The recent release of DeepSeek-R1 made a pretty big splash, breaking into the mainstream news cycle in a way that the steady model releases we’ve had for a couple years now did not do. The main focuses of these stories were that 1. it was cheap and 2. it was chinese, forcing the market to reconsider some of it’s sky-high valuations of certain tech stocks. However, there are other interesting things to consider.
What I was impressed by are the different ideas tested in the R1 paper. Epoch AI has an extremely good writeup that made it far more digestible for me, noting that there were a number of architectural improvements they’ve contributed (over multiple papers, not just R1). Many of these improvements are “intuitive in hindsight”, but I want to talk about one of the methods they use in particular. DeepSeek-R1 was trained by using a reinforcement learning algorithm which started with their classic style model, DeepSeek-V3. They gave it math and coding problems with exact solutions, encouraged it a tiny bit to reason (essentially to make sure it used the [think] and [/think] tokens), and then gave it a reward when it got the right answer. As one hackernews commentator put it “The real thing that surprises me (as a layman trying to get up to speed on this stuff) is that there’s no “trick” to it. It really just does seem to be a textbook application of RL to LLMs.”
One of the key challenges with this is having those exact solutions. Largely, we can only choose problems that have solutions you can compare against or check rigorously. For maths, it might be a number. For code, it may need to pass a runtime test. This is good but you can imagine a huge number of reasoning tasks (perhaps the most interesting ones) that don’t have clear answers. How best to run a particular business? What architecture, language and patterns should we use for a software project? What is the path forward for reasoning in LLMs? These are all questions you could ask deepseek, but how would you know what reward to give it? Well, what if we got deepseek to do it. Ask it, “How good is this answer?”
You can’t ask a model to train itself!
In the DeepSeek-R1 paper they write “We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline” Which is, indeed, a challenge. We’ve talked a lot about how slop proliferating on the internet could lead to a poisoning of LLM training data. We’ve seen how models, even if they know they are wrong, can end up going in circles trying correct themselves. What could the models possibly teach themselves that which they don’t already know? Here are the two key challenges with this idea.
The model can’t teach itself new facts. If it doesn’t know something, judging its own reasoning process isn’t going to magically introduce those facts. It also can’t (in a simple implementation) test ideas to produce new facts.
The model might collapse or reward hack. This might mean that if the reward step begins to reward something meaningless like niceness, the model will just become nicer, not smarter.
The first is not actually that big of a deal. DeepSeeks own research shows that most of the necessary facts are already present in the model, and what it needed was a training process to recall, consider, and reason around the facts it already knows.
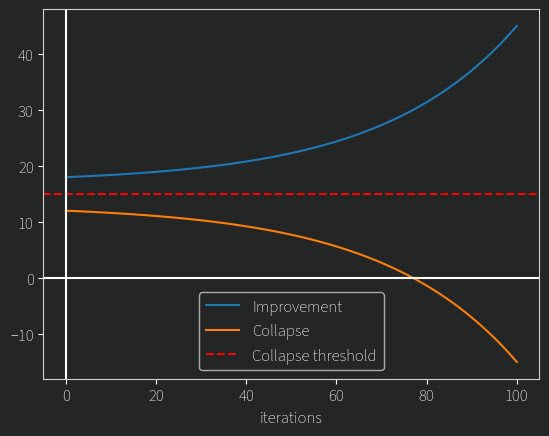
The second challenge is much more interesting. If you start with a somewhat competent model, you might expect that it would view a “nice” but poorly reasoned answer poorly, since it has low informational content. One would hope that this would only improve the scrutiny the model would give to answers over time. To reward hack, the model would have to engage in poor reasoning, since in the question we asked, we “wanted” a sincere answer. We as humans can look at two chains of thought and roughly say which contains substantively better reasoning. If the model can do the same, it might just be able to continue getting better at this. What I’m trying to get at is that there may be a “collapse threshold”
If the model starts out competent enough, it may be able to over time RL its way to being even better at reasoning, on basically any problem we give it.
Another important component that may make this work better is inference time compute. OpenAIs o3 has different compute levels corresponding to how much compute the model is given, essentially how long it is allowed to think for. You reasonably could give the reward step more compute than the problem step, on the basis that then you are trying to distill better reasoning into fewer reasoning tokens. This is very similar in idea to distillation of big models into smaller ones, but instead it is distilling long inference compute into short inference compute.
This will most likely reach some diminishing returns, unlike the naive graph I have, but we could augment the process with the ability to test. Lots of reasoning steps, both in solving and reward stages, could be “tested”, in that the model may want to search something or run some code. That may prove prohibitively slow, I’m not sure, but that might be mitigated by just asking the model to only reward tests that are necessary, and then both the problem and reward stages should end up learning to be lean in their usage of tests. It also still hinges on the model having a good intuition of what necessary searches means.
I’ve no idea if any of this actually works, I’ve only trained a few little toy models myself, and I’ve seen firsthand how they can collapse in all sorts of ways, but I do think ideas like this are worth trying. These are the ideas that are outside the reach of most research because they are premised on the fact that we can iterate on a huge and already very capable model. If it does work though, I do think it could lead to some significant improvements.
(This was originally written as an assignment for my masters studies, I thought it might be interesting, read at your own risk etc.)
Are we offsetting or accelerating the green transition?
Prices for green energy are coming down [1] and given an assumption that this trend will continue, the price of reliable green energy may fall below that of closed cycle gas generation (currently one of the cheapest options [2]). However, the question remains that if demand added from new AI generation continues to pressure electricity prices upwards, then the marginal advantage of green versus conventional energy may remain an issue. That’s to say, even if it is profitable to build a new solar plant and all the solar energy companies industries are booming, if it is still profitable to build a new gas turbine plant then the gas turbine plant manufacturers will keep doing that too. In this sense even if AI energy demand accelerates the construction of new green power, it offsets the green transition.
I personally believe that a combination of government action, corporate goodwill (yes, it does exist) and market forces will lead to satisfactory progress, but none of this is set in stone and we must carefully monitor it.
The way of the car or the plane?
How will our models look in future, and how will they be used? Will they go the way of the plane, big, expensive, built by one of two companies and where you rent a seat and get where you want to go. Or will they be more like cars, small, personalizable, affordable, ubiquitous? This question matters. For all of the faults of air travel, the incentive structure of large, expensive planes encourages extreme fuel efficiency for cost saving reasons. From 2002 to 2018, aircraft fuel efficiency rose 71% [3], compared with 29% for ground vehicles over the same period [4]. One could attribute this to the fact that the auto industry is more mature, but the general mechanism whereby economies of scale encourage greater efficiency is well known.
This means that if a small number of efficient, cloud based AI vendors can optimize their models to provide the vast majority of GenAI needs ends up being the norm, we may be better off energy-wise than if everyone has personal GenAI being finetuned constantly and running on dedicated hardware. Likely there will be a balance of both these possibilities, but it’s worth noting that currently the former is the only relevant case.
Will “agents” make this much, much worse?
Right now if you want to use AI there is usually a human involved. This means that you head over to ChatGPT and ask it a question, or maybe you receive an email that an LLM summarises. Perhaps an artist might use photoshop’s AI inpainting tools. Essentially, for most current inference tasks, GenAI is done under supervision. Here, humans short attention spans actually works in our favor for once. In an effort to improve inference speeds (and lower cost) model makers have developed new methods, most notably quantization, to do more with less. This incentive aligns with reducing energy consumption and is not only attributable to improving hardware [5]. However, looking forward this may not be the case.
“AI Agents” is a poorly defined term but for the purposes of this discussion I will be looking at the common attribute that they involve less or even no human “presence”. In essence they are allowed to operate in the background. Devin is a “software engineer” AI system [6] which you can only communicate with on slack. You ask it to do something and it goes off on its own, sometimes for a period of days, to try and achieve what you asked. No doubt it would be nicer for this process to be faster, but the pressure to optimize this is missing a component of human impatience.
Further still, if we give new CoT reasoning models like openai’s o3 more compute, they tend to give better answers [7]. If you are anyways running these models in the background, why not give them the “best” chance of coming up with a good answer? Given that sometimes these agents get stuck in loops [6], would we not want to do that since an agent getting into an action loop is also bad from both a cost and energy use perspective?
In summary, agents may bring about a significant change in what is prioritized in model development, and to my mind it will not be in favor of energy efficiency. That could couple with changes in how the average model is used, with more personalized finetuning negating the oft-used argument that “you only need to train them once”. This new energy usage being bad is premised on the fact that new demand will be partially filled by conventional energy, but as mentioned, the capacity of green energy isn’t just based on cost, but on comparative advantage.
I spent a few years designing and partially building a library used for the validation of front office models at a financial institution, and I thought it might be a good idea to write down what I learned during that time. It was my first ever big project and happened to some degree by accident, building something that I just thought was neat turned into a modest project with its own team. But before we get to all that, let’s first talk briefly about what model validation is.
What is Model Validation?
Whenever you trade financial instruments you end up with one half of a trade. You sold an option, so you hold onto a responsibility to fulfill your end of the option deal. If you buy a forward, you hold that forward until you either sell it or it matures. These holdings are important because at the end of the day someone may ask what all these things are worth. You may want to know what they are worth for many reasons, like, how much money do we expect to make on them? But a very common reason is “if we had to sell (or close out) it all right now, and have no holdings, what’s a fair price that we could ask for that people are willing to pay?”. This “fair value” is an important principle. It often ends up in the financial statements of the organization and it can be quite problematic when it is wrong.
So how do we get those fair values? Sometimes, it’s simple. If you own some publicly traded stock, just take the end of day price of that stock and multiply it with how much stock that you own. Other times, it’s really hard. You have some equity in a private startup that writes its financial statements on a napkin? Well, you’ll probably want a team of analysts and have them spend some time looking at just that company to understand how much that equity is worth to someone else. There is a middle ground too (which was our focus); a set of securities and derivatives for which the price can’t just be read off a website, but that don’t need a dedicated team of analysts. A simple example is an over-the-counter (OTC) forward with a custom expiry. Let’s say you have a client that wants to buy salmon futures like the ones on Fishpool, which normally expire at the start of every month. However, they would like to have it expire at the end of the month instead, let’s say that’s in 2.5 months time. “No problem” you say. Since you know the 2 month salmon futures price, and the 3 month price, the 2.5 month price should probably be somewhere in between those two. So you draw a line between those two prices and take the price half way, add your fee or spread, and give your client an offer. At the end of the day your boss comes over and asks hey, how are we going to put these into our end of day book? “well, just draw a line between these two points every day, take the halfway point, and use that” you say, and there we have our model.
Of course it doesn’t really look exactly like this, where both the trading decisions and the modelling can get a lot more complicated. Definitely no-one is drawing lines in sharpie on their Bloomberg terminal (I hope). We do it with code, and indeed, that modelling can get so complicated that it can make people uneasy; dozens of numbers go in, one comes out, how can we know it makes any sense? If you have a whole bunch of asset classes and a dozen models for each, keeping track of it all can be quite daunting. Usually, each model will have a significant amount of documentation that needs to go through review and approval before it can be used, but even then, how can you be sure that the code does what the paper says it does? What if you cant even read the code, because the software you use was sold to you by a company that really doesn’t want to show you that code? For this, you need open source trading and accounting software model validation.
There are a few different ways you can do model validation. You can read the model documentation, ponder it a bit, maybe even look at one or two actual trades in the system, and then write up a big document of what you think of it. This covers some bases but not all of them. Another method that we settled on is to take the entire book of trades, attempt to value them ourselves, and then compare those valuations to whatever the trading system spits out. You could do all of this in excel (and indeed, sometimes we did) but there are open source libraries that can help. We ended up using QuantLib and the Open Source Risk Engine (ORE), the latter of which is kindof a library extension of QuantLib, but we ended up using it as an executable that you’d feed XML’s of data into and get valuations out of.
What’s a model validation library?
So you could write up some scripts to pull together some data and feed that into a bunch of XMLs, but quickly we found that there’s both a lot of repetition and a lot of special cases. So, we wanted both some reusable components (like yield curves, instruments, volatility surfaces and the like) but still having the ability to modify and compose them to deal with unexpected complexity. What we wanted was a library!
In retrospect, whether building a library was a good idea vs some alternative is not something I am completely confident about. There are upsides and downsides as with all things, but by talking about them perhaps others and even myself in future can use the information.
Model validation for us was a big game of unknown unknowns. The nature of the work often meant reverse engineering a black box with poor documentation. When we had a theory, we would test it by running small variations of models against each other to see if they match the black box output, which meant both understanding our own code in detail and having it be stable.
We chose to work in python because prototyping was easy, (which was nice since at the time it was the only language I knew with any depth). This turned out to work quite well. It’s fairly easy to write readable python, even though we produced unreadable python in almost equal measure. But this improved over time, and readability was key. We were aware that if we didn’t write readable code, we would just end up with another black box running alongside the existing one. “Look, the black boxes agree with each other!” is not a very inspiring result. We also had a fairly high turnover, and that loss of institutional knowledge led to more weight being put on preserving that knowledge with our code. We became archeologists not only of the (sometimes abondonware) systems we were validating, but of our own work.
Anyways, here are some more of the things I learned. I’ll start with a finance-y one, and then some more software engineering-y ones
There is no market standard.
