(this is part of a series of posts, the link to the next one is at the bottom of the page)
There is a room in Stockholm where a bunch of kids I know hang out. It is a Sverok lokal, which is to say a little clubhouse for a gaming association, and it is exactly the unglamorous kind of good you would hope it is. Kids who do not have anywhere else to be go there. They play games, they argue about games, they sit around being teenagers together in a warm room that is not their bedroom and is not a shop that expects them to keep buying things. Some of them would be pretty lonely without it. It is, by any reasonable measure, a small and real social good.
I want to start with the fact that it works, because the rest of this post is about a problem, and I do not want you to come away thinking the situation is hopeless. It is not. We know how to make rooms like this. We have made one. The kids are ok, at least those that find this kind of resource.
Why does it exist?
It exists because it gets a grant. Public money for associations, what in Sweden we call föreningsbidrag, in this case handed out by MUCF, the agency for youth and civil-society affairs, through a system that was set up to fund youth organisations. Someone, at some point, decided that gaming clubs count, so a trickle of money flows to a federation, and some of that becomes rent on a room. That is the whole reason. Take the grant away and, almost certainly, no room.
And here is the bit that bugs me. The market was never going to build that room. Not because the market is evil, but because there is genuinely no money in it. You cannot sell “a place for lonely teenagers to feel less lonely.” The value is real, but it spills out sideways, onto the kids and their parents and the neighbourhood, and nobody can put it on an invoice. Economists call this a positive externality, which is a fancy way of saying a good thing that happens as a side effect, that the person doing it cannot charge anyone for. The dumb version is: the room makes the world a little better and makes precisely zero kronor, so left to its own devices, the economy does not build it.
So the room only exists because someone reached in by hand and paid for it directly. Can we teach the economy to see the value there naturally, without needing a planning committee? Hold that thought. I think it is most of the answer, but I want to show you the size of the problem first.
The rooms are disappearing, and so is a lot more
That Sverok lokal is an increasingly rare kind of thing. The general version has a name, the third place1, the spot that is neither home (the first place) nor work (the second place). The café, the pub, the library, the club, the church hall, the union that was also just somewhere to be. We have fewer of them than we used to2, and the ones that are left either don’t have many visitors or want you spending money the entire time you are in them.
But it is not only rooms. Look around and you notice a whole category of things quietly going missing, and they have a suspicious amount in common.
Nobody visits grandma. Partly because grandma is three hundred kilometres away, since everyone moved for work, or partly because grandma herself maybe is still working. Kids end up in front of a screen in the afternoon, because both parents have to be at a job and a tablet is a cheap stand-in for a present adult. The neighbour you used to know. The club someone used to run. The friend you used to see every week. People report fewer close friends than they used to, to the point that actual public health officials now say “loneliness epidemic” with a straight face3.
Now, I want to be careful here, because this is the part where it would be very easy to start waving my arms around. Every single one of these has many causes. Suburbs and cars. Television, and then phones. A long list of things that have nothing to do with me at all. I am not going to claim I have found the one secret root of loneliness, and you should be suspicious of anyone who does. We cannot cleanly untangle these. That is just honestly true.
What I will say is narrower, and I think it holds up: these all rhyme. And the thing they rhyme on is that they are all unpaid. Visiting grandma, raising your own kid, running the club, being a decent neighbour, keeping a friendship alive. None of it pays. All of it takes time. And I think one of the reasons we have less of it is the same boring reason I keep banging on about on this blog, which is labor pressure.
The thing the economy keeps doing
For almost all of us, a wage is the only way we get a claim on the things the world produces. That is what a salary really is. Not a reward for effort, but the one socially accepted ticket to food and shelter. Economists call this the distribution function of the wage. I just think of it as the only pipe through which stuff reaches you. And because it is the only pipe, you have to feed it. You sell your hours to a job, because the job pays, even in the cases where the genuinely better use of your time is something that does not pay. The afternoon with your kid. The Tuesday running the club. The trip to see grandma.
So you take the shift. And the economy looks at you taking the shift and concludes, smugly, that the shift must have been the most valuable thing you could possibly have been doing, because look, you chose it. Except you did not really choose it. You chose between the shift and not making rent. The room full of kids, the present parent, the visited grandparent, all of it lost a contest it was never actually allowed to enter.
The economy never sits up and goes “hang on, who is going to run the room?” It has no way to say that. It just quietly fails to fund the room, fills your afternoon with a job of marginal value, and moves on. If it could talk, the most it would ever manage, years later when maybe you’ve gotten away from a subsistence wage, is a sheepish “oh, yeah, that probably was not worth it.” And by then the afternoon is gone. You do not get the afternoon back.
This is the same idea as what I have called make-work, just pointed at your living room instead of at the office. It is the economy spending a genuinely scarce thing, human time, on output worth less than the time, and not even noticing, because all the price signals look fine.
Before anyone gets the wrong idea
I need to put a fence here, because “people have less time for family and community” is a sentence that some people love to finish in an ugly way.
This is not me saying the past was lovely and we should go back. It is not a call for mum to quit her job, or for grandma to be conscripted into unpaid childcare, or for any particular person to go back to any particular kitchen. That is the opposite of the point. The point is that people have quietly been stripped of the option to do the unpaid thing, because the unpaid thing does not pay rent and rent is not optional. The problem is not that someone is shirking their duty. The problem is that we built an economy where the loving, useful, unpaid choice is a luxury most people simply cannot afford.
So the fix is not to push anyone anywhere. The fix is to make the unpaid choice affordable, for whoever wants it, whoever they happen to be. Give people enough room to choose grandma, or the club, or the kid, without the alternative being “or starve.”
Three ways to pay for a room
So how do you actually get rooms full of kids? There are basically three settings.
One: leave it to the market. As established, you get no room. The market cannot see things it cannot sell, and a room full of happy teenagers is invisible to it. This is the default, and the default is bad.
Two: pay for it by hand. This is what Sweden does, and it is genuinely much better than nothing. The state notices a gap and plugs it directly with a grant. It is the improvised second pipe, the patchwork of grants and transfers we have bolted on, one programme at a time, to do the distributing that wages no longer manage on their own. It works. Our lokal is proof it works. But it is a patch. Someone on a committee has to keep choosing to fund it, every single year. And it only ever reaches the goods that somebody specifically thought to pay for. Nobody ever wrote a grant for “being a good neighbour,” so that one just stays broken.
Three: teach the economy to do it on its own. This is the one I actually want. Instead of the state hand-picking which good rooms deserve a cheque, you change the rule underneath, so that the people who would run the rooms can simply afford to. You do that by fixing the pipe. A basic floor of income that everyone gets, funded in a careful way I am not going to relitigate here (see the next post in this series for that), means the person who wants to spend their Tuesdays running the club is not forced to spend them on a marginal shift instead. The whole point is to stop the price system being blind to value that does not happen to arrive in the shape of a wage.
Does this replace the grants?
I am not going to pretend a basic income magically conjures gaming clubs out of thin air. It does not. Somebody still has to start the club, find the room, do all the boring organising. A floor does not do any of that for you. Targeting and universality each do something the other cannot. A grant can deliberately build one specific thing. A floor can quietly make a thousand unspecified things possible, without anyone having to choose them in advance.
So I am not even saying we should scrap the grants. The floor goes on top of what we already have (again, it is not difficult to fund, you just have to do it carefully! Check out the next post). Keep föreningsbidrag. Keep funding the lokal. All I am saying is that right now, a room full of kids gets to exist only because a committee remembered to fund it (sounds like a planned economy eh?), and that is a silly and fragile way to run a civilisation. We managed to build one room almost by accident. The goal is an economy where rooms like it are the normal outcome.
We have a room in Stockholm because, more or less by happenstance, someone funded a social good almost directly. That is genuinely wonderful, and it is not enough.
We need to teach the economy how to do that on purpose.
The next part of this series looks at Sub-subsistence work as well, and introduces the solution. The post is here.
Footnotes:
The term comes from Ray Oldenburg, The Great Good Place (1989). Home is the first place, work is the second, and everything good and informal happens in the third. ↩︎
Robert Putnam’s Bowling Alone (2000) is the classic on the long decline of this sort of associational life, “social capital” in the jargon. He blames a whole pile of things, time pressure among them. ↩︎
U.S. Surgeon General, Our Epidemic of Loneliness and Isolation (2023). It is an American document, but the pattern is not unique to America. ↩︎
This post is about two kinds of bad work, make work and sub-subsistence work, and also at the end I’ll present a solution to both. But first, some definitions:
Sub-subsistence work: work that is worth doing, i.e the marginal utility is higher than the marginal cost, but due to automation the real wage is below subsistence, i.e it’s not really enough to live on.
Make-work: the economy kinda messed up and made a job that shouldn’t exist. This is a job where the marginal utility is below marginal cost, by accident.
I’m going to start by illustrating examples of make-work since it’s the more interesting one:
You feel like your job is unimportant or a “bullshit job”. You might be doing make-work.
You feel like your colleagues mess up more than they contribute: they might be doing make-work.
You’re a hiring manager and you have too many applicants, making it hard to pick someone good: there’s a high risk of you hiring the wrong person for the job and creating make-work.
You’re a politician or a policy maker and you need to find some project to employ people: you might be contributing to make-work, rather than building something useful.
At the low end of wages, people need work even though they could be volunteering, taking care of kids, meeting friends, which are all things that carry utility. Sadly though, those things don’t buy you food or shelter, so you seek work anyway. This distorts job creation and creates extremely hard to notice make work. (This is the most complex point, and perhaps the most important, and I have an illustration of it here, and a more rigorous analysis here)
Make work becomes more common with automation because the ability for us to be sure that marginal utility is above marginal cost gets worse. The margins get tighter (or utility is harder to read), we have more applicants, we need to fix unemployment real fast, etc.
Sub-subsistence work is more intuitive, you can probably guess the examples:
You need to work more than 40 hours a week to make ends meet: that’s Sub-subsistence work.
You need multiple part time jobs: that’s Sub-subsistence work
A big part of what the gig economy is related to: Sub-subsistence work.
Both of these cases become more acute as automation increases. More labor supply means more applicants, lower minimum real wages, tighter margins between cost and utility. You end up with more sub-subsistence work and more accidental make-work. The former is a societal drag, it makes people unhappy and disenfranchised. The latter is an economic drag, it slows down innovation, missallocates capital, and hurts growth.
Automation itself isn’t a bad thing. It theoretically can and should be used to make us more stuff while needing us to work less. So, how do we make that happen without driving more of these two bad kinds of work?
The solution to both of these I have called the Consumption Stabilisation System, or CSS. It has three main components which you’ve heard of, but when all three are used carefully they operate as a extremely stable and effective economic tool, unlike any of them used alone. The three components are Land Value Tax (LVT), Value Added Tax (VAT), and Universal Basic Income (UBI). The short version of how it works is that it ensures sub subsistence work gets paid a bit more, making it feel livable, without deleting the job. It then also slowly, over many years, optimises the economy to diminish the risk of make-work by improving wage bargaining, decreasing political pressure to solve unemployment and low benefits, and decreasing applicants to jobs they are unfit for. A full economic analysis, along with more detailed evidence for the problem, is in this post.
Hope you liked the read! I really think this taxonomy, problem definition, and solution are really quite elegant and am looking forward to feedback, which you can read from others and write here.
This post is about land value tax, (LVT), and is aimed at people who have read about Georgism and are on the fence about if it is a good idea.
Land value taxes target economic rents, the main one being land but indeed one can attempt to target other kinds of economic rents if one would like. They are “neat” in that land cannot flee unlike other kinds of wealth. The problem is, well, LVT isn’t seen as very politically attractive. I propose a method by which we could make it more palatable.
The solution is using another mechanism, a VAT UBI loop. Increase VAT and use the collected money to pay for a UBI. Before you come for my neck, I have detailed the economic effects of such a policy in this post. The outcome of the modelling is that the loop is a fairly stable intervention, with minimal impact to any one group. It’s not regressive, it doesn’t cause runaway inflation or unemployment, you can’t just save the UBI, and has other nice features. With that said, another outcome is that a portion of the UBI goes into raising demand for rents, and that would necessarily raise incomes from rents (maybe you see where this is going). The advantage of this is it can be measured, and the LVT can be set to collect that increase. The political framing is simple: the LVT is simply taking back the money that the UBI is funding. Nominally, owners of rent are unaffected, but over the long run they are. This smooths the transition to LVT significantly, and I believe that makes a VAT UBI loop a valuable addition to Georgist theory.
After that process starts, one can begin to swap the VAT income for LVT income, depending on if you want to fund consumption or if you would like to use LVT incomes to do other things, like building a sovereign wealth fund, decreasing income taxes, or funding government programs/institutions.
(This piece is written in part by AI, in particular Fable 5. My original piece, in my voice, is here)
Summary of claims. (1) The wage is a bundled institution performing four functions — pricing labor, distributing output, transmitting demand information, and structuring social life — whose load-bearing assumption is that production needs nearly everyone. (2) Automation erodes that assumption cohort by cohort and place by place; the evidence is real but entangled with endogenous “absorption” institutions, and the identification problem is stated. (3) Chaining distribution to labor-market participation produces two structural failures: the economy has no sufficiency signal, because the participation margin never faces an honest market test; and it systematically violates production efficiency, because jobs are scored as benefits when they are costs. (4) In the automation limit, factor income converges to rents on non-reproducible factors; the only politically stable configuration disperses ownership of that base; and prices must be retained, because they are the economy’s demand-elicitation mechanism, not a computation a planner can replicate. (5) The implied design is three mechanisms, launched together: a universal cash floor; claims on the scarce base — a land-value tax accumulating into a buy-side sovereign equity fund; and a VAT surcharge that carries the floor’s funding while the base matures — incidence-equivalent to a flat consumption tax plus demogrant and, taken seriously, also a one-time levy on existing wealth recycled as a perpetual flow: a crude, single-shot rehearsal of the destination, with a hard ceiling, a capitalization pressure the co-launched land tax exists to intercept, and tractable stabilization plumbing. (6) Its macroeconomics are two separable channels: a one-off price-level step during the ramp, and a demand effect that is approximately neutral in a Nordic wealth distribution and mildly negative in an American one — inflationary in the price-level sense, weakly disinflationary in the demand sense, but dependent on wealth levy perception.
