Hi. I’ve thought about this idea for a while, and I think it’s come together almost to completion so, here it is. It’s somewhat related to Georgist theory but a bit different, you’ll see. It’s mostly based on the work of Acemoglu and Restrepo and Korinek and Stiglitz, but also many others.
To start, scarce resources. Scarce resources are the inputs to the economy, maybe your first thought is rare earth metals but we can consider three kinds of scarcity:
- Physical scarcity: ore, land, air, water, oil.
- Institutional scarcity: Scarcity set by laws, could also be called artificial scarcity. Patents, copyright. Monopolies can also introduce a kind of scarcity, and if we have a legal monopoly it’s Institutional scarcity.
- Dynamic scarcity: Scarce only insofar as it takes time, something like a nuclear plant taking 15 years to build is dynamically scarce. Capital itself is dynamically scarce.
I believe it’s valuable to be able to focus on physically scarce things, because the other two either we can change, or we can wait for. One interesting question, what are we? Our labor is economically a good, so what kind of scarce is it? Arguably it’s dynamic, people are born and die, but that’s somewhat macabre, so let us put them into the group of physical scarcity. That’s to say, for this paper, we claim that we should not wait for people to be born or die for the economy to come into equilibrium. You might disagree with that, but I’d ask you to accept it for now. With that, our scarce resources can be talked about as:
- Land
- Labor
Land because it contains most (but admittedly not all) our scarce resources. Iron ore is in the land, or it’s in the buildings on the land, or it’s in the scrapheap on the land. Crops grow on land. Oil is under the land. The exceptions are, well, air and water, and they matter, but I’ll return to them later.
Labor is scarce because there are only so many people on earth, and there are things we can do for eachother that land can’t (at least, not yet).
The economy uses money, but money doesn’t actually have any value intrinsically. We just use it as a medium of exchange. In theory though it represents value. One such representation is the wage. You are paid based on how much you contribute to the economy, paid more if you contribute more. How are wages set in aggregate? I would argue they are set by the subsistence level, the level needed to survive. That is an old argument and “wrong” for a few reasons, but it actually will serve us quite well for now. It’s wrong because if you look around many people are paid more than subsistence wages. In part, that is due to human heterogeneity (we are all different) and the fact that the economy is always changing, and that change can temporarily move prices. There is one more natural system though that raises the true minimum wage above subsistence, but I need to lay some groundwork first. However, our collective minimum wage is actually subsistence, i.e what we need to survive. Why? Because if it were less than that, we would die and then we can’t work, and if it were more than that, the economy would optimize it down to that. One last component worth considering is all our tax and redistribution systems we have, which lift people at the bottom up by pulling down those at the top.1
The thing is, this rule of subsistance-survival applies to the land, sortof. The most poetic example is climate change. Our earth (now including water and air alongside land) can also die if not treated properly by the economy. It currently does not really demand a wage beyond some token things our governments do (like a carbon tax), so it isn’t represented very well in the economy. Here is a diagram where I will include it for now but omit any connections for it (they are almost not there in the status quo, not in the way I want to talk about):

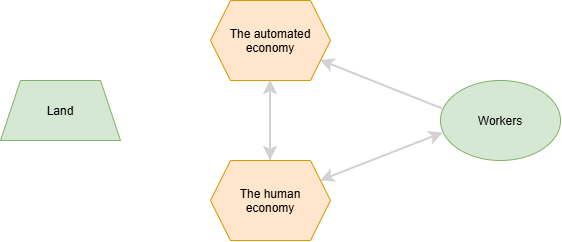
Each arrow is a flow of money, but more precisely, a flow of value. I get a wage for working, I buy a good from a company, an “automated company” purchases services from a human one, or vice-versa. Notice all are bidirectional except for one, because a worker is not paid for the work done by a machine. The two economies are conceptual, that “automated company” doesn’t actually exist (yet). Every company on earth is realistically a bit of both. One CEO and a billion dollars of machines, is mostly automated, but the CEO performs some labor by setting the correct direction for the company. A thousand farmhands using sickles is mostly labor, but the sickles are a form of automation. Before, I said humans are heterogeneous and redistribution plays a role, so here is that diagram:


What is extra notable here is the only arrows going out of the automated economy are the ones flowing to owners and to the human economy, I’ll return to that later. Once again, the human blobs here are conceptual and it is arguably impossible to be only in one of these blobs as an individual. If you work and own stock, you are somewhat owner and somewhat worker. Even if you own only the clothes on your back, you are an owner of the material in those clothes. That might seem strange but that material is scarce, and owning anything scarce makes you an owner. Clothes make you more productive at work (I assume), so when you wear them to work, they are representing the automated economy, and you extract their value through the fact that you own your clothes. I have colored owners and non workers as blue because they are not scarce resources like land and workers. Already from that, you may be able to see a faint glimmer of what this whole theory is about.
