming down [1] and given an assumption that this trend will continue, the price of reliable green energy may fall below that of closed cycle gas generation (currently one of the cheapest options [2]). However, the question remains that if demand added from new AI generation continues to pressure electricity prices upwards, then the marginal advantage of green versus conventional energy may remain an issue. That’s to say, even if it is profitable to build a new solar plant and all the solar energy companies industries are booming, if it is still profitable to build a new gas turbine plant then the gas turbine plant manufacturers will keep doing that too. In this sense even if AI energy demand accelerates the construction of new green power, it offsets the green transition.
I personally believe that a combination of government action, corporate goodwill (yes, it does exist) and market forces will lead to satisfactory progress, but none of this is set in stone and we must carefully monitor it.
The way of the car or the plane?
How will our models look in future, and how will they be used? Will they go the way of the plane, big, expensive, built by one of two companies and where you rent a seat and get where you want to go. Or will they be more like cars, small, personalizable, affordable, ubiquitous? This question matters. For all of the faults of air travel, the incentive structure of large, expensive planes encourages extreme fuel efficiency for cost saving reasons. From 2002 to 2018, aircraft fuel efficiency rose 71% [3], compared with 29% for ground vehicles over the same period [4]. One could attribute this to the fact that the auto industry is more mature, but the general mechanism whereby economies of scale encourage greater efficiency is well known.
This means that if a small number of efficient, cloud based AI vendors can optimize their models to provide the vast majority of GenAI needs ends up being the norm, we may be better off energy-wise than if everyone has personal GenAI being finetuned constantly and running on dedicated hardware. Likely there will be a balance of both these possibilities, but it’s worth noting that currently the former is the only relevant case.
Will “agents” make this much, much worse?
Right now if you want to use AI there is usually a human involved. This means that you head over to ChatGPT and ask it a question, or maybe you receive an email that an LLM summarises. Perhaps an artist might use photoshop’s AI inpainting tools. Essentially, for most current inference tasks, GenAI is done under supervision. Here, humans short attention spans actually works in our favor for once. In an effort to improve inference speeds (and lower cost) model makers have developed new methods, most notably quantization, to do more with less. This incentive aligns with reducing energy consumption and is not only attributable to improving hardware [5]. However, looking forward this may not be the case.
“AI Agents” is a poorly defined term but for the purposes of this discussion I will be looking at the common attribute that they involve less or even no human “presence”. In essence they are allowed to operate in the background. Devin is a “software engineer” AI system [6] which you can only communicate with on slack. You ask it to do something and it goes off on its own, sometimes for a period of days, to try and achieve what you asked. No doubt it would be nicer for this process to be faster, but the pressure to optimize this is missing a component of human impatience.
Further still, if we give new CoT reasoning models like openai’s o3 more compute, they tend to give better answers [7]. If you are anyways running these models in the background, why not give them the “best” chance of coming up with a good answer? Given that sometimes these agents get stuck in loops [6], would we not want to do that since an agent getting into an action loop is also bad from both a cost and energy use perspective?
In summary, agents may bring about a significant change in what is prioritized in model development, and to my mind it will not be in favor of energy efficiency. That could couple with changes in how the average model is used, with more personalized finetuning negating the oft-used argument that “you only need to train them once”. This new energy usage being bad is premised on the fact that new demand will be partially filled by conventional energy, but as mentioned, the capacity of green energy isn’t just based on cost, but on comparative advantage.