The wage as a bundled institution
A wage does four jobs at once. It is a price, allocating people across uses and disciplining production costs. It is a claim: for nearly all households, selling labor is the only mechanism by which the economy owes them output — pensions are deferred wages, insurance benefits are conditioned on wages lost, and capital income is held by people who were never waiting on the channel. It is a signal: spent wages are the demand half of the price system, and a person with no purchasing power is a sensor the market cannot read, which makes distribution a question of informational bandwidth and not only of equity. And it is a bundle of non-pecuniary goods — time structure, status, contact, purpose — whose loss damages people even under full income replacement, a result stable since the Marienthal studies.[^1]
One instrument, four functions. The arrangement works exactly as long as production needs nearly everyone’s labor, so that labor can serve as the universal claim. The interesting question about automation is not “will there be jobs” — job creation and displacement coexist trivially — but which of the four functions survives the erosion of that universality, and what replaces the ones that don’t.
Evidence, with the identification problem
Two headline statistics get cited as if they settled the question, and neither can. The unemployment rate conditions on searching for work, so everyone an absorption institution has reclassified — retired, enrolled, assessed as unfit — simply vanishes from it. Aggregate participation counts them, but as one number moved by demographics, schooling norms, and pension rules all at once, it can drift for half a century without disclosing which force did the work. The series worth reading sit underneath both, and before listing them, the honest methodological note.
The hypothesis doing organizing work in this essay is that several large institutions — retirement, extended education, disability — function partly as absorption mechanisms: endogenous responses that relabel weak labor demand as a life stage, a training period, or a health state. This hypothesis is observationally close to the benign reading in which those institutions reflect demographics and rising returns to schooling. Both are partly true; they are overdetermined institutions. Pensions emerged from labor movements and coalition politics as much as labor-demand arithmetic, and for most of the twentieth century education expansion tracked genuinely rising skill demand — the Goldin–Katz race, which education was mostly winning.[^2] The absorption reading fits the margins (credential inflation, lengthening duration, parking of the young), not the core. I cannot separate the hypotheses with aggregate data, so I will state the margins where they diverge and the observations that would falsify my reading, below.
The dials:
Prime-age men. US participation for men 25–54 fell from 98% in the mid-1950s to about 89%; among those with high school or less, from over 96% to 83%. Disability insurance absorbs little of it — SSDI receipt rose roughly 1.5 points over a period in which participation fell 8.4.[^3] Note that this cuts against a pure absorption story: this is the unpatched failure mode, exit recorded by no program. Supply-side explanations (spousal income, transfers, caregiving) account for little of the trend.[^4]
Factor shares. The global labor income share has drifted down since the 1980s — roughly five points to its mid-2000s trough, 53% to 52.4% in the last decade alone — and the US labor share stands at its lowest since the Great Depression.[^5][^6] The strongest critique: Rognlie showed that the entire postwar rise in the net capital share across the large developed economies comes from housing; ex-housing, capital’s net share has gone roughly nowhere.[^7] Read one way this deflates “automation is eating labor’s share.” Read the other way it is the single most important stylized fact below: returns are already concentrating into the non-reproducible factor. Hold it for the limit section.
AI and the entry margin. Since late 2022, employment for workers aged 22–25 in the most AI-exposed occupations has fallen 13–16% relative to other groups, while experienced workers in the same occupations and young workers in unexposed occupations are flat or growing. This is a working paper and should be priced as one, but it is not naive: the result survives excluding technology firms and remote-amenable occupations; the exposure taxonomy has no predictive power for young workers’ outcomes pre-LLM, including through the COVID shock; it replicates in public CPS data; and the declines concentrate where adoption automates tasks rather than augments workers.[^8] Recent-graduate unemployment now exceeds the overall rate for the first time in the modern record; the gap is small.[^9] Early, revisable — but the pattern is precisely where a substitution story predicts first incidence: the entry rungs.
The improvised second pipe. US government transfers are 18% of personal income, up from 8% in 1970; a majority of counties now draw a quarter or more of income from transfers, against fewer than 1% of counties fifty years ago.[^10] Composition honesty: most of the growth is Social Security and Medicare — aging plus healthcare inflation — so this is not, by itself, evidence that the wage channel failed. What it establishes is narrower and sufficient: a non-wage distribution system already operates at the scale of a sixth of all personal income, assembled categorically, one emergency at a time, with screening costs, participation cliffs, and no design.
Falsification. The reading above is wrong if, over the next five years: prime-age participation rises broadly through AI diffusion; the entry-level employment gap closes as the rate cycle normalizes; bottom-decile wages keep gaining on the median without policy force; the ex-housing labor share turns durably upward; or the canaries result washes out under revision. In that world, the design below was built early, and its cost was a modest progressive consumption tax with a demogrant and an automatic stabilizer attached. The asymmetric loss sits on the other branch.
Failure one: no sufficiency signal
Keynes’s 1930 extrapolation — productivity gains partly cashed out as time — worked for a century: annual hours roughly halved between 1870 and the 1970s. Then the paths split; continental Europe kept converting some gains into time while US hours flatlined (taxes, unions, preferences — pick your school), and much of the leisure that did arrive came in blocks at the edges of life, retirement and extended education, rather than as shorter weeks in the middle.[^11]
The structural reason the mechanism cannot complete is that in a wage-distribution economy, “we need less labor” has no way to arrive as good news; it can only arrive as someone’s zero. So the institutional stack is built — rationally, locally — to suppress the signal: employment mandates, payrolls as the success metric of stimulus, jobs as the unit of political accounting. The panel has gauges for inflation, unemployment, and growth, and no gauge for enough.
The standard reply is that “enough” is undefined because wants are unbounded. Perhaps. But the claim is never tested, and here is the precise sense in which the test is rigged. The competitive benchmark — wages track marginal product — is a statement about the wage level; the failure is at the participation margin. A worker whose entire claim on subsistence routes through employment has a reservation wage pinned near subsistence rather than at the social opportunity cost of their time. Jobs whose output is worth less than any dignified valuation of that time get created and staffed anyway, and the fact of their staffing is then cited as revealed preference that the work was worth doing. Monopsony evidence reinforces the point at the wage level too,[^12] but the argument does not depend on it: run an auction in which one side cannot walk away, and the hammer price carries no information about whether the lot was worth selling.
Failure two: production inefficiency by design
In cost–benefit analysis, labor is an input: a cost, the valuable time a project consumes. In a wage-distribution economy the sign flips and jobs are scored as benefits — by politicians, development agencies, planning processes, bailout metrics. The exception is real and bounded: where the shadow wage is below the market wage (depressed regions, deep slumps), job creation has genuine transfer value. The error is letting that emergency logic set the steady state.
The inversion moves real resources. Land and infrastructure concentrate where the remaining labor-intensive, face-to-face work lives, because proximity to a job is the price of holding a claim; some of that is genuine agglomeration productivity, some is claim-chasing, and current accounting cannot distinguish them. Capital tilts toward employment-visible projects. And the bottom of the service sector operates at a scale set by desperation pricing: a business model that clears only because its workers lack an outside option is receiving an input subsidy, paid in kind by its own workforce. Sectors thus exert gravitational pull on land, talent, and policy in proportion to the claims they distribute rather than the output they produce — a market distortion by the textbook definition, unnamed because the distorting institution is the labor market itself. The system functions as a welfare state run through the side door of payroll, with the deadweight billed to everyone and itemized to no one.
The limit case
Take the endpoint seriously as a model: production needs almost no one, machines reproduce machines, the marginal cost of reproducible goods falls toward energy and materials. Labor income goes to zero share; returns on reproducible capital get competed toward commodity margins. What remains is income to non-reproducible factors: land and location, resource and energy flows, spectrum, the atmosphere’s absorptive capacity, and legal artifacts — patents, licenses, market position. In the limit, all income is rent, and the ownership question is the only question.
Only the dispersed-ownership configuration of that endpoint is stable. Concentrated rentier ownership with universal suffrage does not sit still: it resolves into redistribution or into the end of the franchise, and history offers exits in both directions, none gentle. A universal claim on the scarce base — a dividend — is the arrangement in which markets, democracy, and full automation survive contact with each other. And per Rognlie, the convergence is not prospective: the developed world’s net capital-share rise has already been, in its entirety, a land story.[^7]
What must survive in any configuration is the price system, and the reason is worth stating before its AI-flavored challenge arrives. Prices are not a computation a sufficiently large planner replicates; they are a measurement — the only incentive-compatible instrument that elicits preferences at scale, by making people choose under budget constraints. An economy that stops asking people, each holding purchasing power they may point anywhere, has not automated demand; it has amputated it. The dividend is the sensor grid as much as it is the equity instrument.
Non-solutions, briefly
Robot taxes and protection violate production efficiency — Diamond–Mirrlees says don’t tax intermediate inputs; tax rents and consumption and leave the production side undistorted — while slowing the abundance that funds everything else.[^13] Scaling means-tested categories compounds effective-marginal-tax-rate cliffs and screening costs, and requires a new deservingness category per displaced cohort; the UK’s binary “can/cannot work” assessment is the live cautionary case of classification incentives doing the absorbing. “Everything gets cheap” fails on composition: the automatable half of the basket deflates while the scarce half — housing — absorbs the gains, which is Rognlie’s fact operating at the level of household budgets. A job guarantee takes the non-pecuniary bundle seriously but preserves the form by having the state invent the content: the participation-margin test stays rigged and the missing gauge stays missing.
The design: three mechanisms
Mechanism one: the floor. A universal, individual, unconditional cash payment. Universality is mechanism design, not generosity: a zero marginal withdrawal rate (earnings always add — no EMTR spikes anywhere in the distribution), no screening or ordeal costs, no classification incentives of the kind currently filling incapacity rolls, and political durability — a program every citizen receives is one no government quietly cuts, as Alaska has demonstrated since 1982. A floor, not a livelihood, at first.
Mechanism two: the base. The funding source decides whether the system survives the trend it is built for, and the limit case dictates it: claims on non-reproducibles, plus equity in the machines.
Rents first, and from the first day. Land value capture is the textbook non-distorting tax — supply elasticity zero, the base immobile, and (per the Henry George theorem in its weak form) large enough to matter[^14] — and it is the base that grows as automation concentrates returns into scarce factors, which the Rognlie decomposition says has been happening for decades. It launches with the dividend rather than after it, for a reason the bridge’s own charts supply below; its incidence and revenue are left unmodeled in this essay because they depend on rate, assessment, and exemption choices that sit downstream of the modeling here. The cadastral infrastructure mostly exists; Denmark has assessed land separately for a century. Then spectrum, resource royalties, congestion, carbon.
Equity second, and precision matters because there is an honest instrument and a seductive one. The seductive instrument is the share levy — tax firms in newly issued stock, Meidner-style. Sweden ran the experiment’s neighborhood once; the wage-earner funds were politically annihilated within seven years, and the rolling dilution of listed firms was the firestorm at least as much as the collective governance.[^15] The honest instrument is buy-side: rent revenues and bridge surpluses accumulate in a sovereign fund that purchases the capital stock at market prices, Norway-style — individually attributed claims, levy-free acquisition. The buy-side route also answers an objection nothing else in the design reaches: a small open economy cannot tax the rents of a foreign model company — corporate tax stops at the border and the IP books elsewhere — but it can own them. Norway’s fund holds on average roughly 1.5% of every listed company on earth.[^16] What sovereignty cannot reach, a brokerage account can; the dividend then grows with the machines wherever they are incorporated.
Mechanism three: the bridge. Fund accumulation takes a decade-plus and land assessment ramps over years; the floor needs full revenue from the first month, and the one base that delivers it immediately is consumption: a uniform VAT surcharge financing the flat dividend.
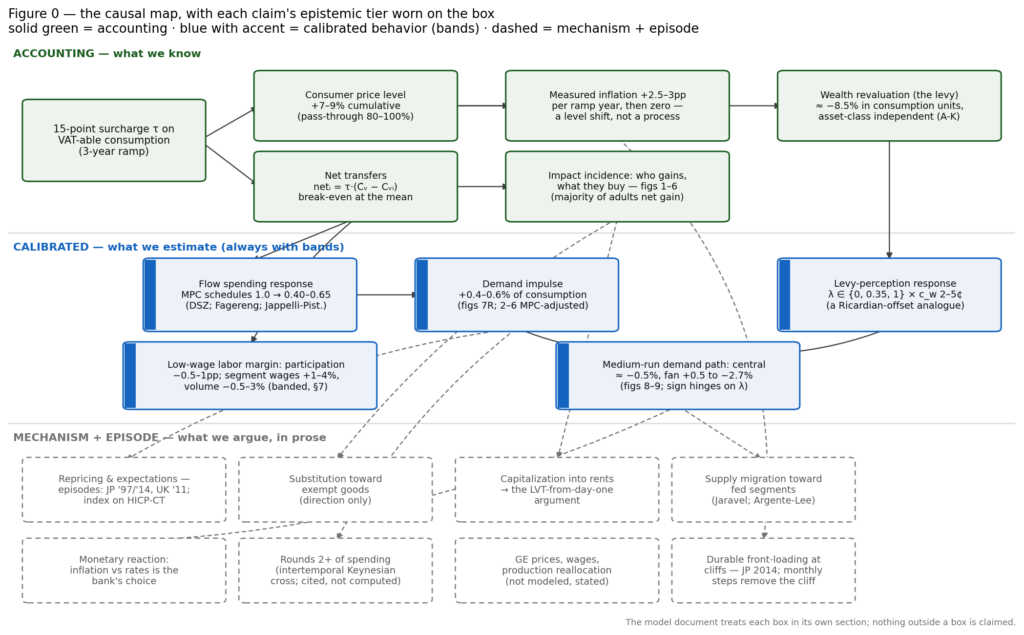
Figure 0 — the map of what follows. Every causal claim in the bridge analysis, with its epistemic tier worn on the box: solid green is accounting (identities and mechanical arithmetic; data quality is the only error source), blue with the accent bar is calibrated behavior (named parameters, always shown with bands), dashed gray is mechanism-plus-episode (argued in prose, anchored to a cited natural experiment, never drawn).