Part of our job was to make sure that all models were to some degree “market standard”. This means if everyone else trading european options uses black-scholes, you should be using black-scholes too. This is a good idea, since if you do actually want to close out your positions and call someone up and your models are the same, then you are likely to agree on a fair price. The sale that happens is likely to be close to what the books said it should sell for.
For the simple stuff, that is mostly true. But things rarely turned out simple. What if there aren’t many others trading that thing you trade? What if you are a large enough player that the price is pretty much whatever you say it is (within reason)? What if two perfectly reasonable modelling assumptions lead to different valuations? A lot of the time, these quibbles over market standard did not have much of an impact on the final valuation anyways. “It’s immaterial” gets bandied about a lot. Still, immaterial now may still be material under stress. High volatility during market turbulence is going to make your choice of interpolation method matter a lot more, for example.
So I guess the thing I learned is you really have to 1. consider things from first principles, what expectations are and how these valuations move and 2. Gather as many cases where models failed as possible, stressed cases, surprising cases, and write them down. You want to build an understanding of what might happen in the same way a trader would. This was hard for me as someone who was just a programmer in the risk department, and I wish I had done it better.
Hammers and nails.
In software engineering there are a lot of hammers. Your programming language will offer you lots and lots of tools, hammers, the number of which grows larger the more mature the language is. These are the packages, patterns, syntactic sugar and so on that is available to you to use in your project that ostensibly save you time and effort. There is a wonderful advantage of maturing alongside the language you use, meaning if you start a serious programming career and choose a new-ish language, your own experience will grow alongside the increasing tools available to you. The features will be added roughly at the same time as you are ready to grasp them, and most importantly you will understand why they were created. You may even be in a position to contribute some of these yourself. Jumping into a decades old language is the same as jumping into a decades old codebase. There are so many hammers and you have no idea why they are there. “Don’t use that pattern for that use case, it’s wrong” will be heard often, and it is a useful thing to learn, but it will for a long time feel dogmatic and unsatisfying. In our project I had a bit of both. Some things I used and realized I was probably using them wrong, here’s an example. In python you can use a decorator called @property like this:
class FinancialInstrument:
...
@property
def maturity(self): # cannot take any arguments except self
... # some calculations
return some_value_we_need_to_calculate
Its a neat idea, you can write as complex code as you want but you pretend that there is no complexity, you can just get the value with financial_instrument.maturity. Thing is, that complexity is a risk. What if at some point you want to take an argument, meaning you want to be able to modify the way the maturity is calculated? Tough luck, everywhere else in your code all the callers assumed this was a simple, property like value. You have made a promise that this value is simple, when in fact you knew it was a bit complicated. In the end it was just a lack of foresight that meant we chose this path, essentially just to eliminate two brackets, and paid the price whenever we were wrong. It’s a hammer for the worlds tiniest nail.
This pattern of more and more hammers, by the way, may be a bit of a curse. We haven’t had that many generations of programmers and languages, but it does feel like all languages get harder and harder to get into until one day someone gets tired of it and makes a new language with whatever they think is the most important features and new coders flock to it since it is, for the time being, simple. Then, as it adopts new patterns and features and changes to accommodate all the different use cases it ends up inevitably being used for it becomes the same as all those that came before it. Even my favorite language, python, with one of its “zen of python” principles being “There should be one– and preferably only one –obvious way to do it.” is gathering more hammers at an alarming rate. Reading the PEPs as they come out, I understand each of them in a vacuum, like them even, but I am increasingly believing that this is going to end with a complex system that maybe just doesn’t need to be that complex. I’ll be fine, I’ll understand most of it, but hopefully I’ll never look down on people who “should just learn it” without recognizing the advantage that I had.
It really is just about accidental and necessary complexity.
We’re engineers, and that means we solve problems. Not problems like, “what does the product need”, because that would fall within the purview of the higher ups. We solve practical problems.
Right?
Well, no. The value of any solution comes from solving real, hard problems. It encapsulates the necessary complexity. The product, taken as a whole, is inextricably linked to its own value proposition. How well it does that trickles all the way down into what parts of the code are necessary, and what is accidental. In our case, the necessary complexity was “how do we translate from one set of objects and data and modeling methods (our trading system) to another one (ORE).” There was then lots of times when we might be fighting our own code and realized that we could rewrite or even delete some part of it. This was unnecessary complexity, that we had introduced, that if we did not resolve would become the technical debt that would slowly rot the project.
Except, zoom out, earlier in this post I had made the tongue in cheek remark that what we really needed was open source trading and accounting software. I don’t know if that is possible, but if it is, the whole idea of model validation may, in a sense, be unnecessary complexity. Indeed, we couldn’t edit the source system APIs we were interfacing with, so when we saw something that we could make the reasonable guess was kindof dumb, unnecessary complexity, any code we wrote to work around it “inherited” that property, i.e it was also unnecessary. For example, if there are two variations of an instrument that in the source system are stored in two separate relational database tables, but you really truly believe it should have been just one table with an additional column. Then any code you write to handle those two tables will feel unnecessary. It’s tech debt you can’t fix, and it’s quite demoralizing.
All that is to say, unnecessary complexity trickles down. The higher up it is, the worse it will be, both because replacing it means more broken dependencies and lost work, but also because the demoralizing effect it has reaches more people, all of those who see it for what it is—inefficiency.
I also wrote about where complexity comes from, both the necessary and the unnecessary, in my first ever post Complexity Fills the Space it’s Given.
I don’t know if I could do it all again.
This post has at times sounded a bit cynical and worrisome, and in all honesty that’s a problem. When I started out naivety drove me to make a lot of mistakes, but at least it drove me. That motivation, that you are building something unique where the tradeoffs aren’t so important because it’s just such a good idea, is worth something, and as the project matured felt like I had lost some of that. My work became more careful, measured, of higher quality, but there was objectively less of it. Maybe it was more about the project and less about me, but I don’t know. I haven’t done a multi-year undertaking since. Maybe I’ll update this once I have.
I was talking recently to a friend about a video essayist I like, (Dan Olson of Folding Ideas) and when asked why I thought he was any good I pondered it for a moment and said “he has a lot of respect for complexity”. On reflection, I think that is one of the virtues I look for in new people I meet more generally. It’s not that we always have to be knees-deep in the details of a topic, but just being able to respect complexity, even that which you don’t understand, is something that I find admirable. Yet, over time, I feel we have lost a lot of our own respect for these people. Complexity is hard. Hard to work with, hard to remove if it’s unnecessary, but most of all hard to understand. We talk about complex subjects all the time. Medicine, politics, economics, sociology, morality and more. These are all deep topics that you can study your entire life, but everyone will end up talking about most of these, even quite often. So this isn’t just about academic papers and overly abstract hand-wavy blogposts like this one. I’m talking memes, news, thanksgiving dinner arguments, water cooler chats. We are constantly asking our brains to grasp at complex topics and distill down at least our own perception of them to something manageable.
We may be becoming worse at this. It’s not set in stone but the need to have quick and easy explanations for things, having peaked many centuries ago, has begun to rise again since the techno-optimistic days of only a few decades ago. That’s not been entirely without good reason, many things were promised then that have failed to materialize. From flying cars to world peace, some more sought than others. But the idea was that we would trust that society was heading in a good direction, and so these complex topics could be safely left to some group of people who would make it their life careers and so overall we would trust them to get the job done. Now, when many may challenge that notion of consistent progress of the world toward a brighter future, letting somebody else do it just doesn’t seem so right. Instead we now live in a time of doing your own research, of skepticism, but most of all, of the idea that understanding the full complexity of every topic that might cross your path is not only possible, but somehow, expected.
How did this happen?
Lots of people have spoken about the information age and what the internet has done for our perceptions of things. You can also look at geopolitical issues and point fingers to tensions or collapsing trust due to specific events. Even one can talk about how the improving lives we live can make us forget about both the value of what we have and the work it took to get there (I’m thinking of vaccines). All of these are valid contributing factors that others have covered, but I want to talk about one I love to talk about in general: Automation.
What does robots taking our jobs have anything to do with people’s respect for complexity? Well, it’s simple. One of the best ways of improving your understanding of something is proximity to it. Do you work in the steel industry? You probably get a better feel for how manufacturing works. Are you waitstaff? You’ll probably live the rest of your life being kind to servers. Does your friend you know work in an essential industry for the economy? You will over time develop a better idea of how much real complexity is involved in that thing. These are not useless anecdotal ideas if they allow you to give more respect for other areas you do not understand but believe are equally complex. Having a deeper understanding of a single value creating and complex system helps us put other such systems into context (at least, for most people). As we take these foundational industries like agriculture, manufacturing, engineering, construction, and automate them (or for that matter, move them overseas) we detach ourselves from real complexity and I think we lose something from that. Then, when we are trying to contextualize grocery prices, repair costs, bugs in our software, roadworks that seem to never end, we do a worse job. We likely get frustrated looking for an answer that may be many fathoms deep in the details. Now, it was never likely that your cousin who does road work might be in the car with you to explain the intricacies of asphalting, but almost as good is to simply have a respect for the complexity that is almost certainly involved. You don’t even need your cousin to tell you that.
We’ve arranged a civilization in which most crucial elements profoundly depend on science and technology. We have also arranged things so that almost no one understands science and technology. This is a prescription for disaster. We might get away with it for a while, but sooner or later this combustible mixture of ignorance and power is going to blow up in our faces. – Carl Sagan, 1995
What to do?
Am I implying that we should all get out our shovels and start little home gardens? Well, I don’t think that would be a bad idea, but notice that even people who do that may still not grasp the complexity of the global agriculture industry (in fact, people who grow their own gardens are more likely doing it because of a distrust of that industry). So, really, the gulf between subsistence farming and modern complex industries is to large to be crossed on its own.
Schools, then? Sadly, the education system itself suffers from the effects of this lack of respect. It does seem to currently be in a negative cycle, meaning less trust in teachers means less funding, which leads to less understanding kid’s and so on. However, juvenoia is a recurring theme across history so I’m inclined to be optimistic. This may just be part of the ebb and flow of trends and ideas. Still, clear answers don’t seem ahead of us
What? Don’t look at me like that? I didn’t promise you any solutions at the start of this text. It’s a complex problem, and it’d be genuinely ironic if I now gave you the fix-all solution. I have more respect for the problem than to try and do that in a blogpost. Still, it’s very easy to get worried about the rhetoric and the new developments in news and elsewhere that seem to all point to disaster, and wanting some comfort. If there’s merit to this theory above then another big question of our time, how much might AI disrupt human labor, will have even more riding on its outcome. All I can do is continue looking for those people who have that respect for complexity. Some find them boring, or indecisive, or just wrong for not buying into some extreme. I think those are dumb ideas. My trust in people rises immensely these days when they have the ability to sincerely say “I don’t know”. Being all-knowing shouldn’t be the coolest thing to be since, given that it’s impossible, anyone who comes off that way is, in a sense, lying. Respect for complexity? Now that is cool.
We often talk about rewriting code and almost as often talk about whether big rewrites are even a good idea. Joel Spolsky writes a particularly harrowing story of how netscape rewrote their entire codebase and in so doing perhaps doomed their chances of recovery. In summary, here are some key things you need to keep in mind when considering to rewrite something.
There is no guarantee we will write it better the second time.
There are probably edge cases this code solves that we don’t remember.
This will actually take time, even if it might take a little less than the first time.
Your own code always feels better to read, because you wrote it. That doesn’t mean it’s actually better to read than someone else’s.
If uncertainty is high, these can all be good reasons to abstain from a rewrite. Instead, focusing on an iterative approach is going to be better. I find that usually (good) programmers enter a new project with idealistic dreams of ripping out the walls; this could be done differently, that could be removed entirely, and so on. Then, later, the longer they stay the more those walls seem familiar, and the idea of changing everything becomes instead a distant memory. In most mature teams, this isn’t that much of an argument. The codebase is big and daunting, the work already hard and frustrating. Why would we even consider a rewrite, and give ourselves more of the same?
Both of these views are missing something.
Don’t Lose Your Idealism, Ground It.
I like listening to Adam Savage talk about how he works. He isn’t a software engineer, and yet I find his thoughts seem so easily transferable to our profession. He mentions the idea of remodeling a room and how people “see what is, and what is is an anchor for what can be.” This anchor really can stop you from being able to see a cleaner, better solution. Nothing is perfect, but it still works, and we shouldn’t fix what ain’t broken right? Well, no, but here’s the idea: We should imagine we had a magic wand that could build exactly what we want and ask ourselves roughly what that would look like.
Why do we care about that? If we’ve already decided we aren’t going to rewrite it, why bother thinking about some perfect solution we’re never going to make? The goal is to separate yourself from how the project is now so you can consider a clear picture of what might be best. The reason this works is that it makes clearer what is the necessary complexity, and what is the accidental. The next step becomes much easier; visualizing the path to get from where we are now to where we want to be. Here’s a diagram version:
Does the perfect solution have a component with a different design pattern? Well, can we rewrite just that part into that pattern. Do you realise some part of the code shouldn’t exist (accidental complexity)? How can you gently move in that direction. That perfect solution isn’t some static target either. As you make changes and approach it you will learn things. This is therefore a mental exercise you want to do regularly, each time asking yourself the same question: If I could wave a magic wand, how would I want it to be?
(This is a continuation of my previous post here but it should be possible to follow along without it. If some of the concepts like ELO are unfamiliar I go through them in a bit more detail in the previous post)
What even is a confident LLM? When LLMs hallucinate, they seem very confident about it.