Government sits to the side, and it can collect from owners and workers, and distribute also however it wants. In a democracy, however we want. The arrows here, which way they point and their size, is dependent on policy. Our conceptual middle income worker is one who gets back what they contribute (definitionally, just so there are fewer arrows on this graph). In most countries, we tax high income workers and distribute to low income ones. What might surprise you is that the line from owners is (usually, in most countries) small, and the line to non workers is also very small. The short version of why is that most of our taxes have incidence on wages, and most our benefits are conditioned on past or future work, linking them to wages. Income taxes and pensions are the obvious examples. However I would include other less obvious ones. On the tax side, non exhaustively:
- Income tax, obviously
- Consumption taxes like VAT and sales tax – This is because most consumption is paid for by wages, or by benefits that are funded by taxes on wages. Not all VAT though, consumption from owner incomes (I own stock, collect dividends or use it as collateral on a loan, buy a thing) is not wage linked.
- Property/council tax – It taxes the labor that went into building the building or improvement. Like VAT though, it’s not a pure labor tax.
- Profit taxes, and even wealth taxes – Also not a pure labor tax, See below
Even a profit or wealth tax taxes a smart investor or decisionmaker, their cognitive work is labor, and therefore when we tax it we collect from labor. However, e.g wealth taxes also tax wealth gained from say, owning a global index fund. No thought is needed to do that, so that sub case is a pure tax on ownership, but since it’s entangled with a tax on the intelligent allocation of capital, wealth taxes aren’t pure. On the benefit side we can consider these as wage linked:
- Pensions – You have to have worked in most cases, and it grows if you worked more
- Unemployment benefits – You used to work, so it’s still wage linked
- Any benefit that dissappears if you start working, or get a higher wage, are also wage linked. Even free/supported education is wage linked because you are meant to start working at a certain age, and can only get free education for so many years in most countries. Free healthcare is wage linked if it’s payroll funded.
I am currently working on a separate project to put numbers on these flows as best I can across different countries and time, where essentially the question is “how much of consumption spending comes from wages, directly or through redistribution, and how much comes from taxes on pure ownership”. It’s hard due to the aforementioned entanglement, but the napkin math for the United States right now is around 8 to 1, or 89 vs 11 percent. Meaning, those big arrows are 8 times larger than the small ones. That number might feel surprising still. If it does, I would encourage going back and reading the definitions, and how most taxes and benefits are actually wage linked, and the big ones in most countries (income tax and VAT) tend to be also the more wage linked ones.
Let’s return to the two arrows coming out of the automated economy. One is to owners. Here, if you own something scarce and take value from it, that’s one of those arrows. Notably, I don’t pay myself for owning my clothes, so the arrow is representing value but not money per-se. The same is true of the arrow flowing to the human economy. In a company, very rarely are we modelling the flow from the sickle to the farmer with money, although from the billion machines to the CEO, we can definitely argue that that is a monetary flow. Their wage is inflated in excess of their labor because, through their position as ceo, they have influence enough to act as an owner (In economic terms, this is rent seeking behaviour). A similar fact is true for shareholders, they provide labor by picking good stocks, but if they hold them without considering the value whilst still voting for a dividend, thoughtlessly, then they also act as rent extracting owners. In a fully competitive model economy, this can only happen if you have true control over a scarce resource. A shareholder can’t thoughtlessly extract a dividend if another company could notice that, lower prices, and compete with them. So, thoughtless extraction can only happen when competition is in some way limited, through laws directly or through property rights over scarce resource that are rented out rather than sold. At this point, you might think I am taking aim at property rights, or rules like patents and copyright.2 I’m not, they also protect us from eachother. Stealing is a form of rent seeking behaviour too. So is war. Someone produces something with effort, and takes ownership of that thing or another thing (you sew your own clothes, or you work to buy clothes). That ownership is very rarely truly forever. Patents and copyrights expire, machines rust, even your clothes get run down and at the end you throw them away. When that last step happens you relinquish your ownership even though technically, in some sense, that fabric or metal still has some value. The point is, it has its scarce value. It started with it in the ground, and it ended with it in the landfill, it never lost it or gained it. That scarce value is entirely fixed, and it’s a function of what we humans can do with it, and how much joy and utility we theoretically can gain from it. Theft, fraud, war, all these break the natural cycle of the economy in a way that is rent seeking.