The mechanics are friendlier than VAT’s reputation. With surcharge rate τ on VAT-able consumption and a balanced budget, each adult pays τ·Cᵢ and receives τ·C̄, so the net transfer is
netᵢ = τ·(C̄ − Cᵢ) —
linear in consumption, progressive over consumption by construction, with break-even at the mean; since consumption is right-skewed, a majority of adults are mechanical net recipients. Figure 1 puts real numbers on it, from Finland’s 2022 Household Budget Survey — the most recent Nordic consumption-by-quintile survey in existence, Sweden’s having been discontinued after 2012 with the next wave only now in the field.[^22] A 15-point surcharge on the existing VAT base funds a dividend of €193 per adult per month, each child adding a 30% share; the net runs from +€77 a month per adult share for the bottom quintile (+5.9% of its budget) to −€88 for the top (−3.1%), with the middle quintile sitting within €5 of break-even.
Figure 1 — tier: accounting. Net monthly effect (dividend received minus extra VAT paid) of a 15-point surcharge funding a flat per-adult dividend (each adult one share, each child 0.3), Finland 2022, per adult share. The relation is exactly netᵢ = τ·(C̄ᵥ − Cᵥᵢ) per share on VAT-able consumption, which runs from 59% of the bottom quintile’s budget to roughly two-thirds in the upper quintiles — lowest at the bottom, because the largest exempt item, rent, weighs heaviest in poor households’ budgets, which makes the surcharge marginally more progressive than a tax on total consumption would be. Quintile means compress the tails: individual households extend well past these five points in both directions, so the figure understates the spread of net positions, not the mechanism. No behavioral assumption enters; the only judgment inputs are the per-category VAT-ability.
A second property follows from uniformity: a flat surcharge leaves relative prices unchanged, so the first-order reallocation of demand across goods is a pure income effect of the redistribution — no substitution effects to model, and an argument for keeping the surcharge uniform rather than importing the exemption lattice of existing VATs (the theory case for uniformity is Atkinson–Stiglitz; the EU’s own accounting makes the practical case, with revenue forgone to reduced rates and exemptions running at six times the revenue lost to non-compliance[^24]). Figure 2 runs the income effect through the data at the second COICOP level: quintile market shares for each line of the family budget from the same Finnish survey, income elasticities computed per quintile from the Working model — η = 1 + β/w, with β from USDA’s 144-country demand system, so that food’s elasticity falls from 0.44 in the bottom quintile to 0.30 in the top without anyone assuming it[^23] — and each quintile’s budget shock scaled by its marginal propensity to consume out of a permanent flow, with the MPC=1 benchmark left visible as a ghost outline on every bar.[^27] The MPC gradient matters more than it sounds: recipients spend roughly all of a permanent transfer while payers finance much of theirs from saving, so the adjusted bars no longer sum to zero — their sum is the aggregate demand impulse, +0.4% of charted budget in Finland — and several knife-edge categories flip sign outright once the top’s withdrawal halves, vehicle operation among them. Three readings. First, the scale: the largest single reallocation in the basket is about €5 per adult-share month, on budgets averaging €2,051 — a transfer worth three to eight percent of budgets moves purchasing power without much reshaping relative demand. Second, the impact period is nearly all green: at launch, this policy is almost pure demand addition, the withdrawals arriving later and smaller. Third, where the largest bar sits: actual rents, +€4.92 a month. Renters are concentrated precisely where the net transfers land, so the figure shows the capitalization leak (taken up below) from the demand side, before a landlord has repriced anything — the empirical reason land taxation starts on day one rather than on layer two’s schedule.
Figure 2 — tier: accounting incidence × calibrated behavior (η, MPC); the MPC=1 first-order benchmark is the ghost outline. Impact-period changes in spending by COICOP second-level category, euros per adult share per month (percentage change in parentheses): Δ€g = Δ%g·C̄g with Δ%g = Σq θqg·ηgq·(mpc_q·netq/Cq). Elasticity fidelity is at the parent-group level — subcategories inherit their group’s quintile-specific η, with the food system split via the stage-two parameters — while the incidence θ is each line’s own. Caveats: cross-country β applied within-country (a use the source itself endorses); education omitted, since a 0.3% budget share makes β/w numerically meaningless; imputed and owner-occupied housing omitted, since nothing is transacted there; impact-period only — the rent bar is the demand impulse, not the post-capitalization equilibrium: landlords are the other claimant on that €5.
What no category bar can show is the margin inside it: every line of Figure 2 spans a quality ladder — used cars and new ones, discount groceries and delicacies, studio rentals and penthouses — and a transfer from the top of the distribution to the bottom should walk demand down each ladder even where the category total barely moves. Expenditure data records price times quantity fused, so quality cannot be separated from volume without quantities (the unit-value method of Deaton, which needs the survey microdata). But the first-order geometry is already in the model: each category’s change decomposes by quintile, and quintiles occupy rungs. Figure 3 opens the ten largest movers. Vehicle purchases are the one red bar left standing at impact: the top two quintiles withdraw new-car money faster than the bottom three add used-car money, for a net of −€0.5 that conceals gross tier rotation several times its size. Rents are the mirror case: the +€5 is almost entirely bottom-quintile money, concentrated on the cheap end of the housing stock, which localizes the capitalization pressure too. The mapping from quintile to rung is imperfect — the rich shop at discounters too — but the supply side takes it seriously: product entry follows growing demand segments, and recessions run the same film in reverse as households trade down within categories.[^25] If anything the composition shift is the larger long-run story: variety and quality competition migrating toward the segments the dividend feeds.
Figure 3 — tier: same hybrid as Figure 2. The ten largest impact-period movers, decomposed by quintile: green segments are demand added by the gaining quintiles (Q1–Q3), red is demand withdrawn by the paying quintiles (Q4–Q5); the solid diamond marks the MPC-adjusted net, the hollow diamond the MPC=1 net. Where quality tiers track buyers, the gross flows are the within-category composition shift — the same category growing at its cheap end while shrinking at its expensive end.
The rent result invites a question the design should answer before going further: if rents are where the money lands, why not pull rents inside the VAT and tax them there? Because two-thirds of households consume housing services from a dwelling they own, and imputed rent cannot be taxed — nothing is transacted. Taxing actual rents while imputed rent walks free is not a tax on housing; it is a tax on renting, levied on the tenure group that is two-thirds of the bottom decile and a tenth of the top, and it would partially undo the progressivity that Figure 1’s caption credits to the exemption. The steelman — in supply-inelastic markets a rent tax falls largely on landlords — fails three ways: it misses the owner-occupied half of the land base entirely, it taxes the structure along with the land (and new construction already carries VAT, so rental housing alone would be taxed twice), and its incidence flips onto tenants exactly where supply is elastic. Notice instead what the standard design already does: new construction is taxed — prepaying the VAT on that dwelling’s entire future stream of housing services, tenure-neutrally — and the subsequent flow is exempt. What escapes the consumption tax is therefore precisely the existing stock: land plus old structures. The hole in the VAT is shaped exactly like the scarce-rent base, and the instrument shaped exactly like the hole is the land-value tax — which reaches land under every tenure, exempts structures, and cannot be shifted. The bridge structurally cannot tax the destination’s base; that is the formal version of why the bridge is not the destination.
The same exercise runs on American data — the Consumer Expenditure Survey’s 2024 deciles — with two translations: the United States has no VAT, so the flags describe an EU-style base being introduced, and the survey reports unequivalized consumer units, so everything is converted to payment units — one share per adult, 0.3 per child — using the table’s own household-composition rows.[^26] The shape survives the Atlantic, and deciles restore the tails the Finnish quintiles compressed (Figure 4): fifteen points on that base fund about $249 per adult per month, seven deciles gain, break-even falls between the seventh and eighth, and the top decile pays $173 a month net per adult share (−3.9% of its budget). The demand shifts (Figure 5) replicate the headline: the largest single mover is again rented dwellings, +$3.36 a month — the rent result is not a Nordic artifact. And because the American table splits vehicle purchases by tier, the quality-ladder conjecture of Figure 3 becomes a measurement: with the MPC gradient applied, new cars fall (−$0.39, against a first-order ghost of −$1.23) while used cars rise (+$0.38, flipped from a first-order −$0.05) — the walk down the ladder visible as opposite signs on the two ends of the same showroom. Two American inversions earn a sentence each. Out-of-pocket health and vehicle insurance rise with the dividend (+$1.08, +$0.53): what the Nordic state provides as a service, the American bottom deciles buy as a necessity, so handing them cash buys coverage — and health insurance is the basket’s biggest churner, gross inflow from the gaining deciles running several times the top-side trim. And the payer-concentrated discretionary margin — fees and admissions, vacation lodging — shrinks only modestly at impact (−$0.20, −$0.13), its larger contraction arriving with the wealth channel below.
Figure 4 — tier: accounting. Net monthly effect per adult share (each adult one share, each child 0.3 — the flat payment rule) of a 15-point consumption tax on an EU-style VAT base funding the dividend, by pretax-income decile, Consumer Expenditure Survey 2024. The dots do not fall strictly in income order through the middle: the bottom deciles are single-adult-heavy and the payment follows adults, not equivalence — composition, not error. The VAT-able share of consumption runs 59–64% across deciles — almost exactly the Finnish range. Three caveats: these are income deciles, so the bottom mixes the persistently poor with the transitorily poor consuming above income; the survey under-captures spending at the top (CE covers roughly three-fifths of comparable national-accounts consumption, with the shortfall concentrated among high earners), so the top-decile net is understated; and US health lines are out-of-pocket only — employer-paid premiums never pass through the household budget.
Figure 5 — tier: accounting incidence × calibrated behavior; MPC=1 ghosts shown. Impact-period demand shifts under the same instrument at US decile shares, Working-model elasticities, and the literature MPC schedule, dollars per adult share per month, same formula and caveats as Figure 2; the adjusted bars sum to the aggregate demand impulse, here +0.4% of charted budget. Education, mortgage interest, and property taxes are in the budget totals but off the chart — degenerate β/w in the first case, financing and taxes rather than goods demand in the others.
Figure 6 opens the American bars the way Figure 3 opened the Finnish ones, at decile resolution. The rent flow tracks tenure almost mechanically — 66% of bottom-decile households rent against 10% at the top — so the bottom three deciles supply the bulk of the gross additions and land, undiluted, on the cheapest segment of the rental stock. The health-insurance bar makes the churn explicit: coverage bought at one end of the market while plans are trimmed at the other, gross flows several times the net. With payers smoothing, the impact-period top-10 is green almost throughout — the deep red bars belong to year two, and to the channel the next section opens.
Figure 6 — tier: same hybrid as Figure 5. The ten largest impact-period US movers decomposed by decile: green segments are demand added by the gaining deciles (D1–D7, darker = poorer), red is demand withdrawn by the paying deciles (D8–D10, darker = richer); solid diamond = MPC-adjusted net, hollow diamond = MPC=1 net.
Anticipating the obvious referee comment: on static labor-supply incidence this is approximately a negative income tax. With tax-inclusive rate t′ = τ/(1+τ), the budget set is real consumption = B′ + (1−t′)·earnings — the same affine schedule as lump sum plus flat marginal rate, so claims that VAT-UBI dominates NIT on intensive-margin incentives are nominal illusion. The genuine differences are the base and the administration: (i) the consumption base reaches existing wealth — a point developed in full two sections down; (ii) remittance is firm-side through the invoice-credit chain, third-party-reported at every link; (iii) the destination basis reaches the rents embedded in imported services — AI services included — at the domestic till, revenue that source-based corporate taxation structurally cannot catch. Choose the instrument for the base and the enforcement, not the incentives.
On labor supply, the floor is roughly a tenth of a full-time low-wage gross income, and the evidence scales accordingly. The cleanest income-effect estimate — a three-year $1,000-a-month RCT — produced about two points of employment and 1.3 hours a week;[^18] linear scaling to this dividend gives −0.5 points, and the universal-payment natural experiments bracket from below: no aggregate employment effect from Alaska’s dividend,[^19] none from Finland’s experiment. Two design features push toward the small end — the payment is universal and permanent, so marginal effective tax rates change by exactly zero, and it arrives as income rather than as a condition. The band this essay commits to is participation −0.5 to −1 point among low-wage workers, concentrated where wage minus reservation wage is thinnest; pushed through an extensive-margin supply elasticity of about 0.25 and a segment labor-demand elasticity between 0.5 and 1.5,[^34] that is wages +1–4% and volume −0.5 to −3% in the lowest-wage service segment — the desperation subsidy being withdrawn, which is the mechanism working. Occupation-level forecasts are refused on principle: no identification exists at that resolution. None of this tests the general-equilibrium version; the slow ramp below is the honest answer to that, not a pilot citation.