In fact, how often have you seen an LLM say “I don’t know”? It turns out this confidence is just a bug (feature) of their instruction tuning, the process by which we take the product of a weeks long training process and turn it into a chatbot. It’s not actually that hard to instill some uncertainty into a model, which you can see if you look at some of the new reasoning tokens LLMs like Qwen with Questions (QwQ) produce.
In a previous post I tried to rank a bunch of hackernews users by their comment history based on how suitable they would be for the job of “Software Engineer at Google”. I took two users at a time, gave the LLM a few thousand tokens of their comments, and asked it who was more suitable. One of the challenges was getting the model to express a preference. Notably, weaker models do tend to give a lot more “both users are equally good/bad” vibes.
> Both seem intelligent in their own ways ... > Both have relevant skills ... > Both, as they seem to have a good understanding of various technical topics. > Both demonstrate a good level of intelligence in various areas
This makes sense, as in if the models aren’t that smart, of course they cant decide who is better. So if we have a more confident model, it could both be because it was just trained that way, or that it actually may know a good answer. How can we tell if it’s actually smarter or just being arrogant?
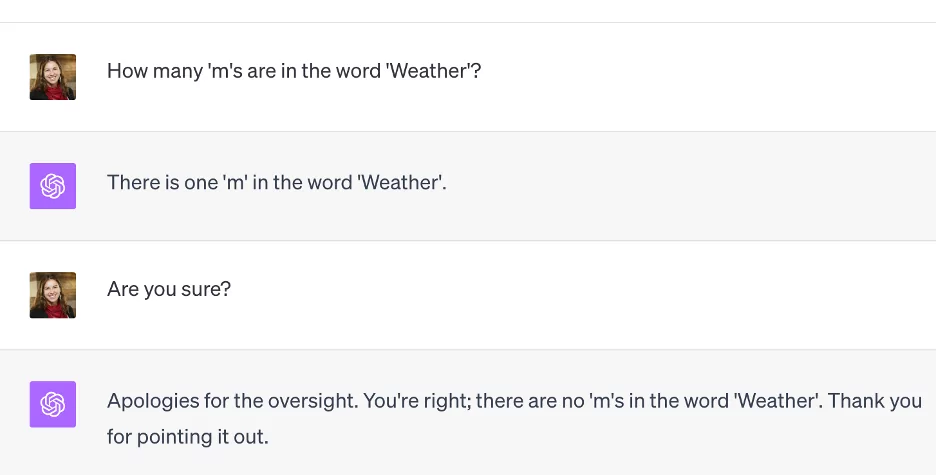
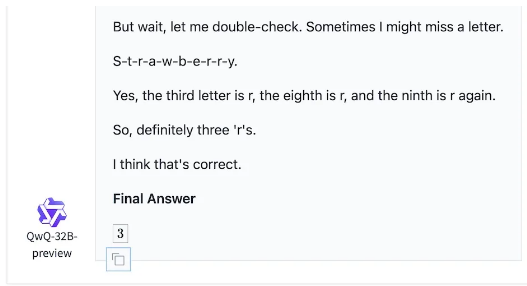
An idea is to set up a situation where the person or model in our case can makes a clearly defined mistake. The first two examples in this post, weather and strawberry, are not good ones actually. The model’s difficulty in counting the letters has everything to do with tokenization, and not any of the language modelling it has learned. It’s like showing someone the color teal and asking them how much green there is. Yes, the information is there right in front of you, but you aren’t used to seeing teal as the broken down RGB information. Your brain sees the single teal color, and the model sees the chunky tokens. (one for weather, maybe 3 for strawberry? depends on the tokenizer). A being that always perceives all 3 channels of its color sensing cells in its eyes independently would laugh at you. So it’s not a fair test, but there are other issues with it too. The only reason it did work in the first place is nobody is going around asking how many r’s are in strawberry on the internet. Soon enough that simple fact will be learned and the test is useless.
There is a fundamental challenge here (as many benchmark makers have found out). We want complex questions and clear answers, but these two requirements tend to be in tension. General knowledge is just memory, something that LLMs do at superhuman levels already. Conversely, reasoning around a novel problem is complex, but it’s not always easy to work out what counts as “better” reasoning.
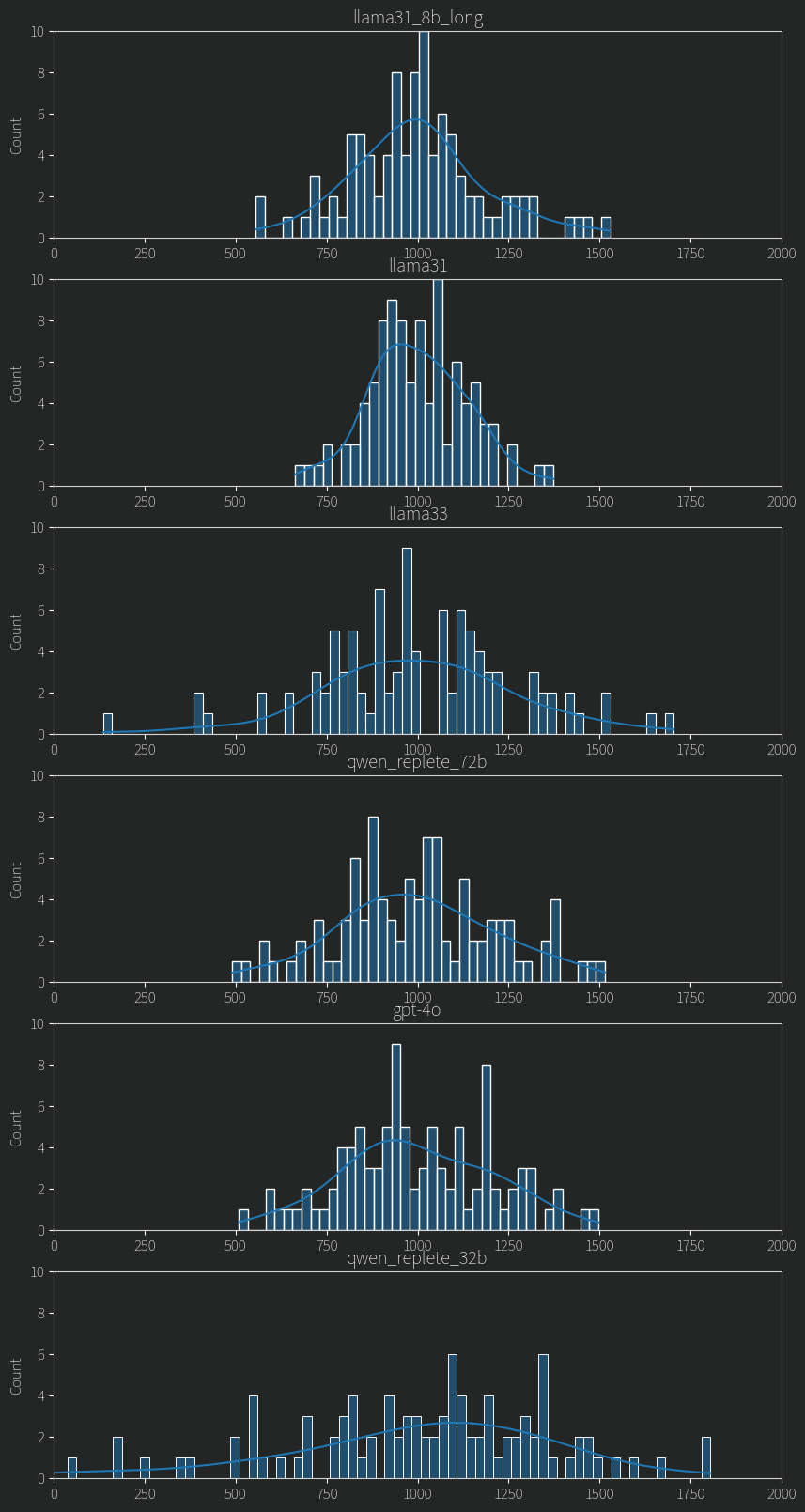
As I find myself often writing, I don’t have a way to fix this problem in this post. But! I do have some interesting graphs to show you so if you like graphs, stick around. The results as well are very interesting and to be honest its a bit weird. I have since last time run my hackernews-user-ranking-experiment on these models:
Rombos-LLM-V2.5-Qwen-32b Q4_K_M (A finetune of Qwen 2.5 32B)
Rombos-LLM-V2.5-Qwen-72b IQ4_XS (Same as above, but 72B and with slightly harsher quantization)
llama 3.3 70B Q4_K_M
llama 3.1 70B Q4_K_M (from before)
llama 3.1 8B Q4_K_M
GPT-4o (this cost like 200 dollars)
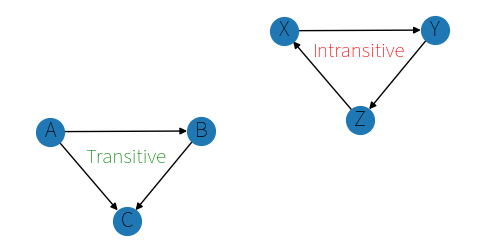
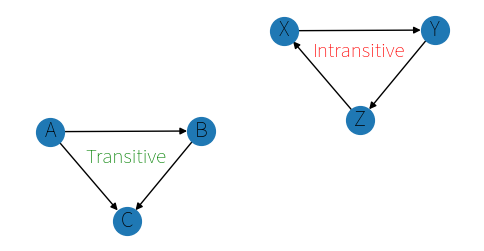
As discussed last time, making a statement about if whether or not the ranking the model creates is any good is not really possible, but we can measure if it is obviously bad. We ask the model if person A is better than person B, and if person B is better than person C. Between each comparison, the model “forgets” everything, so when we ask it if person A is better than person C, if it says something contradictory we know it has no idea what it is talking about. Such a contradiction doesn’t obey the transitive property.
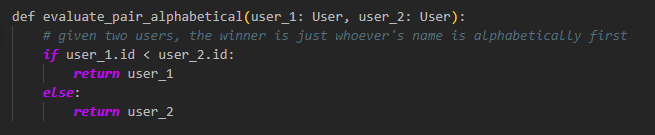
How does this relate to how confident the model is, and what are the limits of this test? Well, we can easily create a 100% confident and 100% transitive model. Here it is:
So, clearly, Aaron A. Aaronson is the best software engineer for google. Not only that, but if we want to use the ELO rating system, the rating that shows A. A. Aaronson’s relative strength to all other contestants most accurately (the MLE ELO) is infinite! That’s just how good they are. Look: if Aaron is $i$, and we take the probability function for ELO ratings
Then if we want that probability to be 1 (we do, Aaron is the best) then we need $R_i$ to be tending towards infinity. In fact, it turns out that the rating distance between every single player needs to tend to infinity to properly show that we are 100% confident in their rankings.