Loops
That’s a lot of text so soon it is time for more diagrams. I will collapse workers back to just one blob and remove income redistribution arrows, because they are not the topic of this piece.3 What I will add is a kind of tax and a kind of benefit. Conceptually, I want to add non labor linked tax and a non labor linked benefit. Practically, I’ll use the terms LVT and UBI going forward. Finally, and this is most important of all, I will merge owners and non workers. They are identical in every respect except how government policy treats them. By our definitions, an owner performs no work, not even a lazy afternoon stockpick. They are one and the same. (and also it means I can move the government box to the top, since with merged worker levels and merging owners and non workers, it would have no arrows (isn’t that interesting? no arrows? I’m being coy because I’m getting excited, you can too if you want)).


To illustrate what’s going on here, let’s talk about three loops
- The labor loop
- The owner loop
- The land loop
The labor loop is the one we are familiar with. The smallest incarnation is me doing something for a friend, and a friend repaying the favor later. The biggest, conceptually, is our entire human economy to every worker (the lowest arrow in the diagram, a bidirectional loop). We also include the cycle between worker -> automated economy -> human economy -> worker as part of this loop. That’s because if I purchase something, maybe through a webstore rather than a cashier, in some sense the first step is an automated one, and then it might go to a human, and then it might eventually get back to me.
The owner loop is the bidirectional arrow between the automated economy and our non worker-owners. I own my clothes and in my free time I enjoy wearing them all on my own, it’s a fully closed loop. I thoughtlessly own stocks, I use it to buy from companies (both economies, so it includes owner -> human economy -> automated economy -> owner), and at the end of the day the value flows back to me.
The land loop is the one we have constructed with LVT and UBI. Notably, implementing this LVT has created a flow from the two economies. In that sense, it’s not like a tax we might recognise. Most taxes tax existing flows, a 50 percent tax taxes half of something nonzero, half of a wage, half a dividend, half an inheritence. Land doesn’t earn much rent, at least not if you average out across all land (an individual plot may earn a lot). In fact, the rent it does earn is set very similarly to how aggregate wages are set. The difference is, land has a subsistence wage of 0 (usually). The worst, crappiest land can demand a rent of 0 on its own. If it’s land that I can see some value in that’s better than other land (it is beautiful, temperate, has iron ore deposits that other land doesn’t) then it can command a nonzero rent. Heterogeneity once again makes the mean rent of land be above subsistence. Anyways, for our LVT, we apply an absolute floored tax. A number of dollars per acre minimum, then scaled up by the value of the land. You don’t actually need the floor, at least not in theory. You can put the base level at zero and use an honest to goodness tax. In practice we add the floor to make it partially a pigouvian tax. Even the lowest value land doesn’t have 0 value. 0 value land is land we dump on and take for granted. It’s land we pretend we never will need, even if maybe one day we will. It’s pigouvian because it’s in excess of what the market believes the price to be. The income from the floor should not go to the UBI, it should go to things that mitigate the harms, the negative externalities, of improper use. The floor tax discourages abusing land, the income from the floor deals with damages incurred. Notably, taxing air and water is hard to do for a country. Land is very closely linked to all economic activity, so putting a floor there is a very good way to collect and then spend to not just preserve land, but air and water as well (for example, carbon capture, if we should want it). That’s slightly distortionary, so if at some point we realize we are all living on water cities for some reason, give me a call.