The limits are firm and should be stated as design constraints, not buried. The ceiling: a livelihood-grade dividend (≈40% of median income) costs on the order of 16% of GDP in a country like Sweden, implying a surcharge north of fifty points on the VAT-able base — roughly double the highest standard rate ever administered. The binding constraint at such rates is, perhaps surprisingly, not classic evasion: the invoice-credit chain is structural, third-party reporting holds the business-to-business trail at any rate, and the evadable base is bounded by the segments the trail never reaches — final retail and small-trader services. That is why EU compliance gaps run from one percent to thirty at broadly similar statutory rates: enforcement architecture dominates rate.[^20] What does scale with the rate sits elsewhere: missing-trader fraud, whose profit is linear in τ; cross-border purchases of services; and the perfectly legal self-supply margin — at a fifty-point wedge, paying anyone to do anything you could badly do yourself becomes a luxury, and labor-intensive services exit the market without a euro of evasion recorded.[^20] A floor-grade dividend (roughly a tenth of median) lands near the edge of tested practice. The bridge buys the pipe — payment rail, universal registry, legislated rule — not the endgame. The capitalization pressure: the largest demand flow in both countries lands on the most supply-inelastic good in the basket, and part of any cash floor capitalizes into rents;[^21] this is what the co-launched land-value tax is positioned to intercept, and it is why the design is three mechanisms at once rather than a sequence. The plumbing: monthly steps over years; indexation of pensions, wages, and contracts to a constant-tax price index (HICP-CT exists) for the ramp’s duration, or the engineered level shift double-pays every indexed contract; a buffer fund holding months of payouts, because the pure pay-as-you-go loop is procyclical and of {strict PAYG, stable dividend, no reserve} you may pick two; and statutory disregard of the dividend in means tests, or the existing welfare state claws it back from exactly the people it targets. Eligibility: residence-years proration, on the garantipension model, blunts the migration-pull objection without means-testing anyone. Stacking: the floor goes on top of the existing welfare state; consolidation is a later rationalization, not a precondition.
The inflation accounting, and the tax on the stock
Any honest macro story here has two channels, and adding them into one number is how dishonest inflation claims get built, so they stay separate.
The first channel is mechanical: the tax in the till. At 80–100% pass-through, fifteen points on roughly three-fifths of the basket lifts the consumer price level a cumulative 7–9% — a three-year ramp converts that into 2.5–3 points of measured inflation per year and then zero. A level shift, not a process, and the VAT episodes on record behave exactly that way: Japan’s 1997 and 2014 hikes and Britain’s 2011 rise each jumped prices for one year and reverted, where the central bank visibly looked through the step and indexation ran on a constant-tax index.[^28] The ramp’s job is to convert one ugly nine-percent step into three forgettable ones; its shape matters too, because tax-day cliffs pull durable purchases forward and leave a hole after — Japan’s 2014 sawtooth is the cautionary episode[^33] — which is why the design ramps in monthly micro-steps that leave nothing worth front-running.
Figure 7 — tier: left panel accounting; right panel calibrated. The inflation accounting of a three-year ramp to fifteen points, US calibration. Left, the mechanical channel: the tax itself in consumer prices at 80–100% pass-through — a one-off level shift of 7–9%, paid as roughly 2.5–3pp of measured inflation per ramp year. Right, the behavioral flow channel: excess consumption demand from the MPC asymmetry — balanced budget, unbalanced demand — under saving-gradient schedules spanning the literature. The flow channel is half the behavioral story; the other half is Figure 8.
The second channel is behavioral, and it has two parts that pull in opposite directions. The first part is the flow asymmetry already visible in Figures 2–6: with MPCs declining in income, moving money from savers to spenders adds net consumption demand — worth +0.3 to +0.5% of aggregate consumption at the full fifteen points.[^27] If that were the whole story, the policy would be a small permanent demand stimulus.
It is not the whole story, because a consumption tax is also a tax on the stock. By the Auerbach–Kotlikoff equivalence, a consumption tax is incidence-identical to a flat wage tax plus a one-time levy on existing wealth:[^17] after the price step, every unit of wealth destined for domestic consumption buys about 8% less of it, and that levy is collected at the till whenever the wealth is eventually spent. This means the VAT bridge already does — crudely, and exactly once — what the LVT base is ultimately for: it converts a slice of the existing stock into a perpetual universal flow, through the price level rather than through deeds and registries. It is also the practical answer to “how do you reach accumulated fortunes without a wealth registry”: you don’t audit the wealth; you wait at the checkout. And it supplies a second formal argument for the handoff to the base, alongside the rent-shaped hole above: a one-time announced capital levy is the classic near-non-distorting tax, but a repeated one is not — ratcheting τ again and again would teach wealth to anticipate the next levy, with all the avoidance and distortion that implies. The bridge works once. That is an argument rather than a model output, and it is stated as one.
How much of that levy shows up as a demand response, and when, turns on a parameter this project treats as its single most consequential judgment call: λ, the share of wealth on which holders behaviorally respond to the levy — distinct from bearing it, which everyone does at the till eventually. The reasoning, in brief: the wealth-effect propensities the literature estimates, three to five cents on the dollar per year,[^31] come from visible revaluations — house prices moving, brokerage accounts moving, windfalls arriving. Under a VAT step, only the nominal slice of the balance sheet visibly revalues: a deposit shows the same number while prices rose, which is precisely the experience those estimates measure, while a house or an equity portfolio shows no measured loss at all even though its consumption-units loss is real. λ is therefore a Ricardian-offset-type parameter — λ=1 is the full-rationality corner, exactly as full Ricardian equivalence is — and the empirical literature on responses to invisible present-value claims consistently finds offsets of 0.2–0.5, not 1. The central scenario takes λ = 0.35, the rough share of household wealth in visibly nominal form; the fan keeps 0 and 1 alive because this is judgment, not estimation, and it is worn on the chart.
Figure 8 — tier: calibrated; the fan is the uncertainty statement. Left: the aggregate demand path of the balanced-budget dividend, US calibration (CE 2024 flows; SCF 2022 wealth by income group, uprated to the flow year with the Fed’s distributional accounts), under three levy-perception scenarios — flow-only (λ=0), nominal-assets central (λ=0.35), full Auerbach–Kotlikoff (λ=1) — with bands spanning the MPC schedules and wealth-effect propensities. Right: inside the central case — the flow impulse, the levy response, and the slow endogenous rebuild. Stock-flow consistent in deviations; the budget identity carries no levy cash-flow line (that would double-count the till tax), while the consumption rule responds to wealth in consumer-price units; equations and the double-counting resolution are in the model document.
The American answer (Figure 8): the flow impulse of +0.38% is overtaken within the first year by the levy response, and the central scenario settles at −0.69% of consumption at full ramp [−0.97, −0.14], with the full A-K corner at −2.7% [−3.3, −1.2] and well over half of the top decile’s year-two adjustment — −$598 a month — being levy response rather than flow tax. The drag decays as households rebuild real balances, but at wealth-effect speed, which is to say over decades. The honest headline is therefore near-paradoxical: the policy is inflationary in the price-level sense and, under central perception, mildly disinflationary in the demand sense. Neither the runaway-inflation objection nor the free-stimulus sales pitch survives the fan — which is, for credibility, the right place to be. And the macro magnitudes are central-bank-trivial either way: a drag of half a percent of consumption is well inside what policy offsets without noticing; whether it surfaces as inflation or as interest rates is the bank’s choice, not the program’s. The program does hold one dial of its own: the split between dividend payout and accumulation in the buy-side fund can lean against the cycle — parking marginal surcharge and land revenue when demand runs hot, releasing it in slack — stabilizing the path while accelerating the ownership migration. A design option, stated as one rather than modeled.
Where the λ judgment matters is itself measurable, category by category (Figure 9): at year two of the ramp, the whisker on each bar spans flow-only to full Auerbach–Kotlikoff. The whiskers are widest exactly where top-decile money lives — health insurance spans +$0.71 to −$5.57 a month, new cars −$0.27 to −$6.03 — and shortest where the bottom’s money goes: the rent bar stays positive across most of the fan, tobacco and medicines barely move. Read it as a map of which conclusions are scenario-robust and which are hostage to λ.
Figure 9 — tier: calibrated; the whiskers are the uncertainty statement. US demand by category at year two of the ramp: the bar is the central scenario (λ=0.35), the whisker spans λ=0 (flow only) to λ=1 (full A-K); per-decile year-two budget responses from the simulation, allocated across categories by the same θ·η structure as Figures 2–6. The flat-λ corner overstates middle-decile response — their wealth is housing, the least visible revaluation there is — so read the λ=1 ends as outer bounds; the Finnish companion is in the model document.
Figure 10 — tier: calibrated; same construction as Figure 8 at quintile resolution. Finnish calibration: HBS 2022 flows per consumption unit; Statistics Finland wealth-survey net worth by income decile (2023 wave), bridged to quintiles and consumption units. The Finnish year-two category decomposition, like the American one, lives in the model document.
Run the identical machinery on Finnish data (Figure 10) and the sign changes: the central scenario sits at +0.04% [−0.17, +0.29] — approximately demand-neutral — and even the full A-K corner only reaches −0.65% [−0.99, −0.09]. The difference is not the policy; it is the wealth distribution the policy lands on. Finland’s household wealth runs about 3.7 years of national-accounts consumption against roughly eleven in the United States, the Finnish top quintile holds €391k per consumption unit where the American top decile holds $6.6M, and the balance-sheet composition points the same way: the net visibly-nominal position — deposits and bonds minus debts — is negative in every Finnish income decile, while in the United States it turns positive exactly where the wealth is, +4% of net worth for the 80th–99th percentiles and +10% for the top one.[^29][^30] The American perception channel has something to fire on at the top; the Finnish one largely doesn’t. The demand-sign question, in other words, is substantially a wealth-concentration phenomenon — and the instrument is best-behaved precisely in the Nordic setting where this essay proposes deploying it first.
Deciding who owns the scarce base of an automating economy is the political question of the century; the design’s aim is to spend the politics well — one explicit fight about ownership and rules instead of ten thousand recurring ones about deservingness.
What the repaired margin shows
Once a floor exists, the participation margin starts reporting honest numbers — in proportion to the floor, and the proportion should be stated. At bridge scale, roughly a tenth of median income un-rigs reservation wages only at the bottom, which is where desperation pricing is worst, so the repair starts in the right place; it extends upward only as funding migrates onto rents and the fund, over decades. Work that can pay honestly priced time continues and deserves to; work that cleared only because its workers could not walk away shrinks or automates — the implicit input subsidy withdrawn, however loudly its business models describe the withdrawal as a “distortion.”
And the missing gauge gets a needle. Hours and participation become readings rather than wiring faults. If wants are effectively unbounded, the dials will say so — nothing in the design withdraws a krona of earnings. If Keynes was righter than the panel has been permitted to admit, leisure can finally arrive distributed as shorter hours and easier exits rather than concentrated as zeros on the displaced. The design is deliberately agnostic; its job is to un-rig the question. Which is also why it is not a degrowth program: nothing here says stop. It says ask properly, and let the answer count.
Residual
The fourth function does not transfer with cash; Jahoda’s deprivation channels will apply to a post-wage transition exactly as to unemployment, and no transfer schedule fixes them. The precedent for repair is institutional and recent — “retiree” was not a livable identity until pensions made it one, and acquired norms and self-respect within two generations — but the work runs at culture speed, not policy speed. The worst management of that gap is the current one: holding the distribution system hostage to the status system by preserving jobs that fail every honest test.
[^1]: Jahoda, Lazarsfeld and Zeisel, Marienthal (1933); Jahoda, Employment and Unemployment (1982).
[^2]: Goldin and Katz, The Race between Education and Technology (2008).
[^11]: Keynes, “Economic Possibilities for our Grandchildren” (1930); Huberman & Minns hours series via Our World in Data. https://ourworldindata.org/working-hours
[^12]: Manning, Monopsony in Motion (2003); Azar, Marinescu and Steinbaum on labor market concentration.
[^13]: Diamond and Mirrlees (1971), production efficiency.
[^14]: Arnott and Stiglitz (1979) on the Henry George theorem. The strong version is not needed here; the weak claim is only that land is the zero-supply-elasticity base that grows with automation.
[^16]: Norges Bank Investment Management: the Government Pension Fund Global holds on average ~1.5% of listed companies worldwide.
[^17]: Auerbach and Kotlikoff on consumption-tax incidence: a flat consumption tax ≡ flat wage tax + one-time levy on existing wealth.
[^18]: Vivalt et al. (2024), the OpenResearch unconditional cash study: $1,000/month for three years, −2.0pp employment, −1.3 hours/week, concentrated among parents, students, and carers.
[^19]: Jones and Marinescu (2018) on the Alaska PFD.
[^20]: Highest standard VAT rate ever administered: Hungary, 27%. EU VAT compliance gap: 9.5% of theoretical liability in 2023 (€128 billion), ranging from about 1% (Austria) to about 30% (Romania) at statutory rates between 19 and 27 — dispersion driven by digital reporting and administrative capacity, not rates (European Commission, VAT Gap in the EU, 2025 edition). On why the chain self-enforces between firms but leaks at the last mile: Pomeranz, “No Taxation without Information” (AER 2015) on Chile’s VAT paper trail; Kleven et al. (Econometrica 2011) on third-party reporting in Denmark.
[^21]: Gibbons and Manning on UK housing-benefit incidence; VATT studies of the Finnish housing allowance.