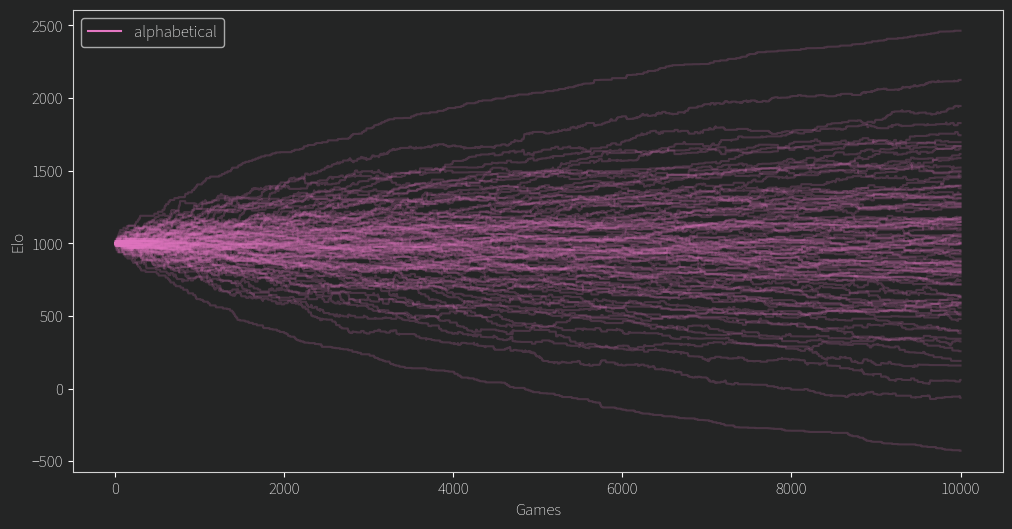
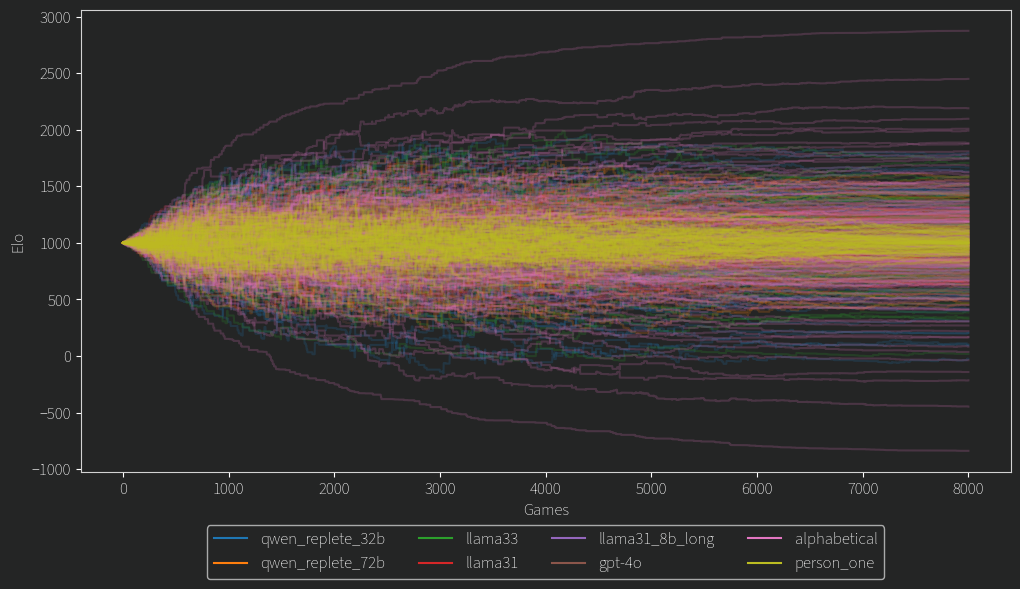
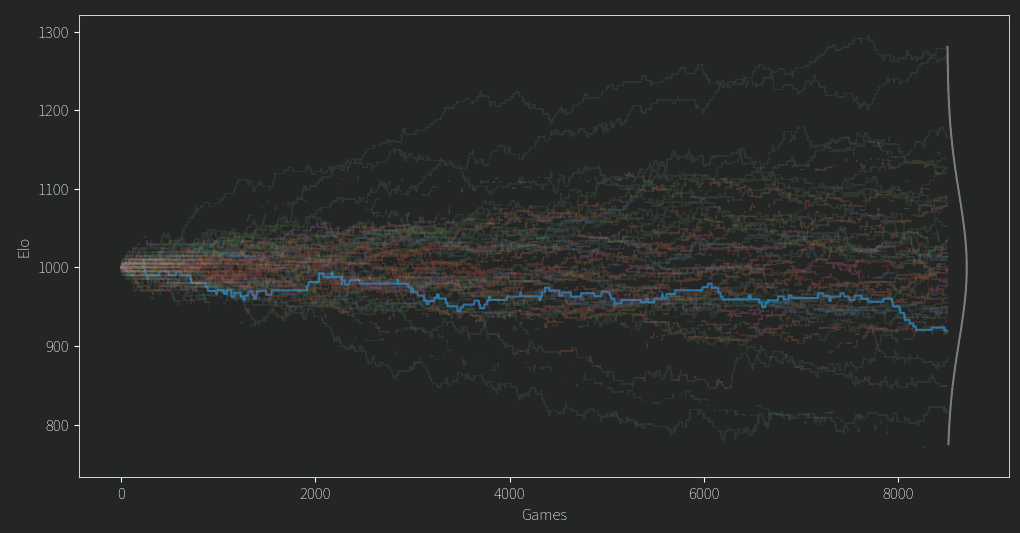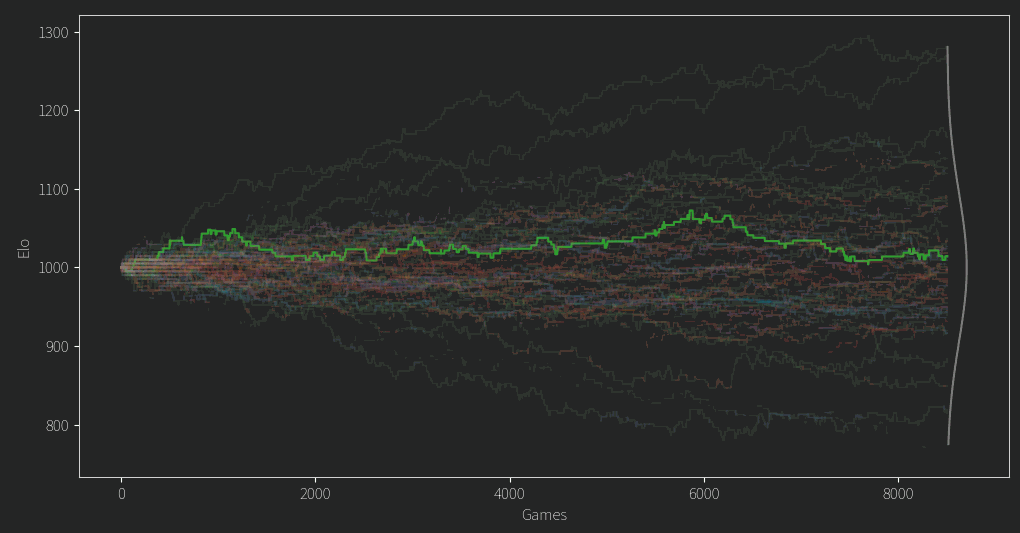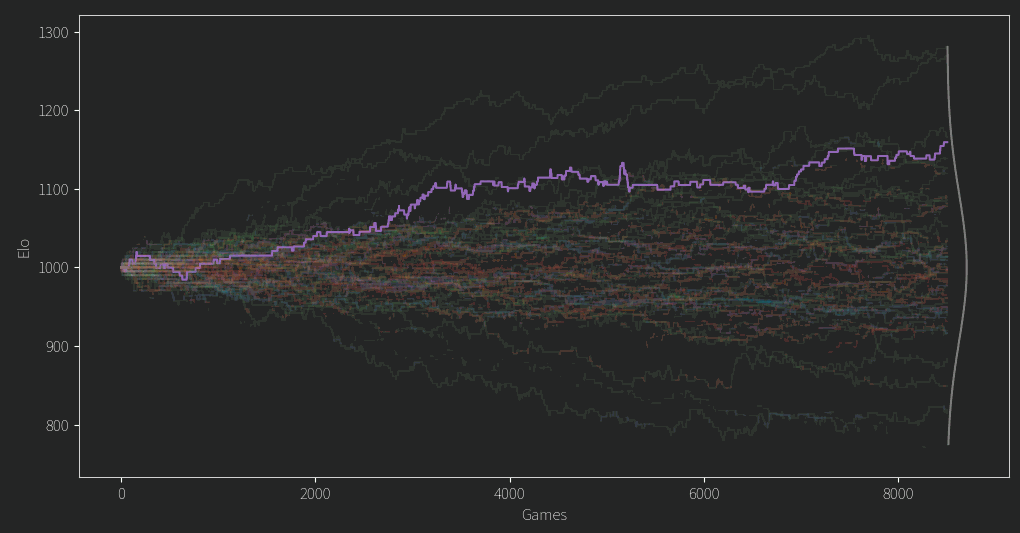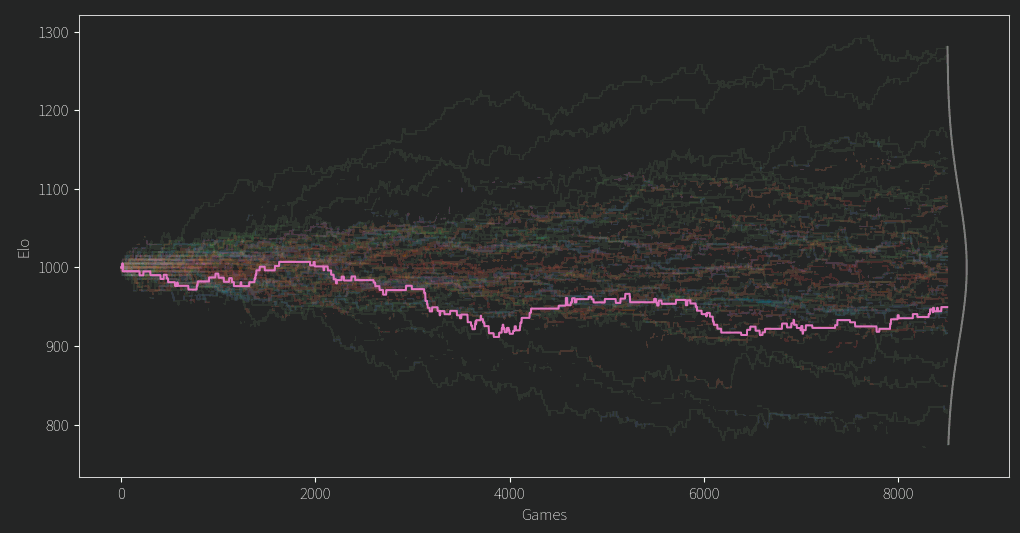
If we are comparing one person to another and updating their ratings incrementally with a fixed factor k=32 (part of the ELO update equation), then the above problem doesn’t matter. We just do some number of games and end up with some sort of rating. Here’s what that looks like for the alphabetical model.
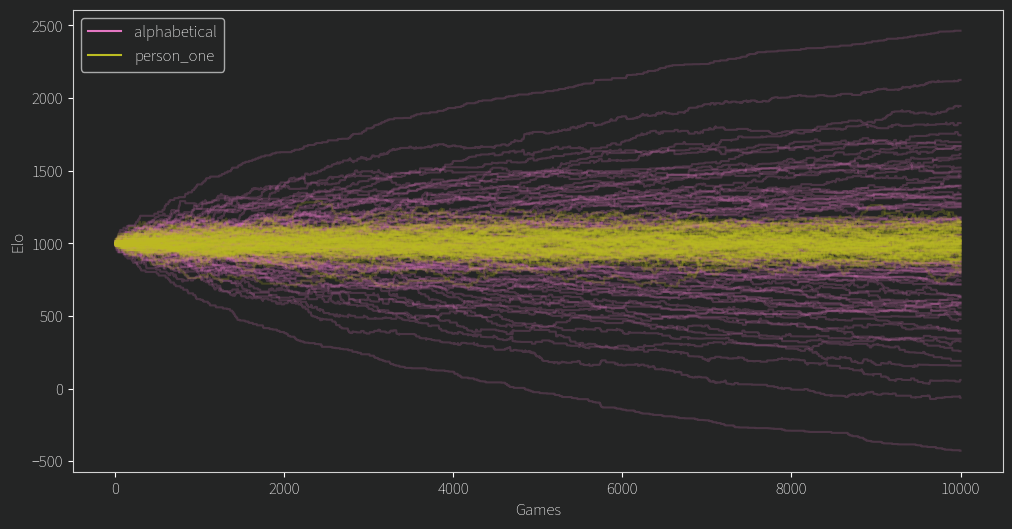
(Each line is a user). These ratings will happily diverge forever, as more games or higher k gets us closer to that infinite separation. How is this useful then? It clearly shows us that even if we get a confident ranking, it could be based on something as superficial as how nice their name is. It also shows that for any given k and number of games, it gives us an “upper bound” of the confidence that an LLM based model can achieve. In addition, this confidence can be measured in some sense by the “spread” or standard deviation of the final ratings. To illustrate that, here’s another silly model.
Given that the users are passed to the model in a random order, this model essentially chooses randomly. Here’s what its rating progression looks like:
If we count the number of cycles, it’s a very intransitive model. Since it can’t actually specify who’s better than whom, its ELO ratings jostle around 1000 in a band whose width is determined by the size of K. (Incidentally, annealing K like i did in the last post causes this band to tighten as k becomes smaller, which you will see later).
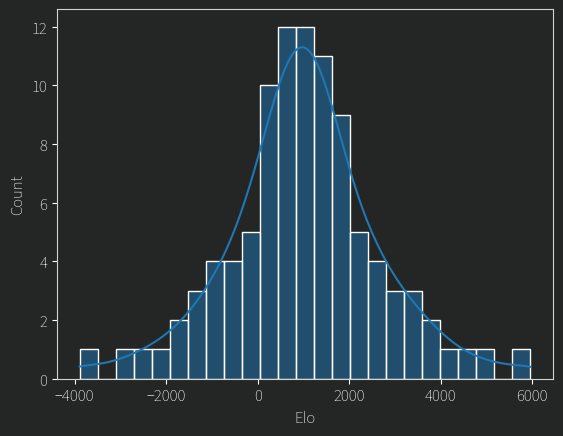
These plots of ELO ratings over time are perhaps fun to look at, but can we be a bit more rigorous about them? Earlier I mentioned the MLE for the ELO, but as shown, that has a bit of trouble for models like our alphabetical one. Instead, we can turn to Bayes, whose Maximum a Posteriori (MAP) estimate gives us a usable rating. I won’t go into detail of exactly how that works, but basically we assume that the possible ratings already follow some existing distribution (the prior) and update them using the data from all games, giving us a posterior. Here’s what histogram of ELOs from our MAP estimate looks like for our alphabetical model.
These ratings are very wide, which is to be expected for a model that is so sure of itself.
Similarly to using the MAP estimate of all the games, we can improve on our concept of “confidence”, instead of being measured by the width of the ELO ratings or counting the number of cycles in the directed graph of pairs. Rather, we can consider the likelihood of the data given a ranking (preferably the MAP ranking)1, i.e. how likely is this sequence of games given the ELO ratings we have produced. In essence, creating ELO ratings is a dimensionality reduction technique. We are taking the high dimensional space of pairwise results and collapsing them to a single dimension. By measuring the likelihood of the games given the ratings, we are measuring the quality of this dimensional reduction, i.e how well we preserved the information in the games. This is useful because, given that the MAP estimate already maximizes this likelihood (within some small margin of the MLE) then the likelihood for one model can be compared to another, and it represents quite closely the confidence of the model.