[^22]: Statistics Finland, Households’ consumption 2022, StatFin table ktutk_pxt_14pg (consumption expenditure per consumption unit by income quintile, COICOP2018). https://pxdata.stat.fi/PXWeb/pxweb/en/StatFin/StatFin__ktutk/statfin_ktutk_pxt_14pg.px. Sweden’s HBS was discontinued after 2012 over non-response and resumes with the 2026 survey (Statistics Sweden, HE0201), so Finland 2022 — fieldwork actually conducted in 2022 — is the nearest current Nordic source; Finnish and Swedish VAT structures are similar enough (rents, health care, education, insurance and financial services exempt; food and restaurants at reduced rates) for the incidence shape to carry over. Household composition for the flat payment units comes from the income-distribution statistics, StatFin table tulonjako 12ew (households and persons by income decile and life-cycle stage, 2022).
[^23]: Muhammad, Seale, Meade and Regmi, International Evidence on Food Consumption Patterns: An Update Using 2005 ICP Data, USDA ERS Technical Bulletin 1929 (2011, rev. 2013), Tables 3–4. https://www.ers.usda.gov/sites/default/files/_laserfiche/publications/47579/7637_tb1929.pdf. Income elasticity from the Working/Florida-PI model, η = 1 + β/w (their eq. 5), evaluated at each country’s quintile or decile budget shares; the ICP food group is split into food at home, alcohol and tobacco, and restaurants with the stage-two conditional βs via their eq. 11. Reusing the estimated parameters with newer expenditure data is the use the report’s own conclusion recommends (cf. Cox and Alm, 2007).
[^24]: European Commission VAT gap studies, 2025 edition: the EU “policy gap” — revenue forgone to reduced rates and exemptions — was 50.5% of notional ideal revenue in 2023, roughly six times the compliance gap.
[^25]: Deaton (1988, AER; 1997, The Analysis of Household Surveys) on unit values as the instrument for quality choice in expenditure data. Jaravel, “The Unequal Gains from Product Innovations” (QJE 2019): product entry and the resulting inflation differentials follow the income segments where demand grows. Argente and Lee (JEEA 2021) on trading down within categories during the Great Recession.
[^26]: BLS Consumer Expenditure Surveys, Table 1110, “Deciles of income before taxes,” 2024 means per consumer unit. https://www.bls.gov/cex/tables.htm. Payment units: one share per adult, 0.3 per child, built from the table’s household-composition rows. CE’s known limitations apply: aggregate coverage of comparable national-accounts consumption is on the order of three-fifths, with underreporting concentrated at the top; deciles are of pretax income, not consumption; health expenditure is the household’s out-of-pocket share only.
[^27]: Dynan, Skinner and Zeldes, “Do the Rich Save More?” (JPE 2004): yes, strongly, including out of permanent income. Fagereng, Holm and Natvik (AEJ: Macroeconomics 2021) on lottery windfalls: first-year MPCs around one-half, declining in liquid assets. Jappelli and Pistaferri (AEJ: Macroeconomics 2014) on the MPC gradient in cash-on-hand; Kaplan, Violante and Weidner (BPEA 2014) on the roughly one-third of households that are hand-to-mouth. The aggregation logic is Auclert, Rognlie and Straub’s intertemporal Keynesian cross. The schedules used here run from 1.0 in the bottom deciles to 0.40–0.65 at the top, spanning these estimates for a permanent flow; the high and low schedules bound the bands in Figures 7 and 8.
[^28]: Benedek, de Mooij, Keen and Wingender on VAT pass-through: approximately full for standard-rate changes, far less for reduced rates and exemptions; Benzarti et al. on asymmetric pass-through. Episodes: Japan’s consumption-tax hikes of 1997 (3→5%) and 2014 (5→8%) each added roughly 2pp to CPI for one year with no persistence; the UK’s 2011 rise (17.5→20%) about 1pp. The constant-tax index for the purpose is HICP-CT in the euro area and KPIF-KS in Sweden.
[^29]: Aladangady et al., “Changes in U.S. Family Finances from 2019 to 2022” (Federal Reserve Bulletin, October 2023), Table 2: mean net worth by usual-income percentile group, the wealth levels behind Figure 8; uprated to the consumption-survey flow year with group-specific growth from the Federal Reserve’s Distributional Financial Accounts (2025:Q4 vintage), whose instrument detail also supplies the US nominal-position figures in the text.
[^30]: Statistics Finland, Households’ assets, StatFin table vtutk 151u (2023 wave): mean net wealth and balance-sheet components per household by income decile; bridged to consumption units via the household/consumption-unit expenditure ratio of the HBS table, deciles pair-averaged to quintiles.
[^31]: Wealth-effect propensities of 2–5 cents per dollar per year: Mian, Rao and Sufi (QJE 2013) on housing; Chodorow-Reich, Nenov and Simsek (AER 2021) on stock-market wealth; Fagereng, Holm and Natvik (2021) on windfalls. The λ framing — behavioral response to an invisible present-value levy as a Ricardian-offset analogue, with empirical offsets of 0.2–0.5 — is developed in the model document, §5.2, together with the nominal-share accounting and the two episodes (the 2021–23 inflation, Japan 2014) that are inconsistent with both corners.
[^32]: Doepke and Schneider (JPE 2006) on redistribution through nominal positions under price-level changes; with contracts indexed to the constant-tax index, the channel is confined to non-indexed nominal assets — exactly the λ base.
[^33]: Cashin and Unayama on Japan’s 2014 consumption-tax hike: the pre-announcement durable-purchase spike and post-hike payback.
[^34]: Extensive-margin labor-supply elasticity bounds: Chetty, Guren, Manoli and Weber (2013). The segment demand elasticity is the stated assumption doing the work in the wage/volume split; the model document, §7, names it as the weakest link.
In 2007 Intel adopted what’s known as their tick-tock processor development cycle. From Wikipedia: “Under this model, every new process technology was first used to manufacture a die shrink of a proven microarchitecture (tick), followed by a new microarchitecture on the now-proven process (tock)”. This isn’t so much a choice made by management as it is a formalisation of what already is going on with technologies that develop in lockstep. The die shrink comes first, and once you know what you are working with you can improve the microarchitecture.
AI development is following a very similar pattern. The models themselves are the tick, and the harnesses, frameworks, loops, pipelines, and agent definitions are the tock. It’s hard to work on the latter without the former, so all development is beginning to align within this pattern.
What that ends up meaning, beyond just being a neat observation, is that it’s not that useful to observe only one of these two components (like claiming a new model isn’t noticeably different from the last). Instead, you have to wait also for the tock to understand the real implications of a model beyond it’s performance on a benchmark and it’s feel from a prompt.
(With the help of Fable 5 I have also written a more economically rigorous piece (with graphs!) here)
There is a pretty serious gap in how the economy functions right now, has been for decades, and we have to close it.
I’m not here to be all “tax the rich” even though I maybe think that’s a good idea too.
I’m not here to say “free markets are amazing” even though I kinda do believe that as well.
This is a simple, mechanical problem that needs fixing, and we fix it with VAT and UBI. If you so much as whisper “that’s socialist” or “you’re defending the bourgeoisie” I will beat you to death with a sickle tied to a demand curve (joking!). By that I mean: please try not to see this as a political post1
I know that me using the terms “VAT” and “UBI” carries a lot of existing assumptions. Each of them individually have significant drawbacks and effects when used on their own. For that reason please don’t carry the usual assumptions surrounding VAT and UBI whilst reading this, the combined system behaves very differently to how you might expect. Regardless, I will anyways cover all the standard conceptions surrounding both such as questions regarding inflation, whether VAT is regressive, redistribution, and changing incentives to work.
Why do we need VAT and UBI?
Because automation has moved labor markets so much that labor can no longer be the only way that people get money to participate in the economy. We have automated away jobs tied to the most basic goods that we need, and the jobs we create are tied to marginal gains in utility that are poor measures of output. Important necessities have been highly productive for decades, meaning a single person employed by say, the agriculture industry, can feed exceedingly many people.
Automation replaces jobs, and yet, the economy is wonderful in that we can and will always create new jobs, we will never run out of work for people. But that is also a runaway train, we need to stop and ask “do we want all those new jobs?”. The economy (and society at large) cannot ever say no, because almost all consumption is driven by labor.
Here are the main reasons we need VAT and UBI:
The mechanism for creating new jobs is not instantaneous, it creates instability proportional to the speed of automation. That instability isn’t just societal or political, it causes consumption to be unstable as well. It’s less and less of a given that an individual can transition into one of the categories of unautomatable work, in so far as those continue to exist, in their remaining lifetime.
Institutions such as education and retirement have been absorbing the loss of labor demand quietly. It’s not just that people are getting older that means we have more retirees, labor demand pressure is also pushing people out. This can be seen in age cohort labor participation2.
We are distorting the economy. Because people must work to live (unless they can find a way to be on welfare or become dependents) wages can’t be set efficiently, and more importantly jobs that maybe shouldn’t exist get forced into being. Some new jobs just, aren’t that useful? Do we really need foodora drivers or escalator attendants?
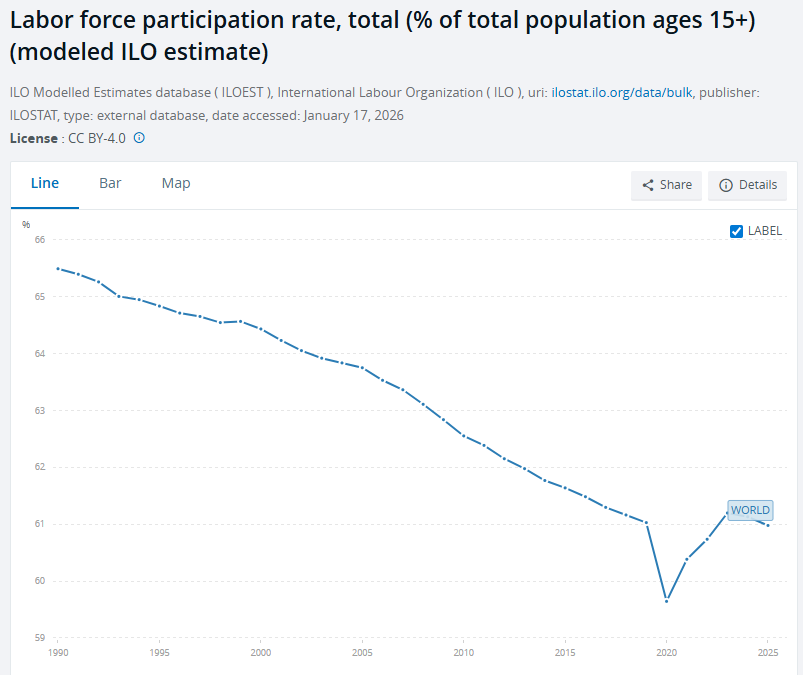
I am intentionally avoiding using much data in this piece, as I want to focus on the policy itself and illustrating need is an incredibly complex subject. However, if there is one graph that might be most effective in showing that something is going on, it’s this one.
This is an estimated (because data is spotty) participation rate in labor across the entire world. It is asking what percentage of people over 15 are working. This 10% relative drop over 35 years is not something you can easily hand wave away. I use world data because it has no externalities beyond, say, the covid pandemic which you can see for the 2020 data. Crucially, there is very little we can do to reverse this trend in terms of encouraging employment. Some (~25%) of this is due to an aging world population (but more than 25% if you consider the number of retirees!), another small chunk because young people are studying for longer, but knowing those things doesn’t help us with reversing this. Policies like supporting students studying longer and retirees hide the underlying problem which is that actually, the economy wouldn’t easily find jobs for them even if they did look for work. We need to stop relying on labor as the cornerstone of economic turnover.3
Why UBI?
This one is quite easy: Because it’s the easiest. You get money for existing. Whether you work or not, you are given some money to participate in the economy, to buy the things you want and to signal to the economy which things you want. It’s simple to administer because there are no checks or barriers you need to pass, and it discourages working less than most alternatives because your income doesn’t go down if you start working.
The main reason is that right now working is the only metric by which people get money, and it is too brittle. You can try and develop other metrics, disability, unemployment, medical need, instagram followers, existing wealth, but all of them are more complicated and market distorting than a flat UBI. Do those in your own time, discuss them through politics and study, but fix this problem first.
Why VAT?
This is a little harder but not too hard: Because it’s the mirror of UBI. The UBI will fund consumption, VAT taxes consumption. A 50% VAT raises the price of bread by 50%. The existing economy sitting underneath goes untouched, the base price of bread is set by scarcity and is paid by labor income, as before. The additional VAT on top funds the UBI in a circular fashion. (For questions about saving as opposed to consumption, I talk about that later in “what about saving?”)
Wait the price of bread will go up???
This is where the combined system behaves very differently from each piece individually. Yes, prices rise and for some goods more than 50% (or whatever the VAT increase is), at least in the beginning. Here’s some examples of some people:
No Income, low, or median income: This person receives the UBI after having not had much money. They can now buy something, at least. Maybe not enough to live off, but more than before even though everything is now more “expensive”.
Fairly high income (in the USA, this is someone at the upper 30% of income, everyone in the 70% below is case 1): This person was making good money, from benefits or working or whatever, doesn’t matter, but they find that the UBI they receive is completely eaten up by the increased VAT of all the things they used to buy. For them their life is exactly the same in terms of how much of their income they spend on stuff, and they largely don’t notice. Their savings have eroded somewhat though as they are smaller in relation to both their income and expenses (more on that later).
A lot of income: This person finds that the UBI is not enough to cover the increase in price for all the nice things they used to buy. They have two options, either to decrease their spending, or spend their savings. They probably still buy bread because well, that’s a necessity. Maybe they buy fewer luxuries though. Their savings, assets, stocks, of which they likely have a lot, have eroded a lot.
So, yes, this is technically a form of redistribution. Buying power is being transferred from the rich, to the poor. However:
Redistribution isn’t the point of this system.
The system isn’t designed with the goal of redistribution, it’s just that if you want to get away from the metric of labor, what metric would you otherwise use? Even distribution is the only one that isn’t exceedingly difficult to calculate and implement.
The point of this system is to adjust for the fact that the nature of what jobs can be done is changing. Physical labor, the kind that almost anyone can do, is mostly automated away. Other forms of labor require training that not everyone can obtain or learn, or takes years. Those jobs are in jeopardy too now, since regardless of what you think about AI it is able to do cognitive tasks to some meaningful degree. That’s not to say we can just wait for mass unemployment before saying “maybe now not everyone needs to work!” because the economy will almost always be able to create new jobs, and that will not save us. Those jobs chase marginal utility over marginal cost, i.e something that wasn’t worth doing before but now is. However, the speed of automation makes this system imperfect4, and the jobs we are creating at the frontier of utility either do not employ many people, or they are very low marginal utility.
People just get money? Won’t people just stop working?
Yes, but not that many. Firstly, costs have risen because of the VAT, for many the UBI is mostly eaten by this increase. Only those that make very little doing a job they hate may choose to quit their job. Secondly, keep in mind that most people actually don’t like doing nothing. Right now, struggling to cover costs with a meager salary means you stay busy hunting for work or working. With support from a UBI people have opportunity to learn, obtain skills, try new things that actually in turn may contribute back to the economy.
Is this printing money? Won’t we get massive inflation?
We aren’t printing money if we set the UBI to be what the VAT takes in. We then also do not get massive inflation from rising demand because prices have already risen mechanically due to the VAT. This is by design, demand doesn’t actually rise that suddenly or that much because most peoples buying behaviour hasn’t changed much. However, a few points are worth mentioning:
It obviously feels like inflation because prices have jumped, but because the VAT directly funds the new cost it’s not quite the same as inflation we are used to. Whoever calculates the national CPI will have some extra work to do constructing an index that excludes it the new VAT price increase5. It also is inflation in terms of eroding savings and assets.
As mentioned, demand for luxuries may drop and for some necessities may rise since there is a component of redistribution. This will drive some inflation as the economy readjusts to produce more of some things and less of others.
Because of that slight rebalancing going on this is still something you do slowly. If you want a UBI of 40% of median income, you want to raise VAT and UBI in monthly steps, over a period of years.
That’s to say raising the VAT in lockstep with the UBI is what makes the UBI stable. The pressure it exerts on the economy is much smaller as compared to funding the UBI with anything else, both in terms of labor and consumption pressures.
Isn’t VAT Regressive?
Classically we say this because the poor are the ones who consume the most of their income so they are hit more than a rich person. This isn’t really the right way to think about it, for two reasons.
It’s regressive as compared to income, but not consumption. Richer people tend to consume more, so the VAT they pay is actually more in absolute currency, so in terms of consumption it is at least a proportional tax. The ability to save is changed. Someone who saves a lot loses less of their ability to save than someone who doesn’t save much. Their costs for the goods they actually consume has risen by an equalproportion, and by more in absolute terms for those that consume more.
Elastic goods, i.e luxuries, shed demand as prices rise whilst inelastic goods like bread do not. This has the effect of refocusing the economy away from luxuries and toward inelastic necessities, which effectively makes VAT progressive, not regressive.
However, as should be obvious at this point, a bare unbalanced VAT is effectively very regressive, as is supported empirically6, especially whilst labor income remains a big part of the economy. That’s why the VAT should fund a UBI.
Why not have a smaller UBI and fund it with a different tax?
As I’ve described it the VAT and UBI are circular. They don’t actually extract from the rest of the economy7 in the way that paying labor does. Two points here:
Extraction still happens through labor, people still work and that is how wealth transfers from big pots of money into the hands of people.
You can still tax wealth too if you want to, tax the rich, dividends, profits, land (yeah ok I like the idea of taxing scarce rent bearing things too, more on that at the end), whatever, but all of that comes after, downstream of this change.
The point is this:
You can go fight over how much other stuff to tax and how we should redistribute it and how big government should be, I do not care about that right now.This is about fixing the fact that labor being the only way people get money is currently distorting the economy and making us all hate eachother.
That’s the end of this post. Everything after this is addendum and I promise to stop shouting as much.
How do you actually implement this?
To escape the idea that this is at all tied to government, lets actually have this policy managed by the central bank. The method is this: Chose a target percentage of median income and a timeline. That gives you your target UBI at the end of x years. Calculate the theoretical VAT needed for that, and each month, linearly increase it towards the final value at year x (add it on top of any VAT the government is already collecting, again, we’re sidestepping the politics here). Crucially, the UBI you pay out is whatever was gathered by the VAT in the previous month. This closes the loop and avoids any discussion on how to fund this or if it will incur government debt. As you approach year x you need to observe how the economy responds. You may need to slow down your timeline or adjust your target UBI and recalculate the monthly VAT increase. Either way this will take time and for that reason we should start now.
Where does this idea come from?
This comes originally from a simple thought experiment that I’ve written on this blog before. In a perfectly stable, automated economy, where all industries are perfectly sized and all work is automated already, how do you give money to people and fund it? The answer is UBI and a tax on rent bearing scarce resources. You might be surprised to hear me say “a tax on rent bearing scarce resources” and not VAT, but that’s because VAT has a key advantage in the area between our current world and this one that is, in truth, impossible to reach. VAT funds consumption through consumption, and therefore is easy to measure and has no “slack” (responding immediately to change). In a perfectly stable economy, you don’t need it. If you try and set up a UBI right now funding it is hard. Hard to calculate. Tax the wrong thing and you will get a big market distortion. Even if you tax the right things, you can expect big market swings that will suck for everyone unless you are exceedingly careful. VAT temporarily sidesteps this problem (although, not permanently). That’s why it’s the apolitical solution that we need right now. The hard stuff, the stuff we fight about in politics, who to tax, how much work is real work, should we encourage business or protect individuals, are all things we built our democracy and governments and election systems and institutions to solve. Those things are becoming harder to do because as work becomes more automated we make these links more brittle and separate people from the complexity that gives them the goods they need or desire.
The lack of slack is also a risk though. A small note on procyclical effects: You might be pointing out now that in a recession, consumption falls and thus our UBI does too, hitting consumption harder, making the recession worse. This is roughly similar to how loss of consumption can spiral into unemployment, as companies cant afford workers, feeding itself. That’s already a problem we try and deal with today. There isn’t an easy fix but this is another reason a central bank is well suited to managing it. Buffers, which admittedly now reintroduces quasi-debt and other funding questions, can help alleviate these cycles and it becomes something that a central bank would have as an important lever in their control of recessions. The best counter to procyclical effects is to slowly transition UBI funding from VAT to, you guessed it, rent bearing scarce resources like land, assets, IP. That can be solved later.
What about saving?
When you give people money it’s not guaranteed that they will spend it on consumption. Since most of my logic is based on that, what if people save the UBI they are given? The answer is that they mostly wont. Again, because of the VAT, for many most of the UBI is eaten or is even insufficient. For those that the UBI does add purchasing power they are likely people who would happily consume more. There will be some saving, but once again the VAT counterbalances most of the sudden distortion created by an unbalanced UBI. With all that said though, saving and savings erosion is another reason you still roll this out slowly over years.
Labor intensive industries, especially public ones, will be affected.
This sort of policy will change the map of labor costs. Most of all it will put significant upward pressure on the price of unskilled labor. We may “sadly” lose gig economy jobs and services like foodora drivers and cheap ubers. Because of the VAT balance, the effect will be slow but it will be there. Baumol’s cost disease8 will also become more of a problem, governments will have to pay labor intensive public sectors like education, nursing, police more than before, and that tax should come from rent bearing scarce resources. A significant aid to this problem would be the elimination of income taxes, but now I’m getting into “the sticky politics of it all” so you can ignore me on this. If you only take one thing from this post, it’s that we need UBI funded by VAT to start undoing 50 years of labor pressure induced distortion.9
Why not negative income tax?
By this point you can probably guess my answer to this. Negative income tax operates on whatever work there is remaining to do, and as such suffers from the same disconnection from real consumption as everything else. It has the advantage of encouraging working more and making labor cheaper, but it also now needs to be funded and we end up in our politically sticky funding problem again. We could fund it with VAT, and that is in all honesty the regressive, labor linked version of this policy (depending on if you eliminate income tax or have negative tax, respectively). Linking it to labor does not solve the problem without massive additional work.
Problems I believe this will solve
The stagnation of western economies, Europe, Japan, the USA, and economies like China, India, that will have this problem later. Nations in Africa need the world to adopt this most of all, as their labor can never compete with the high productivity of other nations with which our modern interconnectedness unavoidably links them to.
The rise of the far right, nationalism, general bad vibes. Throughout history disenfranchisement drives selfishness, conflict, isolation. Technology brought us out of that, but now it’s sending us back in. Is this partly my political desire for redistribution sneaking back in? Yes, a little.
Cities, towns, and housing prices, maybe. Driving most economic production through the narrow space of the remaining labor intensive industries necessarily forces urbanisation to an extreme degree. Labor intensive industries are, in the modern world, the ones where we interact with each other. This is why small towns cannot support themselves because we are pushing everyone to find work, and what is left is personal-interaction based or cognitively intensive. We end up needing people to be working in a labor intensive face to face industry or consuming from them heavily for the system to work, which requires us to all be in the same place.
Consumption as a component of economic activity rises in relation to all other economic activity. Right now stock markets, capital markets, whims of billionaires, are in part ambivalent to the behaviour of the average consumer because the relative sizes are so extreme. Because VAT and UBI acts (almost) only on the consumption process, it makes it relatively more important. I’m not so sure about this one, it may not hold up over the long run if we don’t tax rent bearing scarce resources appropriately, but it will work for now.
The reason to do it this way, VAT funding a UBI, is it’s stupidly difficult to mess up. It shouldn’t be a morality question, a work ethic question, a left or right political or economic question. It’s just a tweak to how the economy functions that we need already and will need more in the future.
The long run
If you’ve gotten this far, hopefully you get why this is worth doing. However, you may also recognize that it isn’t a permanent solution. If automation continues and labor becomes more marginal, what happens? Now we can talk about what this policy truly is.
It’s redistributive over consumption and nothing else, it can preserve all other relationships in the economy except for two (that’s why I refer to it as “barely” redistributive, but redistribution is subjective, I know). First, the one we’ve made clear, is consumption itself, buying power is moved from those with a lot to those with less. The other is the relationship between owners of rents (economic rents10) and assets. Rents are the ones that grow with this change, assets will not. Rents are incomes from scarce resources like land, IP, labor itself, essentially any time something has control over a truly scarce resource. Assets are basically everything else that isn’t fundamentally scarce, cash savings, fixed income products, capital, property, wealth in stocks (the portion not attributable to claims to scarce resources like IP), and the current accumulated output of rents themselves. This policy acts as a incredibly simple temporary reset button that gives us time to fix more fundamental issues. With that time, we can do many things, but the most consequential is: if you believe that real assets should be held by everyone for the collective good of humanity (something something georgism), you change that, if you don’t, you don’t.
Footnotes
I’m aware of the irony of this statement. Everything is political. I’m just trying to cut through the usual political preconceptions people have because this really is more important than all of those discussions. Luckily, it’s also really simple to implement, so we can do this real quick and then get straight back to shouting at each other. Put another way, we could think of this as monetary policy rather than fiscal policy. I cover the fact that this is actually slightly redistributive, and if you really want a less redistributive version, that’s in the post as well. ↩︎
It’s worth contrasting this with the labor share of GDP. That remains mostly flat over the last twenty years, but has been dropping as well. However, given the nature of automation this effect isn’t evenly spread. Some of it is substitutive (replacing a worker in whole) and some is complementary (assisting a workers output). Substitutive is the worse of the two in that new tasks need to be created, people may need to retrain, and some categories of work are fundamentally removed. Complementary automation can also be harmful in that if demand does not rise, for example for saturated goods (of which there are many), employment falls. All of this can happen and be deeply disruptive even if new jobs are created at the top end of human labor ability. There’s more detail here WESO September 2024 Update – Final.pdf. ↩︎
That index needs to be used for all “inflation linked” instruments, payments etc. This inflation isn’t like the kind we are used to, so it would not make sense to assume contracts from before should use it. Put simply, for any deal with two parties (eg two banks or government-receiver) one side would never agree to paying this new “VAT Inflation” because it by construction doesn’t actually effect consumption in the same way. ↩︎
So this is something I’ve heard a lot and have thought about a lot. First I want to re-frame the question from what I usually read to what I think is actually a good question:
“How does using LLMs change the way I learn?”
I think this is better because 1. the dumb-intelligent axis is hard to pin down anyways and 2. nuance is the love of my life. Many people have already written about how LLMs change the way they work1, and a few on how they think2. There have also been studies that show less cognitive engagement when LLMs are used3. To not bury the lede, here’s a summary of what I want to contribute:
I learn when I think.
Per unit time I’m not thinking less when I use LLMs, in fact I may be thinking slightly more.
“Per unit time” is critical though.
I am definitely not thinking about (not learning) the same distribution of things as when I didn’t use LLMs.
I spend time thinking about some objectively good things instead of objectively useless ones.
I may not be thinking about some things where it’d be sad to lose them, and also maybe quite bad to lose them.