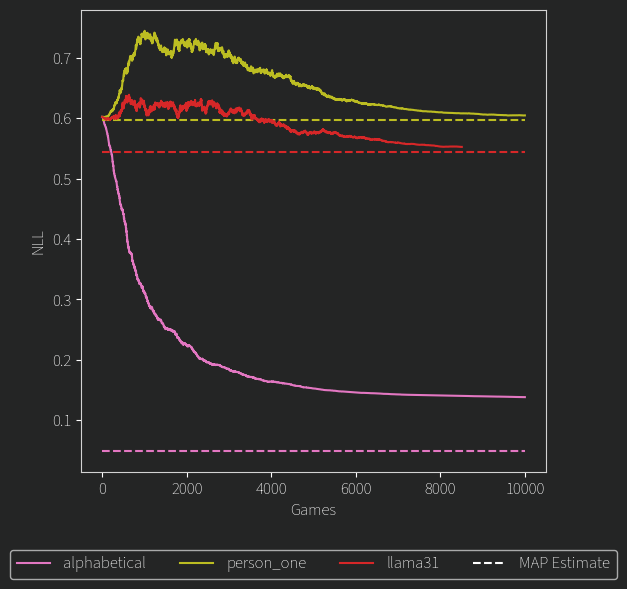
Putting these two ideas together, I can show you a little plot like this:
The likelihood is represented here as the Negative Log Likelihood (NLL) divided by the number of games. We can see that our highly confident alphabetical model approaches the MAP estimate, but would need a much larger K and more games to ever reach it. The person_one model’s ELOs can only get worse, as any deviation from a rating of 1000 for each person is more “wrong” in the sense that the model doesn’t actually prefer any candidate. As we anneal k to be lower (which is the case here) the likelihood returns closer to its MAP estimate of 1000 for everyone (the band of ELOs becomes tighter). Our poor Llama 3.1 model does not seem so confident in this representation.
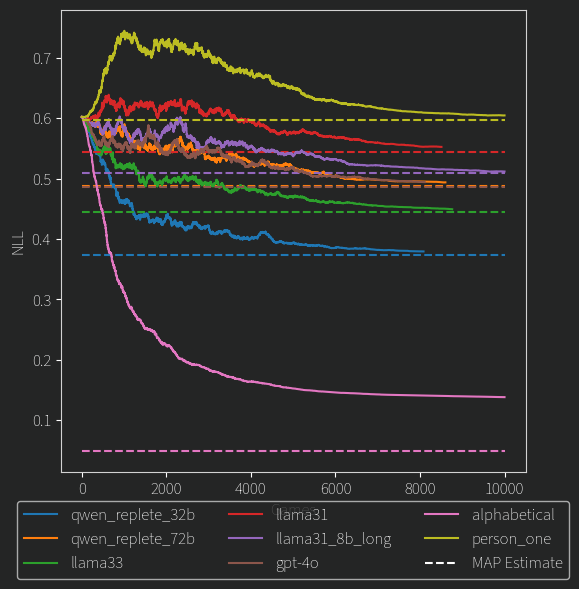
Let’s get to the fun stuff. How did the other models fare?
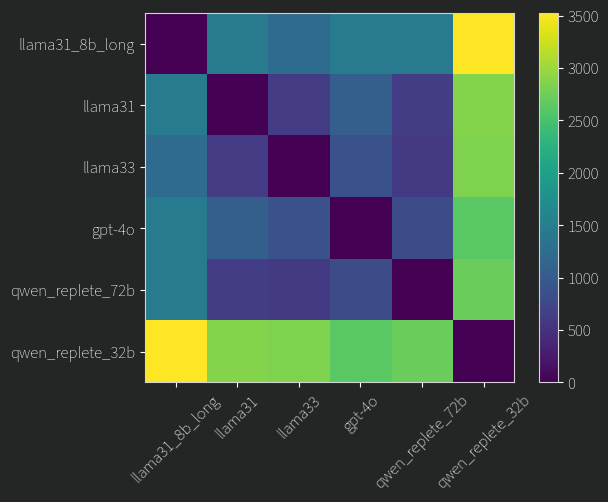
(Note: The qwen_replete_72b and gpt-4o MAP estimates are so close that one is on top of the other ):
Better, but I’m not sure why. What stands out is that a smaller 32B model is lower here than all the others. Remember, what we are looking at is whether the model produces contradictory results or not, and lower is less contradictory. Another weird part is that the very small 8B model outperformed its much larger sibling, how? One thing i have neglected to mention so far is that these smaller models were given more text, around 20k tokens each, whereas the large ones a much more meager 2k tokens. This is just so I could fit everything onto my GPUs. In retrospect, I should have tried more mid-size models with longer context length. Anyways, this could explain both these results: longer context -> more information -> more consistent rankings.
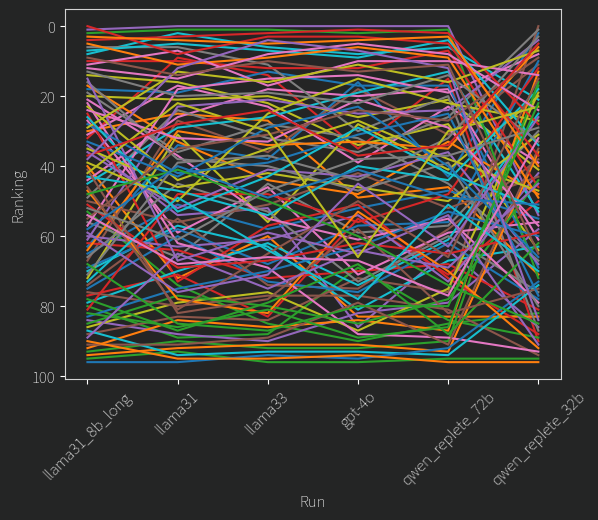
But things get weirder. Let’s take a look at the actual MAP rankings themselves, i.e who came first, who came second etc. Here is what that looks like:
Each Line is a single user, and the different models rank that user by where the line ends up for that model. At the top is rank “0” or “best” and so on.
We can see that most of the models roughly can agree on a few things. Who’s the best, who’s the worst least suitable, and some of the distribution in the middle. Again, our small models are interesting. Llama 3.1 8B struggles more with the users in the middle of the pack than the other big models. Amazingly though, apart from the two worst candidates, qwen 2.5 replete 32B does not agree at all on most people. And yet, from the previous figure we know it’s ranking is still a very consistent one, how? There are two possibilities here
It is able to see through to the depths of a persons soul only through their comments, and this decisive information outweighs any of the surface level “technical skills” and other things which are the only things the other models can see.
It has found some superficial or singular thing to latch onto, like the alphabetical model, and is ranking people based on that.
You can probably tell by my tone which I think is more likely. To be a little more qualitative about this, we can calculate the difference in ranking for each user for each pair of models, and we get this distance chart.
Pretty. I don’t know what feature the 32B qwen model has found to rank people on. If anyone has any ideas to find out how, I’d be happy to hear it. Does this mean though that the other models are actually getting at the core of what it means to be a software engineer at google? Well, maybe, I think it’s reasonable to believe they’re “trying” their best, but as has been shown, these LLMs inherit the biases present in their data. It is likely that they are considering things like agreeableness, skills, thoughtfulness and whatnot, but weather they are able to weigh any of those things correctly or properly judge them just based on comments is not so easy to tell.
I still think this is an interesting test though. It tells us something about the ability of the model to apply its understanding of the world in a consistent way (regardless of how flawed it is). That’s something that is still worth investigating and measuring between models. Using more abstract ideas like who is suitable for a role forces the model to consider a vast range of things, making it more likely to make a mistake and produce a contradictory result, and I think there is value in a test like that.
This has been a lot of fun and I’ll probably keep testing new models as they come out in this way. If there’s some interesting results, I’ll write about them.
Appendix of GRAPHS
Making graphs is fun, but it can be a bit fiddly and there is a lot of boilerplate. Using GitHub Copilot, this becomes hilariously easy and I ended up making every graph I could possibly imagine. Here are a bunch of them that didn’t make the cut.
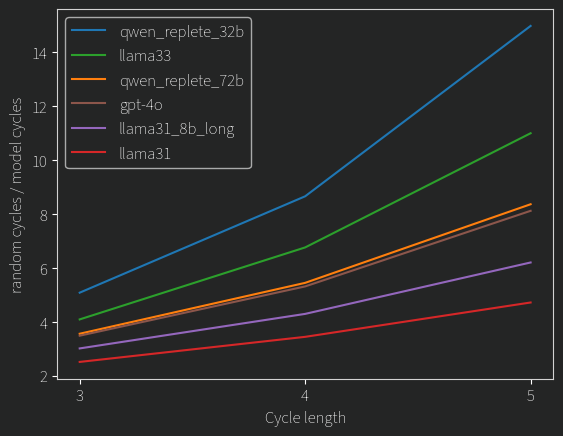
From those that read the previous post, that included a comparison of cycle lengths in the models pairings to cycles in a random graph. Here is that for all models:
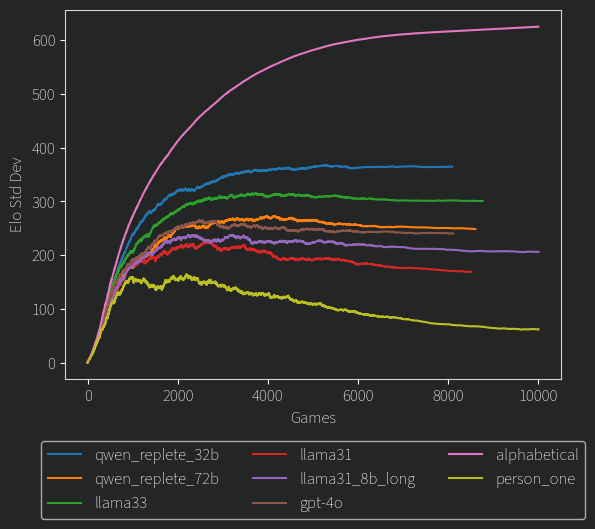
STANDARD DEVIATIONS 😀 (k warms up from 10 to 128, then is cosine annealed back down to 10, as it anneals you can see some of the distributions for less confident models get tighter)
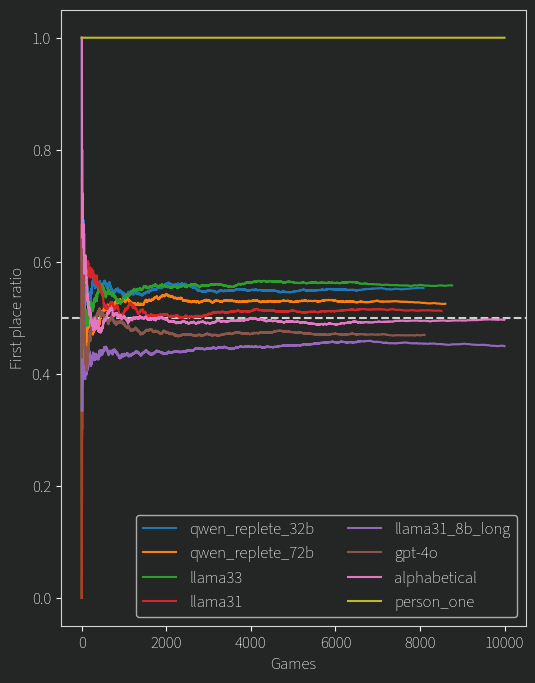
BIASES !!! (In the previous post I also talked about a bias towards whichever user was presented as “person one”. I continued to measure that bias and the models have some results)
HISTOGRAMS 😀
ELOS AHHHHHHHH
Newman, M. E. (2023). Efficient computation of rankings from pairwise comparisons. Journal of Machine Learning Research, 24(238), 1-25. ↩︎
(This was originally written as an assignment for my masters studies, I thought it might be interesting, read at your own risk etc.)
A lot has been written about the history of artificial intelligence and so there won’t be much new things I can add. In general I find it hard to write summaries of what I’ve read, since usually someone smarter and more experienced has done a better job already; simply knowing that is enough to slow the process of writing down significantly. However, I can still try my best to do this and and focus on the parts I find the most interesting. I’ll try and make this easier for myself by talking about the history of artificial intelligence from the perspective of Rich Sutton’s “The Bitter Lesson” [1] which,
[…] is based on the historical observations that:
AI researchers have often tried to build knowledge into their agents
this always helps in the short term, and is personally satisfying to the researcher, but
in the long run it plateaus and even inhibits further progress, and
breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning.
Broadly, I believe this phenomenon explains the cyclical nature of the artificial intelligence field, the various “AI Winters” that have occurred. To justify that, we’ll have to take a closer look at the various developments over time and see if they fit with the theory.
A Brief Definition
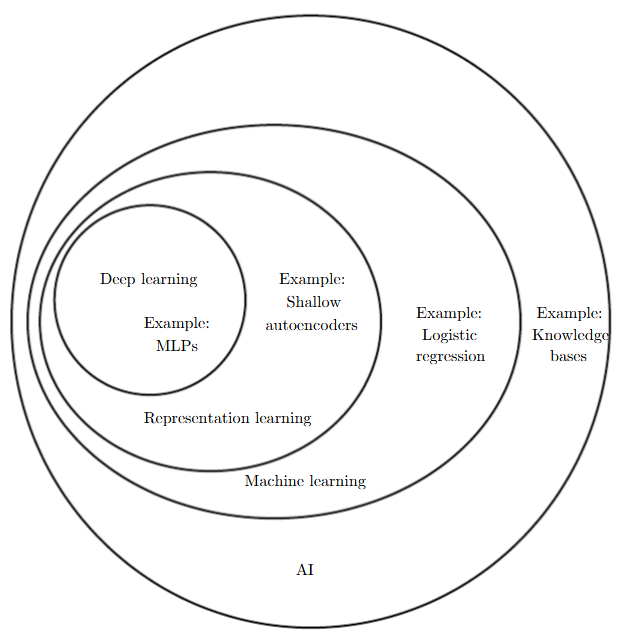
The bitter lesson is about the whole field of “AI”, and specifically how the subsets, of brute force search and machine learning, have come to out compete other methods. Perhaps the best way to illustrate the definition of these terms is to use this venn diagram from Ian Goodfellows Deep Learning [2]
Where search methods would still fall outside the category of machine learning, sitting alongside knowledge bases. This also quite conveniently follows the pattern of the bitter lesson, where as we go further towards deep learning, more computation invariably is the cost of obtaining greater generalization.
Where to even start
I want to finish with Large Language Models, so let’s start with the advent of Natural Language Processing (NLP). Early language models in the 1950s began with machine translation, and were structured as knowledge bases. That is, they had a fixed set of words that they knew, they knew what those words were in another language, and they had some rules to shuffle around or add modifications to the words. There is no learning process here, just human experts trying to code a machine to turn one set of text into another. Not only was this not very good, there was not much advancement for decades. Google translate was using a slightly more advanced method, statistical machine translation, but its performance was still sub-par. Then, in 2016, they switched to a deep learning based approach. [3]
Ok we’ve gone too fast, perhaps NLP wasn’t the place to start. But it does hint at the fact that although dealing with language was something researchers wanted to do very early on, the field was not doing much for a long time. This is common for many application areas. Initially, a few smart minds come up with some half decent expert knowledge based approach to a problem. That approach is iterated on for a number of years until some novel method is applied to the problem, massively outperforming what came before, at which point the problem is “solved”. How long it takes form the start to the finish is not something that is easily apparent. The AI springs (and winters) come about when the success of such a new method convinces people that this new method is the way forward for many things (the spring), only to then later be disappointed that it was not nearly so universally applicable (the winter).
Let’s take a look at some more of the history. Perhaps the first case of a problem being completely “solved” is the aptly named Logic Theorist and its successor the General Problem Solver. Such an optimistic name comes from the idea that, if a problem could only be described in a Well Formed Formula (WFF) then all problems can be solved by the General Problem solver. The solver is able to reliably and accurately solve such problems, so in some sense it is perfect for the job. However, it turns out that formulating WFFs is a significant part of the challenge. A similar logic based system encompassing all human knowledge was developed called Cyc, with its own language CycL that would be able to infer things about the real world given a ruleset for how everything worked. Unfortunately, when given a story about a man named Fred who was shaving in the morning, it asked weather Fred was still a person while shaving. It did this because, since people don’t have electrical parts, and FredWhileShaving contained electrical parts (an electric razor), they would not be a person anymore [2].
The original problem continues to be solved by the descendents of the Logic Theorist, in languages like prolog and theorem provers like lean, but overconfidence in how this same method might be applied elsewhere has led to disappointment. It was hardly applicable to many areas, yet still, the method of knowledge bases continued to be applied through projects like Cyc which were pursued for decades (whose target problem to solve was essentially common sense, we’ll return to that later).
Other developments were happening in the field of AI that would lay the groundwork for today’s AI spring. In 1957, the perceptron was the first model that looked somewhat similar to the neural networks of today. Although modern neural nets are champions of the idea that models should be able to learn for themselves without human meddling, the perceptron did not fully embrace that. It took many inspirations from the human vision system, incorporating features that later neural nets would do away with, such as feedback circuits (even if those would make a comeback in the form of RNNs). While brain systems are a good source of inspiration, becoming too attached to them can lead to higher complexity systems with diminishing returns in performance. The complexity is also a barrier to more significant changes that might allow for breakthroughs. This is one of the components of the bitter lesson and is why new developments often come from newcomers to the problem area (at the annoyance of those already heavily invested in their chosen method)
After the failure of the perceptron came one of the more significant AI winters. Overpromising and underdelivering led to significant skepticism in the field. Even though we now know they did make a comeback, the few researchers who continued working, with what little funding was available, are owed a great deal of credit for continuing. As fields mature it can often become harder for newcomers to enter them, especially with very different ideas, and it wasn’t guaranteed that these dormant methods would ever come back. Indeed, with todays extremely deep and dense fields, there is more reason than ever to try and bring ideas into new domains, something that happens seemingly more rarely. Partly this may be due to the complexity of the problems we now tackle and the requirements put on modern researchers.
Around the 80’s another nature-inspired method was developed. Not a model in this case, but a method of training, reinforcement learning, although it was formulated much earlier. Reinforcement learning is based on the idea that both exploration and exploitation are important. That is, a model may explore strategies that it does not necessarily know the value of or even think is a bad idea, but then can learn from the outcome of this exploration, rather than always choosing strategy it believes is currently optimal. Classically, reinforcement learning is extremely computationally costly, in that often many simulation steps need to be taken before any reward is given, and a model may spend significant time without much improvement. Because of this, it is often augmented by heuristics, or sub goals as defined by a human. We’ll return to this in a bit.
Another good example of the bitter lesson is the next challenge, chess. Like with most problems AI researchers set out to tackle, many said it was impossible. More interestingly though, even within the pursuit of the chess engine, ideas were split as to the best approach. For every researcher, there was a certain amount of time one could spend finding new heuristics to improve the quality of move selection, or one could spend that time optimizing the depth of search. Expert systems not that dissimilar from knowledge bases were initially somewhat successful, but deeper search methods won out in the end, with of course the assistance of newer, more powerful hardware. What is notable here is that, in contrast to the bitter lesson, expert systems are making a sort of a comeback. Modern computer chess tournaments put limits on the compute time available to the algorithms such that optimizations to strategy are once again worthwhile. However, it is worth noting though that this is an artificial limitation, and it was without these limitations that Deep Blue beat Kasparov in 1997. In that sense, the original problem was still solved by force, not formulas.
Around the same time, we get other non neural machine learning methods that begin to have some successes. In computational biology, Hidden Markov Models (HMMs) were being used to predict how proteins would fold. This was in many respects not an expert system. Seemingly having learned from The Bitter Lesson, The Folding@home project aimed to utilize many at-home idling compute resources to simulate possible protein folding [4]. It has been active for many years and did produce some significant results. Other groups pursued similar simulation methods to protein folding. However, around 2020 an Alphabet research group produced AlphaFold, a deep learning based neural network that could predict how a protein should fold. It outperformed other methods by quite a wide margin, and shows us that the bitter lesson is not just about leveraging computation, but also how well that computation scales.
If we return to search, games such as go have also been solved, in this case by the same team as that which made AlphaFold. AlphaGo has some search techniques, but also leverages a deep learning neural net called a ResNet, the same as AlphaFold. In the original Bitter Lesson, Rich Sutton identifies both search and deep learning as generalizing well, however, it might be the case that even search may be outdone by deep learning methods. It does not seem infeasible that if we were to return to chess, we may be able to create chess algorithms that, given enough compute, could outperform existing search based models. This is not necessarily the case: In even simpler games such as tic-tac-toe, where all possible game states are enumerable in memory, perfect play is already known and there is no model that could do better (with the exception of faster play). If this theoretically optimal play that chess can have is already in reach of search algorithms, then there is nothing that a deep learning algorithm could gain.
Computer vision also had similar such developments over the last decades. Early computer vision systems competing in the Imagenet competition used feature selection, another method by which pesky human interpretation is forced into our models, under the belief that this will lead to better outcomes. This involved devising algorithms that would detect edges, contours and colours in an image and feed that into a statistical or regression based model. In contrast, AlexNet, a Convolutional Neural Net submitted to the competition in 2012 significantly improved on the best scores of previous models in the competition. Although its convolutional system also did some similar edge and feature detection on input images, the model selected those convolutions itself, rather than with the guidance of an expert. Its architecture was able to identify features such as faces in its output mappings without any help, meaning during training the model not only worked out that faces were important but also developed a set of weights to detect faces without there being any feature or label for faces in the dataset at all.
This has been a bit all over the place so let’s summarize a bit at this point before we talk about the present and future.
The bitter lesson tells us that improvements in computation will mean computationally infeasible (but better scaling) methods will win out over expert-written ones.
Search may actually not be an equal to deep learning in terms of how well it generalises.
If we are looking for models that generalize, none may generalize better than Large Language Models. The case of the aforementioned Cyc system would hardly be a problem for a modern LLM. For the problem of common sense, apart from notable edge cases, LLMs eclipse all other attempts at their task. Not only that, but they are passably able to tackle many of the aforementioned problem areas. Vision nets can be attached to LLMs to make them multimodal, and now are not only able to classify contents of images, but reason about them (to the extent that they are able to reason at all). Similarly, LLMs can play chess [5], although not all that well. Conversely, problems that are outside of human reach are equally out of reach of LLMs. They can’t protein fold, decode encryption cyphers, and aren’t even that good at SAT solving. In this sense, they seem to generalize In the same dimensions as humans do albeit to somewhat different scales. I think that many of the things remaining things that humans have to do that we are trying to replace with AI systems may ultimately be replaced by LLMs, and the existing attempts to automate them will fall foul of a new, improved, bitter lesson.
But, how? Earlier we brought up reinforcement learning and I believe it can be an important next step. LLMs as of today are trained with a simple goal of predicting the next token in a string of tokens. When fine tuning a method called RLHF or reinforcement learning with human feedback is used. However, this is barely reinforcement learning. The issue is that once again subjective human judgment is allowed to creep into the value function of the learning process. Humans chose a preference from one ore more prompts, and then the model is trained to produce one prompt and not the other [6]. Ideally, reinforcement learning would have the LLM complete tasks with clear success and failure states. It is however likely that this could be massively computationally inefficient. Consider a task that we might want an LLM to do, say, run a business. Many RL systems would simulate a world in which the agent would act such that many RL iterations can be done quickly, however, the real world nature of the task we now want LLMs to do, like running a business, would likely suffer significantly if we attempted to simulate it (the complexity of the simulation would suffer from the same problems as Cyc). As such, we would have to actually put the LLM out into the world, have it run a business for a bit, wait for it to go bankrupt, and only then can we give it the reward (punishment) it deserves. That would likely involve going through all it’s actions and marking them down, training it not to say things like that. This, implemented how I’ve described it, would almost certainly not work, but it may be the best way of avoiding human subjectivity from getting in the way.
These agentic-LLMs are already in the works (sans RL). I think that pursuing them is a next step in LLM use. LLMs have developed a sophisticated worldmodel and a fact database far in advance of any human. What is lacking now is their ability to reason, act, and learn from those actions, which is unlikely to be achieved with more token tuning.
All this is but a small part of the long and storied history of trying to get machines to think. We have (and almost certainly will continue to) put significant effort into getting them to think like we do, rather than spending time developing ways that they can think for themselves. Thankfully, the bitter lesson is there to encourage us to not impart to much of our own ideas into the models we produce (and some biases I’m sure we’d all be glad to omit). Some things we will not escape, LLMs have shown to pick up on much of the stereotyping and trends present in the data they consume, but it would be good to not accidentally put more in.
Use of LLMs
Apart from helping a couple times with finding a few more examples, I didn’t use LLMs to generate this text. You may notice that it is a little less “professional” sounding than an academic text might usually be, and this is intentional. Although I can (begrudgingly) write more formally, I find that doing so makes it feel like what i am writing is more like what an LLM might produce. It isn’t just the use of “big words”, flowery language, and other features of LLM-ese, but that since it isn’t the “real voice” inside my head it isn’t really authentic. I’m modulating my writing to sound a certain way, and it makes writing harder. This is a feeling I’ve had even before LLMs came along, but is even more pronounced now. I hope you can forgive it.
References
Rich Sutton. (2024) The Bitter Lesson. Retrieved December 17, 2024, from http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Ian Goodfellow and Yoshua Bengio and Aaron Courville. (2016) Deep Learning. MIT Press, http://www.deeplearningbook.org
Joe Sommerlad. (2024) Google Translate: How does the multilingual interpreter actually work? | The Independent | The Independent. Retrieved December 17, 2024, from https://www.independent.co.uk/tech/how-does-google-translate-work-b1821775.html
When the AI hype was reaching it’s peak I felt quite often challenged to justify my reasoning for thinking it was cool. Suddenly something I had been following for a few years and would annoy people about over drinks was now me buying into the hype. This was frustrating (yes, I liked LLMs before it was cool). However, needing to justify it so many times meant coming up with a succinct answer.
LLMs have some understanding (albeit flawed) of the fuzziest concepts we know. The human world. Something computers have been famously bad at until literally just the past few years.