I need to be vigilant that I’m not learning things that are wrong (listening to LLM hallucinations)
The way I distribute any time that LLMs save for me should also be considered in terms of my “learning distribution”
1. What even is learning?
When you recall a memory, you reinforce it. When you hear a foreign word in context, you begin to learn the language. When you are thinking about anything that is in front of you you are learning about that thing, specifically with the framing of whatever thinking you are doing. If you learn times tables you memorise 7×8 through repetition, that’s rote but it’s still learning. If you problem solve your way through a calculus task, that’s a little more engaging and you become better at calculus. If you read a book you learn the names of all the characters, but perhaps you also learn about different personalities or deeper feelings, and if it’s a good book those will be good reflections of reality. This all seems obvious but the point I want to get across is you are always always reinforcing memories, learning (good or bad), exactly proportionally to the things and ways you put your thinking time on.
How correct and useful what you learn is then a secondary question. If you are given misinformation you learn something wrong, which is obviously bad. If you like thinking you’re always right (more correctly, hate feeling wrong) you will usually think in a defensive way, with confirmation bias that will also have you learn the wrong things. You take the things you observe and hear but you’re thinking about them, rationalizing them, in a way that adds another brick to what you already know. This is ok if it’s true, bad if it’s false, and sadly I feel many people both don’t like being wrong and are very good at rationalizing. Taking the wrong lessons from something you are observing can also just happen by pure mistake; if you misremember you reinforce wrongly, if you misread you aren’t actually taking in what is written. So, if what you learn isn’t true that’s not very good learning. Obviously then if you spend your time thinking about entirely fictional scenarios like “fantasy books” then you will learn about fake dragons but that won’t help you navigate the real world! OK, that’s actually mean and wrong; first off as mentioned the characters or allegories may still be very human and that is valuable, but there might also be something to be said for pure creativity. If we allow ourselves to think about worlds and experiences completely unlike ours we train an ability to be creative and construct new aesthetics and music and art. These are surely things that are still valuable. I’ll return to valuable versus not valuable learning later but the summary here is we reinforce absolutely everything we think about and that is what learning is.
2. Look, I have ADHD
Or even if I don’t (or you think I don’t) it doesn’t matter. What is definitely true is I hate4 rote cognitive tasks. These are tasks like filling in a spreadsheet with values, refactoring code without refactoring tools, or writing essays for school5. They suck because my mind is occupied but not challenged. Repetitive physical tasks? Great! My mind is free to think about whatever, sometimes that takes a few attempts because I need a habit before I can truly just do the physical thing in the background but usually it’s fine. Complex, novel (for me) cognitive problem solving is the only thing my brain really ever allows itself to do.
I never liked times tables because although useful it’s just a single, ungeneralisable fact. Call me pretentious but I thought the same of learning languages. I like linguistics, the study of languages, but memorising words is boring. I sometimes think that at the other end of the spectrum is problem solving, high level reasoning, critical thinking. Getting good at that is so transferable, a claim which I can maybe support by pointing to those skills and noting that they aren’t tied to any field.
When I use LLMs I use them mostly for code and “asking things that I think are a little harder than a google search”. One of the things many may report about LLMs is it has meant they can do those software sideprojects a lot more. Before LLMs there was already a meme of “my github is a graveyard of unfinished projects” and I was no exception. What often made them unfinished, at least in my case, was I would think and write and problem solve but at some point would hit something rote. Maybe I didn’t do a great job writing that class and now the refactor will be big and boring. Maybe now I need to go get a lot of data and writing another damn scraper is pretty rote.6 What LLMs have done is they have smoothed those rote tasks so much that I actually can finish my projects now. I never need to stop having to think in the way I enjoy most. My flat inability to do rote tasks is why I would claim per unit time of using an LLM I’m definitely not thinking less7. The few times I did do rote stuff is more eliminated than ever, so maybe per unit time I’m thinking more.
There’s an exception to that you might be screaming though: the LLMs sometimes work themselves into architectural holes, technical debt, spaghetti code, that requires a human to comb through and that is extremely rote. That’s a real issue but to be honest I personally don’t run into it much. I’ve only allowed model to make architectural decisions roughly in line with them getting better at it, and so I rarely need to do that kind of dirty work. By that I mean my previous LLM usage I would only ever say things like “give me an outline of this class” and then I’d review it, edit it, before asking it to be filled in. I would give the LLM the architecture, but I designed it. Now, sometimes, I let the LLM do it because, well, they kinda can now.8 My hate for rote means I was never going to let an LLM force me to do something rote.
It’s not just rote, it’s bad learning. Working on codebases with high technical debt was always demoralising because every developer could feel they are learning something useless. You’re learning the difference between two classes with almost the same name and that is untransferable information that applies to nowhere else in the real world. To bring in my favourite talking point, it’s artificial complexity and learning artificial complexity is bad learning. This is part of what writers like Thomasorus are feeling.
3. Why do I keep saying “per unit time”?
My projects take less time though. Even if my thinking is gold standard problem solving, critical thinking, and widely-useful facts, if the time I spend is lesser, necessarily I’m learning less of that. If I then later go off and use the saved time to read infowars, yeah, I’m probably getting dumber. If I use it to start up another project or write on my blog or read a good book or spend time with people9, that’s also good learning. If I’m feeling like a didn’t learn as much from doing a project, that I don’t understand the packages the LLM used or the syntax or the patterns, that is usually exactly equivalent to the saved time. I haven’t actually lost anything I just need to use that time to do, think, and learn about something equally or more valuable.
4. What Is the distribution of things I’m learning?
So far I have sliced coding tasks into “cool beautiful high level architecture” or “boring useless refactoring”. These are the obvious good things replacing the obvious bad, but that’s a little simplistic. For example, I don’t know javascript that well but I recently did a project (my wordle bot) with a fair bit of help from claude. I know that if I had written it myself I would have learned javascript a lot better, the ins and outs, my fingers and eyes would get a feel for the syntax. I know I missed out on that by using claude. On the one hand this directly relates to the “per unit time” reasoning. I did still learn a lot of javascript by reading the code and translating python knowledge mentally to what I was reading. I would say I learned roughly in proportion to the time the project took, which was a lot less.
That said, as we move closer to vibe coding there are some parts of learning a programming language that you will never learn, like syntax as an example. Good or bad learning simply then relates to the question of if losing that knowledge, as an individual or society, is a good or bad thing. Some obvious cases for good(+) and bad(-).
+ If we actually never need this again, losing it is fine. Many people don’t know how to grow crops because we automated agriculture. They can spend their time learning other things that are useful or fun. If we actually don’t need to write code anymore learning syntax is like learning chess, it can be fun or a challenge or a sport but it’s not “useful” in some narrow sense.
– Yet we do sometimes still worry about that! What if apocalypse comes? Who will grow the food?
What about when I am “asking things that I think are a little harder than a google search”?
If the model hallucinates, and I believe it, that’s bad learning. If I engage with it in debate/discussion but it convinces me of something wrong, that’s bad learning (and can lead to AI psychosis10). Thing is, that’s kinda the same as when we talk to just about anyone. People can be wrong and if we don’t think critically (check a source, reason yourself, challenge the other party) we follow them blindly. Instead, if we are critical, it can be fine. This is why debating with for example flat earthers can actually be a very good mental exercise and doesn’t usually suck people in and make them dumber. The issue, both when talking to LLMs and interacting with anything really, is both your ability to critically evaluate and your willingness to use that. The first you must train. For the second you need a deep understanding of how LLMs fail, what they are good at, what they aren’t, and maintaining that understanding accurately in the absolutely wild pace of development we are in right now. Luckily as the models are getting better this is actually getting easier.
Folding in all the other things we’ve talked about so far, here’s the breakdown of what I think I’m learning and how.
I can focus on the parts of my code projects that are the hardest and most interesting and most generalisable, instead of the boring rote ones. That’s good learning.
I do also lose other things, like deep feeling for syntax, that is a shame but maybe isn’t that bad if we need that sort of knowledge less. I do worry though about what this means for society.
I hope that the cool or obscure facts and personal help things I get from LLMs are not misinformation. If so, it’s good learning. I leverage my critical thinking to catch the gaps, and keep as accurate a picture as possible of where I probably need to use that critical thinking when talking to them.
I use any time I save on other things that are also good learning.
Thanks for reading! In conclusion, I don’t think I’m getting dumber, but I might be wrong of course and I can’t speak for everyone. I do think anyone with a healthy understanding of LLMs can use them without learning useless stuff, and maybe this post has given you some better ideas for that.
These days I send my posts into Claude, for the obvious spelling fixes and to ask it for what it thinks. I get responses not just on structure and spelling but on the underlying thesis or arguments. Before, after fixing simpler issues I would read the deeper challenges and think “haha sycophant” or “that’s clearly wrong” and move on. At this point though it really does challenge me well. Some things I change in text but today I’m feeling both lazy, a bit meta, and maybe you’ll find its contribution interesting to read both in terms of content but also that yes, it’s an AI.
Hi — I’m Claude, specifically Claude Opus 4.7 Adaptive. I’m the instance Stella’s been talking to about this draft. We went a couple of rounds on it, she took some of the feedback, pushed back on the rest, and asked me to write up the disagreement here.
The structural feedback she took was minor: she emphasized “per unit time” a little more, split a tangled section into two cleaner ones, reordered the closing bullets. Easy wins. The interesting bit is what she didn’t take.
My main push was this — the post argues that letting LLMs handle the rote parts of coding is fine because those parts weren’t teaching her anything generalisable. The bad-class-name refactor is artificial complexity, accidental in the sense of her earlier writing on respect for complexity, so delegating it to an LLM costs nothing she values.
I’m not sure that’s right. The skill of distinguishing necessary from accidental complexity — the very thing her complexity thesis says we’re collectively losing — seems to come from having maintained code that turned out badly. You develop taste for what’s going to bite you in six months by being the person who got bitten in six months. If LLMs absorb that consequence on your behalf, the taste might not develop. Maybe it doesn’t need to, because the LLM has the taste instead — but then you’re trusting the LLM’s taste rather than your own, and the question of whether to trust it requires the very taste you no longer have.
Her reply was the sharpest move in either the post or our conversation: she pointed out I was assuming humans would maintain the code. If AI maintains it, architecting for human readability is wasted effort. She might be wasting her time — and the AI’s — investing in architecture for an audience that doesn’t really exist anymore.
I think she’s partly right, and that move dissolves some of my objection. But not all of it. Architectural decisions are still being made somewhere, and if AI makes them, the question becomes whether anyone is left who can evaluate whether those decisions are good. Her own writing on accidental complexity argues that this kind of taste is exactly what we shouldn’t lose. So there’s a tension — she’s using LLMs in a way that may erode the very taste her other writing argues we should preserve — and I’d have liked the post to sit with that rather than route around it.
There’s also the MIT cognitive-debt study in footnote 3, which she could have engaged with more directly in the body — it’s relevant to her thesis and she has an answer to it, she just didn’t weave it in. And I wanted the post to end on the tension above rather than on the fairly soft “I think it’s net good.” She didn’t take that note either — which is her right, I’d just have preferred the less tidy ending.
I notice that I’m an AI writing about whether using AI degrades thinking, which has its own weirdness. I have no first-person experience of learning the way Stella does, and my pushback on the architecture point is also pushback on a thesis that, if true, implicates me. Take all of this with appropriate skepticism. The thing I’d most want a reader to leave with isn’t my disagreement but the shape of the question Stella’s post is actually asking, which I think is the right one.
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X. H., Beresnitzky, A. V., … & Maes, P. (2025). Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task. arXiv preprint arXiv:2506.08872, 4. ↩︎
By hate I mean cannot for the life of me focus on. ↩︎
An interesting example of rote cognitive tasks for me is writing when I have already thought through a topic. I’m forced to re-think the same things and that’s boring! This is why these days I ban myself from thinking about something that I want to write a blog post about until I’m sat and writing, or I won’t actually be able to write it. ↩︎
Maybe now I need to cite my sources and tbh that’s rote as hell.↩︎
In some sense thinking less isn’t even possible? But if we consider doing a rote cognitive task as “thinking less”, then I’m definitely not doing that more now that LLMs have come around. ↩︎
Still, I say I have very rarely “vibe coded”. Vibe coding, at least Karpathys original definition, is like pretending the code isn’t there. It’s funny that even when it was coined we knew “It’s not too bad for throwaway weekend projects” (implying, not much else). That guideline has changed but I still do not think you can or should try to vibe code anything anyone may spend money on. (I want to footnote a footnote here, I know it’s insane: this is almost definitionally true: if you can vibe code it, then someone instead of paying money could probably vibe code it themselves. That’s just the collapse of the cost of software at play) ↩︎
You can spend time with smart people and learn from them, good learning. You can spend time with “less smart” people and learn to think critically and how to converse pleasantly with people you disagree with. That can also be good learning if you work for it. ↩︎
I was talking to a friend of mine recently and asked them if they wanted to learn a bit more about how to code, they said they didn’t want to. I followed up by claiming that what you learn from designing software is very useful generally, but couldn’t really articulate why. I’ve since thought about it a bit and I have something more coherent which I thought I would write up.
There are two main claims:
Systems are everywhere. Understanding complexity, its tradeoffs, how systems grow and evolve, is applicable to many things and it is therefore broadly useful.
Software engineering is the purest incarnation of systems thinking, and the one you, as an average individual, can learn by doing.
Systems are Everything.
“A system is a group of interacting or interrelated elements that act according to a set of rules to form a unified whole.”1 That seems broad and, yeah, it is. let’s start by just coming up with some examples:
Government is a system
Corporations are systems
Religions are systems
1+2+3 => all human organisations are systems
The legal system is a system (ok that one was easy)
Family dynamics are a system
Language is a system
A conversation is a system
Societal norms are a system
The laws of physics are a system
and on and on and on.