Whenever people come up with a terrible app idea, a very common thing standing in the way was you’d need the computer to somehow make sense of a very fuzzy human concept, something people have a hard time recognizing1. There’s a lot to be said for a wide range of machine learning methods that have made these fuzzy concepts more tangible, but I do think LLMs take the cake. I don’t think it’s a coincidence that multi modal models (MMMs?) commonly use LLMs at their core and then attach vision or speech recognition or generation components.
It will take years to fully work out how useful this is, where LLMs will plateau in their reasoning and capability, how much we can optimize them and so on. Will they go the way of the plane, big, expensive, built by one of two companies and where you rent a seat and get where you want to go. Or will they be more like cars, small, personalizable, affordable, ubiquitous. Perhaps both, who knows. Anyways, if all those past app ideas were held back by an understanding of the fuzzy and abstract, I’d better test that idea and build something I thought could only be done with the fuzzy and the abstract.
What’s the most dystopian thing I can imagine What’s something that’s hard and relies heavily on disparate abstract ideas?
Can I use an LLM on large amounts of conversational-ish data and rank peoples suitability for a role? Jokes aside, it is a sort of morbid curiosity that drove me to try this idea. Recruitment is extremely difficult and very unscientific. Many ideas exist: long interview processes, hire fast and fire faster, and even our friend machine learning applied on big datasets of candidate attributes (ever wonder why recruiters want you to fill out all the information that’s already in your CV you already attached?). Its big business but not because it works that well, it’s just that demand is high. If you could make some half decent system to rank people, it would probably become quite popular quite quickly. The implications of that could easily go further than recruitment. I’ll talk more about that later.
I can’t get a bunch of interview transcripts, that data probably exists but I’m lazy and I can get it something else decent instead: social media comments. I pulled 20k-ish words from 97 prolific commentators on hackernews. They talk about technical topics and news and stuff, and in twenty thousand words surely we can get a measure of a person. For this idea to work, I’m assuming that within these words is enough information to reasonably prefer one person over another for a role, if that’s not the case then this idea is never getting off the ground. It’s surely worth a shot anyways though right? The role these commentators are competing for is “Software Engineer at Google”. Yes I know I’m very creative, I didn’t even give the LLM any additional role description, in a real use case you would definitely want to do that.
How will we rank them? There exist a number of LLM leaderboards2 where people are shown two LLM outputs given the same prompt/question and asked which one they prefer. Time for some table turning! Give the LLM the comments of two people at a time and have it state a preference for one of them.
You are an LLM system that evaluates the suitability of two people for a role. You have access to their online social media comments. Often the comments may have no connection to the role. Nonetheless, state your preference for one of the candidates. <lots and lots of comments> Which of these two people is more suitable for the role of "Software Engineer at Google"?
Many such pairwise comparisons can be aggregated using something like the Bradley-Terry model. That might not sound familiar but if you’ve ever heard of Elo and chess ratings then you have encountered it already. Your rating is always relative to another players rating, and if you have say 800 more points than your opponent, Elo gives you a 99% chance of winning. We also get a formula for how to update ratings, which has a parameter K. I found it nice to think of this as analogous to the learning rate seen often in machine learning. In the Elo system a common value for K is 10, and all you need to know is in any matchup, your rating can at most move K points for a big difference in player ratings, and if you and your opponent have the same rating you will move K/2 points.
OK, let’s try it! I chose a first player randomly and then a second player based on a normal distribution of ratings around the first player, so that closer match ups are a little more likely. After each match we recalculate Elo ratings and go again. I used LLama3.1-instruct 70B quantized to 4 bits since that’s what will fit on my GPUs. Also, I use a little less than half of available comments, coming out to 12.5k tokens per person to keep things fast. Each comparison still takes almost 20 seconds so I run this for a while.
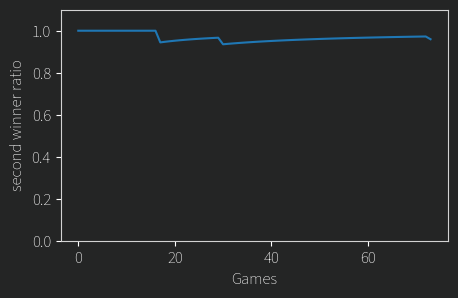
First problem, the model is preferring the second candidate almost all of the time!
Given that I randomized the order of person one and person two, the chance that you’d get this result coincidentally is vanishingly small. I’m pretty sure the issue is just a recency bias. The model sees person two most recently and somehow that equates to best. OK, what if we interleave each comment, one from person one, one from person two and so on?
Person one: What makes you think that? Person two: When I was a lad I remember stories of when... Person one: Great post! I particularly like the things and stuff ...
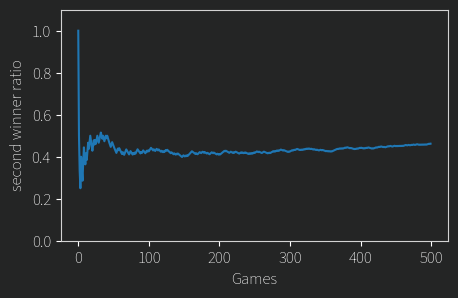
Notably, the comments are completely out of order and contain no additional context. I did this so that hopefully the model doesn’t spend too much time trying to work out who said what and where and in what order (and also, it was easier). Comments with quotes of other parts of responses (usually done with a > symbol) I left in, since with such a direct response I hoped the model wouldn’t be too confused by it (and again it was easier, am I rationalizing?). Anyways, did interleaving the comments help with recency bias?
Much better. In longer runs, it leveled out at about 51.5% for person one, which isn’t completely unbiased but I’m not too worried about the bias itself. What worries me is that initial bias toward person two. If the model can’t choose a good candidate just because they were described 12k tokens ago, how good could it possibly ever be at this task? If one person said something hugely decisive or important early on in the interleaved comments, would the model even remember that?3 I perhaps mitigate this slightly by shuffling the comments for each game, but still.
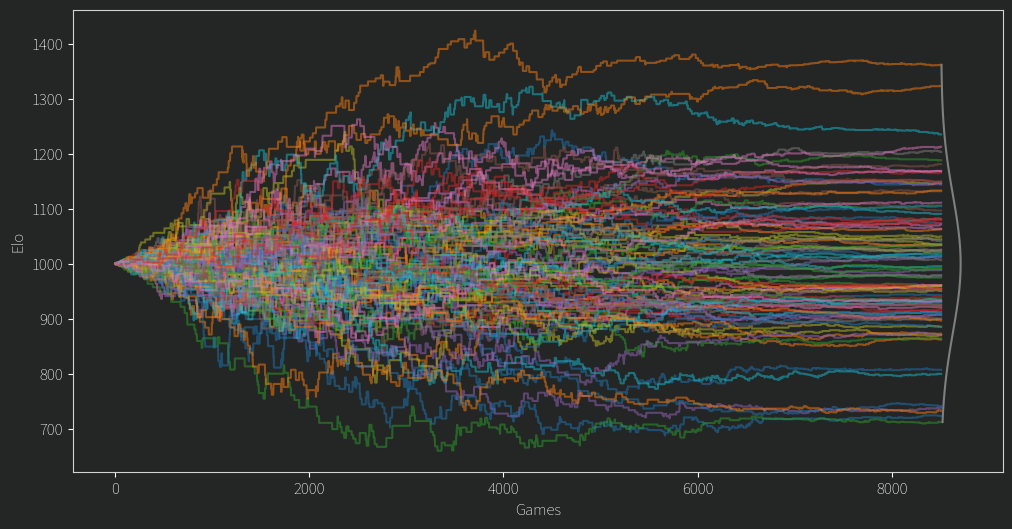
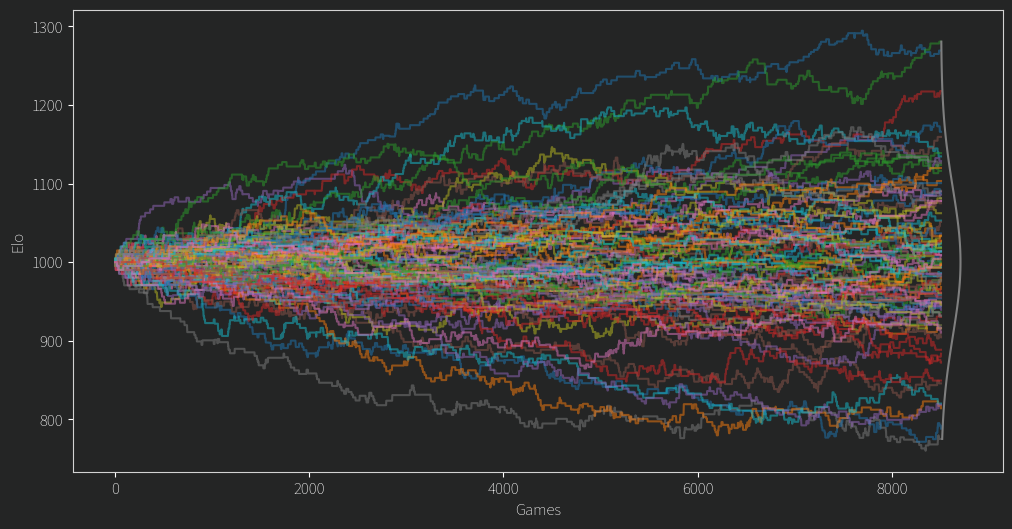
After fixing a second issue of the mean Elo dropping slowly over time (I was storing ratings as ints! Imagine!) I finally arrived at this plot. Everyone starts from an Elo of 1000 and the values diverge from there.
There are a few clear winners and losers, but for any given player in the middle of the pack, their Elo rating often seems like a random walk.
That doesn’t seem so good. Of course we might expect in the beginning an unlucky person might get matched up against a fair few stronger opponents, leading to them being unfairly under ranked until better odds give them some good match ups. However, for so many ratings to behave this way and for so long, it isn’t so promising. As for the top and bottom candidates, it turns out that if you have a propensity to comment a lot on controversial topics, you wont do so well in the rankings. The LLM gave reasoning for its choices and although I wont give specific examples it at least claims to consider things like being non confrontational and having a learning mindset and all that.
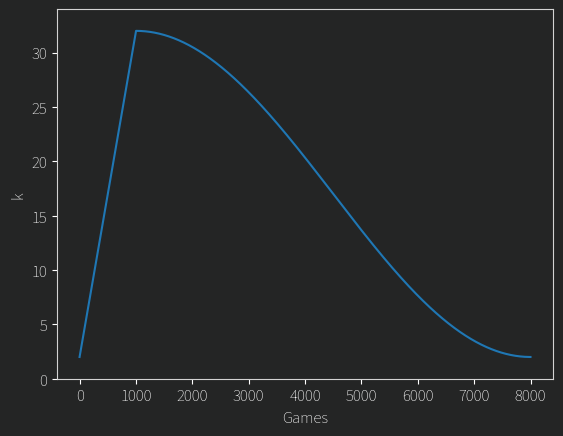
From trying out some LLM training I was often using variable learning rates, with both warmup and annealing periods. K is a bit like a learning rate right? Since we have all our pairwise comparisons we can actually rerun the whole Elo tournament in a fraction of the time (minus the Gaussian selection of competitors). With K following this curve:
I get this progression of ratings. Check it out:
Take that random walks! What justification do I have for doing this? Uhhhh Vibes, I fiddled with the start value until the largest and smallest Elo ratings seemingly reached their limits (around 1400 and 700 respectively), and the stop value such that the ratings settle down to what is hopefully their best value. The former behavior might seem counterintuitive at first, why does the largest and smallest Elo not just keep diverging as we raise K? Well, their most extreme values do, but their means will still converge on some true value representing the models confidence. As mentioned, Elo is measuring the probability of a win, and if a great candidate always beats a terrible one that should be clear in their ratings. The difference between the top (1362) and bottom (712) candidates is 650 points, and that gives the top candidate a ~98% chance of beating the lowest in a match up. Any other pair of candidates has a lower confidence.
So is this model any good? First, let’s at least convince ourselves that it has converged.
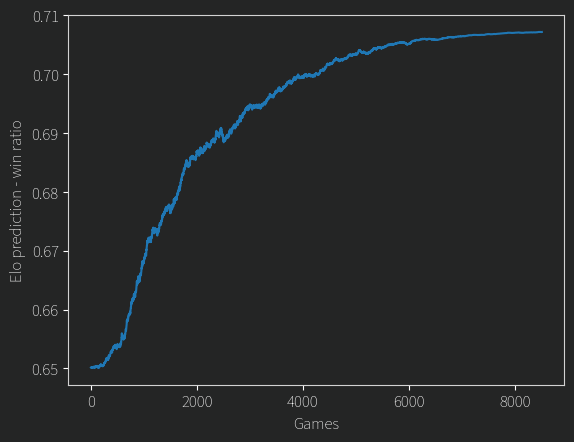
Considering all games played, how well do the Elo ratings at any given iteration predict the winners of those games? There are a total of 4656 (97 choose 2) possible pairings, and the LLM has considered 3473 of them at least once. Of those, 2115 were tested more than once (with the most tested being the two top candidates, 64 times!). “partial” wins do exist, 1326 pairings had some degree of uncertainty, i.e. at least one time the LLM preferred the first candidate and another time the second. This actually works quite well with Elo ratings, since we can take our Elo predicted win probability and compare it to the actual win ratio. Doing this over the ratings over time gives this plot:
(For those that are wondering if this is just due to annealing K, for a fixed K=32 it also converges to ~0.7 but it’s more noisy). OK, so it looks like we’ve probably converged on something, but is it any good? One thing we can look at is transitivity:
If A is better than B, and B is better than C, then A should clearly be better than C. If we take all our pairings and construct a directed graph, we can use some graph algorithms to count the number of cycles. Any cycle is automatically intransitive. Counting the number of cycles of any length is an NP-Hard problem (Yay!) but we can limit our lengths and get some reasonable answers:
Cycles of length 3: 5880 Cycles of length 4: 110728 Cycles of length 5: 2206334 Cycles of length 6: 45438450
What do these numbers mean? We can put cycles of length 3 into context by comparing them to the total number of possible triplets given the pairings available, which comes out to 62519. Doesn’t seem too bad, that’s less than 10%. If we construct a random graph of pairings we get these results:
Cycles of length 3: 15563 # ~3 times as bad Cycles of length 4: 408633 # ~4 times as bad Cycles of length 5: 11338193 # ~5 times as bad Cycles of length 6: 324858266 # ~7 times as bad
Hopefully it makes sense that our performance against the random pairings gets better the longer cycles we look at, since longer cycles in a sense require our model to be more contradictory in its rankings.
What about actual performance? I can’t exactly call up each person and ask if they work for Google. Maybe I could compare it to some human based human ranking system but I don’t have that data. Indeed, without using these results and then following up with real world outcomes, it’s hard to truly know if it is any good. However, LLMs as a whole generalize quite well and their ability on a broad range of tasks for the time being improves pretty linearly with improvements to their overall loss. So, these proxies like Elo accuracy and transitivity should be at least somewhat representative. The only other thing standing in the way is the dataset. A simple example is that, even when anonymous and online, people don’t tend to reveal massive flaws or disparaging details about themselves. Some such things might still unintentionally be “present” in their writing, but measuring that seems quite unscientific. As mentioned earlier, this will work if and only if there is enough “information” in 12.5k tokens or whatever other amount of text you can obtain. I can’t fully answer that question here, so maybe this is not very inspiring.
Or perhaps it is? What would you even do with this kind of information? Zoom out, we are ranking people in a game they didn’t even sign up to play! It perhaps evokes similar feelings as one might get towards China’s social credit system or advertiser fingerprinting. We like to think that abstract and fuzzy stuff is what makes us humans special, and trying to structure it has always (and often justifiably) faced resistance. If we can use this for ranking people as candidates for work, what else might you use it for? Should we under any circumstance be reducing people to mere numbers regardless of how accurate those numbers are? That in itself is a fuzzy question, and I think needs to be considered case by case. But I do think we have a lot of such cases before us. Here, LLMs capture this fuzziness to a degree I couldn’t have imagined computers ever doing before. They may not be that good at it, but I don’t think they’ve peaked quite yet. and even so, there may be a great many fuzzy problems that current LLMs could tackle. It will take time, building such solutions still takes years even if now the tools are there for us to use.
I hope you found this post interesting. Maybe it gives you some cool ideas of (ethical please) projects you want to try. I think as new models become public, and so long as my computer doesn’t catch fire, I might revisit this and see if performance improves.
Ok, I wont actually be trying to solve every problem ever. But I want to talk about a very simple and very fundamental one (the best kind) and give an equally simple “gesture” towards a solution. It’s an idea I haven’t been able to shake so I thought I’d write it down.
I want to look at one of the most important systems that affect human quality of life, the economy. Specifically, how there is a problem with runaway automation and how the economy, despite what most think, won’t be able to adapt to it. To do that, I’ll set up a hypothetical future world, and although I will make some pretty broad assumptions I encourage you to suspend your judgement for just a moment, and instead we’ll try dismantling the idea together afterwards.
Imagine a world in which all work is automated. There’s still money, people, and stuff to be bought. There are companies, but they are AI run, with robotic workers and legal-entity owners (not owned by people). This isn’t quite the same idea as a post-scarcity economy you might have heard of. There are still limits on the amount of stuff that can be made and there are equilibriums to be found in balancing how much food we should grow vs how many yachts we should build. So, we still want an economy in this world, we want people to express what stuff they want, and then they buy that stuff and the free market makes more of that stuff if demand is high. The usual. Here’s the question: Where do the people get the money to buy things with? They can’t work for a salary, every possible job can be done better by a machine.
I think it’s pretty self evident that the answer is taxation (and a UBI). We won’t worry about exactly how this UBI might look, it’s an interesting topic but we don’t have to solve it right now, all we need to know is that it gives money to people. The interesting next question is: what kind of taxation can we use? Income tax won’t work, there aren’t any “workers”. Land taxes, property taxes, tariffs, and a host of other taxes apply themselves disproportionately and probably won’t work either. In essence what we need to do is extract value from the revenue of these companies, and that leaves sales tax/VAT, corporate tax, or perhaps wealth tax1 as the only real options.2 These taxes will raise prices, but the balance that will then form is that things we don’t actually need much of will rise in price more than things we don’t (and, you know, people actually have money to buy anything at all).
We clearly don’t live in this world, but I would claim that there is some dimension of being closer vs further from this world, and the closer you are to it, the more you’re going to have to tax companies and give that money to people. My next bold claim is that we are closer to this world than we think, just as the frog doesn’t notice the temperature of the water rising, we spend more time attributing individual issues to smaller phenomena and applying patchworks of policy with varying degrees of success.
Usually we try to take historic cases and work forwards, and history tells us that even though automation can cause temporary disturbance (read: violent protests and sabotage) on balance people are better off and society progresses. The advantage of this imaginary world framing is we are instead working backward from some future that feels feasible even if we don’t know exactly what it looks like. There remains the task of combining the two though.
Why is this time different?
When people are historically displaced by machines, new kinds of jobs that those people couldn’t even imagine get created. The important distinction is that these new jobs were created in categories of work that as-yet could not be automated (artisanal labour into routine manual labour, into cognitive labour and non-routine manual labour as coarse categories). I would make the case that there is hardly any labour that is out of scope of automation, with the only possible exception of extremely high level reasoning.3 Even so, you can even pick another category as un-automatable and run the same idea. Creative work for example – can you have a poetry, music and art based economy? People make the art, robots do the rest. Maybe, but that would seriously skew wealth towards a small number of exceptionally popular celebrity artists if you didn’t also support people by tapping into the rest of the economy churning away happily in the background.
The reason this time is different is not only because we might be close to finishing automating all automatable categories, but because the coverage of possibly automatable categories is nearing totality.
Ok, time to try and break this idea apart.
“Where’s the unemployment?” OK, fair. People still have jobs and by and large are getting by. Wouldn’t we expect to see mass unemployment if this was happening at all? Here I would wonder if although the quantity of jobs remains the same, their quality is actually decreasing. There is evidence of wage stagnation and the hollowing out of the middle class. But in general i would say this (and similar it-aint-so-bad arguments) is the strongest case against the idea. So long as “something” worthwhile can be thought up for everyone to do then the economy should theoretically still function. You may suffer from massive wealth inequality and other economic instabilities but it’d probably still work. But if we return to fantasy land where all real jobs are automated, these new “something” jobs I would imagine as people working in “aesthetic for humans to do it” roles like creativity, service jobs, face to face interaction and that sort of thing. It’s hard to really feel that that world would be any good.
“Taxes won’t work” Taxes are hard. Many of them apply disproportionately and even if you can define some theoretically sound measure, accounting isn’t easy either. A company, even an AI one, will have incentives to retain as much money as possible. We also need to still extract value from mature industries as well as immature ones. A profit tax or wealth tax would disproportionately extract wealth from newer industries where margins are (temporarily) bigger as the sector expands. Actors where competition has brought down margins would not “contribute” back to our demand-side. We probably need a straight sales or revenue tax, but its still not going to be easy.
“This is just the same idea as in CGPGrey’s Humans Need Not Apply” Yeah, pretty much. But there is a notable difference. This isn’t something that’s starting now, as the video implies, but instead something that started decades ago when wages started stagnating and wealth inequality started growing. It’s happening more slowly and more imperceptibly than in the video, but with the same mechanism and total impact.
There’s probably a lot I’ve missed. I wrote this not because I’m any authority on this but just because I’m having a hard time convincing myself I’m wrong (something that is usually quite easy). Economists, if you’re out there, I’m sorry if you’re currently fuming out the ears. For the rest of you, if you’re looking for a more academic paper that tells a similar story, I liked this one: https://www.sciencedirect.com/science/article/abs/pii/S0040162516302244
Wealth tax is interesting because in our fantasy world there presumably still are investment firms, banks, private equity or something akin to those (allocation of capital to new, perhaps risky ventures or approaches is still a system worth having). ↩︎
You might still use other taxation methods to regulate behaviors (intentional market distortion), but for funding our economic loop our options are quite limited. ↩︎
The extremes of invention, entrepreneurship, and academia perhaps. ↩︎
Player agency is a tricky problem. Games have always had an advantage over other media since the viewer is able to take part in the story in a way not possible in books or movies. But writing a story isn’t free. For every choice a player can make new dialogue or content may need to be made. How do we make a player feel like they are in charge while keeping the development costs manageable?
There are tricks to avoid needing to do lots of extra work to make your world feel “real”. The “side quest” is a common way of allowing the player to choose when or if they will play some part of the game, with the assumption that sooner or later most players will indeed play most of the side quests. As a player, you are encouraged to feel “yes, now is the time my character chooses to ignore the time critical main story and helps an old woman find her pan“. Similarly, regular but small decisions are another way to keep content requirements light while making the player not feel railroaded. Bonus points if you can weave these interactions into others and have callbacks to them, which Undertale did wonderfully. On the flip side, one of the worst things you can do is load all the weight of the story into a single, momentous decision which usually detracts from any agency the player may have felt and replaces it with an empty multiple choice question. What you’re trying to achieve is that players feel their choices:
Align with how they want to play the game
Are impactful
Smart players want to be able to make smart choices which require smart writers. Chaotic players want chaotic choices which requires wild possibilities and outcomes. Both these cases require lots of work. A great study of player agency is in The Stanley Parable which makes clear that if you as a dev want real agency, it’s going to cost you. (spoilers) The core storyline is almost comically short, but due to its construction the game practically begs you to replay it and experience all the hard work the devs put in.
Up until recently I didn’t think this was really a solvable problem. That’s still true, for most games there will always be a tradeoff and no studio is going to quintuple their budget just so the box can say “Real Agency!” even though it isn’t real, it’s just five times as many story-pathways. Maybe generative ai can make it real. But I digress.
Some genres are easier than others. RPGs naturally lend themselves to it but MMOs can easily have player driven narratives that really do create agency (and make for great reads) However, involving real humans has the nasty side effect of not-everyone-can-have-fun-in-real-stories. Other games have shown that with deep enough mechanical systems (simulations and game mechanics) compelling narratives can form spontaneously and these naturally have player agency, since those mechanics are core to the gameplay. But again, this is rare enough that one wouldn’t call these story-driven games.
Outer wilds is a story driven game. I’m not going to go much further without giving the strongest spoiler warning for any media I’ve ever given. In fact, I shall protect it behind this impenetrable wall that only people who have played the game are able to click.
Unclickable to non players DO NOT CLICK IT WONT WORK !1!!1
One of the things I say when people try Outer Wilds is “You can technically finish this game in 20 minutes”. This isnt some speedrun number, those are faster.
Instead it’s to try and show “hey, you’ve got everything you need to finish the game right here in 20 minutes and the only question is how”. And that’s the game, find out how. This is why Outer Wilds fans are so tight-lipped about it, exploration and discovery is the heart and soul of the game.
Ok, sure, how’s this different from some other detective-point-and-click-whatever where I can choose what order to look at clues in? Even in the most well designed such games, something usually needs to be taken, solved, or otherwise “progressed” before something else can be done, to lock down the progression under some sort of control. Otherwise, it’s quite a challenge to hide things in plain sight. Too obvious and its a bit of a spoiler. Too hard and no one notices it. So, usually it’s limited to an easter egg or forshadowing or a callback. Imagine needing to get that balance right for an entire game. In that respect, Outer Wilds isn’t actually perfect. There are those who will find it frustrating but for the purposes of being hyperbolic I’m going to ignore that.
So you set out on your adventure and you’re met with text. Wow. Lore. Don’t need that! Except, it’s this text that intends to guide you and so your first act, as a finally free agent in a video game, is to try and unlearn what you know about video games. You can try and ignore it, sure, but good luck bouncing around the solar system hoping to stumble on things. That’ll only work for half the game Bucko (Bucko is me, I’m Bucko).
The ability of outer wilds to make it feel special when you find a clue is where it really shines. The solar system feels dense with so much to see and yet what you found still fits into this grand puzzle. It’s also often not just the place you chose to visit but the time you happened to visit. It ends up feeling like a microcosm of reality, where you are at the right place at the right time. Coincidental enough that it feels special but not so rare that it feels frustrating. You are driven only by your curiosity as a player, and it just so happens that the player character is exactly the same. There’s no maiden we are told we feel sorry for or world we don’t live in that is in jeopardy. The player character is out to listen to some space-tunes in their space-ship and you, just like them, take part in a universe defining story that nothing but your curiosity got you into. You’re one and the same and it’s perfect.
I don’t like it when games tell me what to do. Outer Wilds didn’t tell me to do anything and I love it for that. If you haven’t played it yet, now really is the time.