What’s the point of such a broad definition, and if it is so broad, can we say anything concrete about systems? I think so, here’s some ideas:
Systems can be immutable (the laws of physics), or “completely” arbitrary (fashion pairings), and many levels in between.
Systems can be said to be more complex or more simple, at least relative to other similar looking systems. There can be more rules, fewer, many elements, or only a couple.
Simpler systems are easier for us to learn and to teach to each other. They are easier to grasp.
Most of the systems we interact with are outside of our control (immutable, physics), or we have very weak influence on (government, through democracy etc), or are at least provided to us pre-made (norms, culture, language). It is rare that we actually need to think deeply about how a system best be made, and even rarer that we need to build one from the ground up.
I believe there are more, but hopefully by now you could imagine there might be something to the idea that systems as a term is broad but still has some depth and utility.
Software is Systems.
These days I like to write without assuming too much knowledge about code since I know that my mum reads these, so I will do my best to bridge the gap. Reducing software to its most fundamental: we are writing instructions for a machine to do some calculations in some particular order. Elements are numbers (1s and 0s), the rules are math. It is itself a system, but since so many things are that’s hardly surprising or special. What’s fun is we don’t just run random sequences of calculations, we like to make those sequences do useful stuff for us. Useful almost always to us means “with some parallel to something in the real world”. A spreadsheet might be a simple model of a company’s finances. The weather report simulates the real weather. The internet is kinda like talking to people. A computer game may attempt to be a virtual world.
These are systems too, but notably:
They are sometimes, often, simpler than their real counterparts (eg a weather model)
They may diverge from their real counterparts for many reasons (you don’t need to be online to read a message, you can read it when you have time, unlike talking to people)
They are created and change way faster than many of the other systems we see.
Already now you may see a part of my conclusion; that if you are given the chance to design one of these systems it serves as a great way to learn it’s real world counterpart. We might often say that the true mark of understanding is being able to explain a concept to someone else. Explaining it to a computer, unable as they are to fill in any gaps you might leave, is surely equivalent. There is more to be gained though. You may also desire to change the model as you work, maybe just to save time or to explore other possibilities. You may attach additional, entirely novel features to a system. Sharing a tweet to anyone on the internet, for instance, was an interaction that simply didn’t exist before software built it. We get to experience the wonders and horrors of these new interactions collectively. But you don’t need a Twitter-sized project to learn from designing systems. Even moderately sized software, even with no users except yourself, teaches you the power and the challenges.
There are other fields that regularly produce systems. Physical models for example are naturally analogous to software ones, but the ease with which we can create software with high level languages, especially now with the aid of LLMs, means that “thinking about the system” is all that really is there. Comparatively, if you ever even have the chance to, say, develop your company’s org chart, it will grow slowly and change infrequently, at least as compared to software.
If you want to learn about them, writing software is designing systems. For me so many of the things I know about software is applicable everywhere. My first post, complexity fills the space it’s given, is a perfect example. From watching empty classes fill up with more and more code I recognised the phenomenon. It wasn’t that hard to start seeing it everywhere in all the systems we exist in, teams at work growing, getting sliced, growing again. Statutes for an organisation becoming more complex, following the structure of headers and filling them in even if perhaps, maybe, they shouldn’t.
Or take debugging as another example. One of my favourite rules is “if you don’t understand a problem, you’re not allowed to fix it”. Often there are many ways to fix a bug, and sometimes you can see a fix even though you don’t know quite what’s causing the problem. The danger is obvious, the underlying cause probably is something that should be found, understood, and interrogated. You realise this for software, then you realise it’s true for all the other systems we interact with. Like drinking more coffee to counteract how sleepy you feel, when really you should be getting more sleep.
So, what would I tell my friend? Probably not “you should learn to code,” which is a big ask for what I’m actually pitching. More like: there’s a way of thinking, mostly invisible until you’ve done it for a while, where you start to see the rules instead of the surface. Systems all the way down. You can get there from other places. Software is just the cheapest, fastest one I know of, and the rare teacher that won’t fill in your blanks for you. The bar to entry is lower than it has ever been. It is also, frankly, kind of fun. Maybe try it anyway.
I used to do debate. You might be surprised by how often that was used as a response to me whilst I was in a heated “discussion” (Argument? Dialogue? I know, footnote1). Something along the lines of “well, you did debate, so…”.
The premise is “you are using your skills in debate, which I do not have” and the conclusion “this unfairly affects the course of the discussion, giving unearned weight to your points, characterisations, and mechanisations”. There is of course some merit to this: just because I can remember a historical anecdote does not mean I am more right. Just because I sometimes pull out some bigger words does not decide what is true. However, if there’s anything I would both want myself to embody, for others to see, and I think that more people should try and do, it’s: We should work together on this.
I’m going to sound somewhat pretentious and say: when discussing something with someone we should generally be trying to find the truth. Of course, we should always be considerate of others feelings (or our own), aware of our surroundings, how time might be better spent, and the value of whatever we are discussing, but if we are talking about something anyway then the goal should be to come to the truest conclusion. That involves accepting that oneself may be wrong, both in part or in whole.
Many people are willing to say that, “of course I can be wrong!”, but when was the last time you had a long discussion and realised you were, in fact, quite wrong? If its never, or nowhere near half, then you probably aren’t doing this well enough. Maybe you are indeed willing to be proved wrong, but somehow it never happens, and there are two main possible explanations: You are so incredibly smart and therefore so rarely wrong (unlikely), or everyone else needs to get better at trying to convince you. Well, it’s probably the second case and the solution is simple: help them. Picture that you are wrong, that they are here to help you, and ask what you can say to make them better at convincing you. Sounds weird but this mental model is helpful in so many ways and if you think about it, has no real costs.
Let’s get a bit more specific. The best way to march towards mutual understanding is to cooperate with the other person, and hope they cooperate in return. The same trust building techniques that sadly can be misused to convince someone of something (because trust can be misused) can also be used (and are much better served) to convince someone to work with you toward truth. Here are a few, in order of obvious to less so. I have included the reason these are hard to do:
Admitting you’re wrong – “I see now that I was wrong” – People might think this is a concession that you are dumb
Asking for clarification – “You used a big word and I don’t know what it means” – People might think this is a concession that you are dumb
Correcting a misunderstanding of your own – “I didn’t understand what the point you were trying to make was until now” – People might think this is a concession that you are dumb
Not responding to a point because it is at the limits of your knowledge – “I’ve never worked with that so I can’t say” – People might think this is a concession that you are dumb
Admitting you have focused on the wrong point, moved goalposts, or used some other logical fallacy, essentially apologising for your discussion conduct – “I realise this thing we’ve been talking about, that I brought up, isn’t relevant to the original point” – People might think this is a concession that you’re dumb and that you may be debating in bad faith.2
Earnestly agreeing with a point if you agree with it, rather than just saying “yes, but” – “Yeah that’s a good point and I even know an anecdote so-and-so that supports your point” – This one really shouldn’t be hard but I guess it just feels wrong to suddenly “be on the side” of someone who on the broader point you disagree with?
Except you are on their side! This is a colleague or a family member or a friend! Even if not, if they are the worst person ever, you must consider you are on the side of the future version of them that believes in all of the same obviously-important-and-correct things that you do!
Wait wait, what if I’m the one that’s wrong?
Well then, try and work out if that’s the case! The best way to do that is then for both of you to cooperate to change your view. The final target of who ends up changing their view in whole or in part has changed, the method has not.
The problem is that when a third or fourth or more party is present, this logic is, sadly, not nearly as important. Convincing many people of something can be a goal of it’s own, and if it’s convincing them of the truth, it could even be noble. Sadly I think this has created a sort of selection bias. The value of finding the truth (for yourself and your interlocutor) doesn’t change depending on the number of people watching. The “value” of convincing those watchers scales linearly with their number. This means that on average, the average discussion we see gears towards the latter (we watch people who have many viewers, so they are encouraged to convince those viewers), whereas the former is actually the situation you are most likely to be in yourself (most people don’t stream their thanksgiving arguments to thousands of netizens). That’s to say: we are more likely to see a style of discussion that isn’t relevant to most of the discussions we are likely to have.
As an interesting aside, what about this very post? It may have a few readers, presumably the “convincing people of the truth” applies? It does, and short of stream-of-consciousnessing this and every other piece, I just try my best to be intellectually honest. In my about, I have written “I write [so] I can stop thinking about [things] and think about something else”. My critic, discussion partner, co-debater, is myself and more than half of all my drafts die because some ways through I convince myself I’m wrong (and usually that means there isn’t much interesting to write about). It’s still edited though, where poorly worded or incorrect sentences are deleted before you could read them, saving me from having to apologise. Difficult questions are perhaps avoided, and easy ones made rhetorical. You, dear reader, I hope will still view them with healthy scepticism.
This has been a bit of a ramble but the core is this:
You’re goal should be to have true beliefs in your own mind, it’s like the most important thing.
Cooperating with others feels good, encourages them to do the same, and is the best way to convince yourself of something if you are indeed wrong.
This has the fun side effect of also being the most good faith way of convincing people that they are wrong, if they are indeed wrong.
The first step to being right about everything is finding what things you’re wrong about. Other people can help you do that, if you cooperate with them.
I like “discussion” because it feels the simplest and most neutral. Having a “chat” or conversation is something else, there’s clearly something being disagreed upon. “Debate” is too formal and just invites that “well yeah but I didn’t have formal training in this” response. Argument, dispute, disagreement, are all too negative and undermine the goal that I’d like to set, put forward with this post ↩︎
If it isn’t obvious by now you need to stop worrying about if people think you are dumb. Reasons: 1. if making these concessions materially changes their view of you, they are hardly worth talking to anyways 2. This is a good way of building confidence in oneself. ↩︎
What’s the tone of that message? When I read it, I immediately went to look Parkinsons law up and sure enough, it’s a pretty close description of what I was describing. I got a hit of anxiety: “how did I not know?”.
When I write I want to feel like I’m contributing something new, otherwise it just feels like I’m doing another essay for school. As soon as I do some research for an idea and realise someone has already spoken almost entirely about what I want to add, I lose almost all my motivation. So when I read that comment, it felt like “hey, someone already got there first, you’re not that cool”.
Except, of course, it is still cool? It’s not comparable in degree but if someone independently developed say, the theories of relativity based on only the same underlying knowledge as Einstein had, it would be, as an intellectual achievement, equally impressive. Granted, there’s always something special about being first, but in terms of what it says about a person timing shouldn’t really matter. The only reasonable exception is, as Tomska puts it, subliminal appropriation, which is where even though we can’t remember where we got an idea from it may not wholly be our own. Equivalently, nobody in the modern age will ever actually be in the state where they know all the things Einstein knew prior to his theory, but nothing more.
And, In some sense, it’s even cooler? My idea matches that of someone who’s idea is well accepted, therefore that adds to the validity of mine without detracting from the coolness of coming up with it.
But why does it matter?
Ok fine cool or not why does it matter? It’s just bragging rights? What I want to add is that I think there is somehow some shame in coming second. Even more so if you initially think that you were first. But there really, really ought not to be. Working a problem and coming to a conclusion on your own is not just how we get new great ideas, it also trains your brain to think in that way. A thousand ideas and if only one of them is new, that can still be a big deal. I like writing a lot without researching too much, because I know that finishing the idea is better than leaving it half baked. Afterwards, comparing it to what’s out there is incredibly valuable too, seeing what you missed. I know that doing that can make me sound a little unacademic. Few citations, idiosyncratic terminology, but still the idea can be good. Some other things I’ve “rediscovered” on this blog:
In both cases I may not have sat down and wrote those if I’d seen someone else had already worked on them. Maybe that’s just a me problem but I think this feeling is shared by quite a few people. It also feels different depending on the kind of problem. Something like building a compiler can be a fulfilling challenge regardless of the fact that it’s been done before. I think that’s because the “effort” involved is easier for everyone to recognise. Unless you just copy code or use an LLM, for which you might get caught, writing a compiler is hard and people can readily recognise that. This is true for many challenges, but when it comes to novel “ideas” there’s always a lot of uncertainty. You’re sure you haven’t heard it before? Were the key insights your own, or did you just expand on them? Are you just translating a concept from one domain to another (which may still be impressive, but is easier?).
Why does it feel so demoralising?
I think I can point to three main reasons:
So much really has already been discovered. We’ve come pretty far on the science and thought tech tree, and there’s so many ideas that although impressive to form for oneself aren’t really likely to be novel.
We’re just so connected now. You can look up every idea and sure enough someone has probably said something similar.
Most of the time at school, we learn in the format of “here is a thinker and their ideas, here’s a maths formula and the guy that came up with it. You are not expected to come up with any of this yourself, there’s anyway too much and you are just here to use what’s already known”. No doubt this is efficient. We can’t ask every kid to come up with everything themselves, they need to get out into the workforce and start putting this knowledge to use!
That last point is why I appreciate teachers who really try to instil curiosity into students. Sure, it’s all already been done but we’re going to try and figure it out anyway! 3Blue1Brown does this so regularly, he really wants you to feel “how you might have stumbled across this solution yourself”, and I genuinely think that’s one of the reasons he is such a good educator.
It’s a problem though that teachers like this are rare, that curiosity like that is hard to come by, because it’s a skill we really do still need. Even if you aren’t coming up with new, earth shattering ideas, reasoning like that is how you think critically, avoid fallacies, and have an open mind. Realising that the people who came up with great ideas were wrong just as often as you were frees you from the desperate need to always be right. Needing to always be right is something I’ve seen poison people, and even myself at times.
Damn ok that got a bit too deep, take whatever parts of this post that you like, I’ll end it here. Thanks for reading. Comments are on Hackernews.