Technology
What does technology do? It allows us to take the things that land provides and do things with it. A lump of iron does me not much good. Iron used to make a building gives me shelter, and technology is what makes that possible. It also makes it easier, cheaper. In theory I can pile lumps of iron by hand into like, an igloo thing I guess, and live in that. Technology can give me a much nicer house, and it can do it without me doing as much hard work. But, it has taken igloo building from me. This is fine by me, I will forsake the joys of igloo building for a nicer house. However, in a simple economy, that house would never be built for me. Even if I have all the technological knowledge in my head or in a book close at hand, it is only built if someone else, another human, does some other labor for me (at least, for now). Then I do some labor in return, and that is the economy. Crucially, it works because of the link between the automated and human economies. If the iron can’t be turned into a nice house without a human, then I can sell that human my labor to get them to do it for me. If the iron to house building is fully automated, I can’t ask the machine to build me a house because the machine wants nothing from me. It only works if I own the machine, and I tell it to build the house for me.
That’s all very abstract but what does it mean? It means that technology only helps us if it needs humans (or if we own it). It’s capability overlap with us is not uniform. It can lift a ton of iron, but it needs a human to know where to put it in the smelter. In our loops, the owner loop and the labour loop, differences in capability to produce an output good is what links the automated and human economies together. Now let’s look at history, in four arcs:
- Prior to the industrial revolution, subsistence was commonplace. We lived, but not much else. Technology had not gotten very far, labor had to do most of the work. If technology improved, temporarily things may get better, but they get optimized back towards subsistence for most.
- The industrial revolution created a massive capability non uniformity. Physical labor was mostly automated, cognitive labor almost entirely not. Any good or service that requires both links our two economies tightly. Humanity flourishes.
- We develop computers, and the simplest cognitive tasks are automated. The link weakens.
- We develop AI, and technologies capability is becoming uniform again. The link weakens further. If we do nothing, we will return to subsistence, even though we don’t have to.4
That link, and the strength of it, is what lifts the true minimum wage above subsistence, which I foreshadowed earlier. It’s “natural” in the sense that you don’t need to use policy for it to exist and work, but it isn’t fixed nor monotonic, it can go up, and it can go down, and whether it does is a function of how much human labor can be multiplied by technology whilst not replacing the human labor. It’s augmentation versus displacement. Technological progress which is high in augmentation and low displacement is a historical oddity, it’s not a guarantee, and indeed it may well be encouraged to invert. Technology is rarely forgotten, and if we make the claim that it has some diminishing returns, meaning the next iron efficiency gain is harder to find than the last, the economy will go looking elsewhere for efficiency gains, and replacing people becomes a relatively more lucrative one. We’ve had more displacement than augmentation for the last 50 ish years, by my interpretation of the findings of Acemoglu and Restrepo.5
Protecting the planet
Our LVT without a floor allows us to claim the value of land, and the UBI allows us to spend it on things we want. If we only had these two, we might kickstart a new fantastical age of consumerism. One way to limit that is with the floor on the LVT, the pigouvian component. Setting it high and not spending it on UBI is essentially saying “if we consume too much, we will kill our planet”. Admittedly, spending it on anything wage linked has a component of increasing consumption, but conceptually it works. We set the ratio of floor to slope in the LVT to balance these two. Literally ax + b, higher b is a higher pigouvian component, higher a means more extraction from land that can be spent on consumption.
A third component
There’s another neat thing worth adding to this system, if you want redistribution amongst people. I leave it at the end here because I really, really don’t want anyone to relate this too much to the Great Debate that already rages every day, but it’s worth mentioning. We can fund some of the UBI with a VAT instead of LVT. All this does is flatten the consumption curve. A high income earner that buys lots of stuff is taxed more than someone who buys little. But if the VAT is flat, and the UBI is flat, then that acts to redistribute buying power from those that buy many things towards those that buy few. It is nicer than using income taxes or profit taxes or wealth taxes because the money from the flows that those taxes tax can be saved. If someone saves money, me putting cash under a mattress or a billionaire that doesn’t spend their net worth, it hurts no one. Money is just paper, or even just electrical potential on a computer. What matters is when I go into a store, can I buy the things I want. Whether I can or not is a question of how the economy is set up, not how big a pile of almost worthless paper exists in a corner of somewhere. Money only truly changes the state of the economy when it is spent, not when it is collected or stored. Why? Because spending, consuming, is me telling the economy “these are the things I like”. If I’m rich and I like yachts, and buy yachts, the economy will allocate iron to making yachts instead of something else. If I buy bread, it makes more bread. To tax peoples wants and desires properly, you should use a consumption tax, VAT, and not anything else. You can also make it pigouvian rather than redistributive depending on how you spend it. Pay into the UBI and you redistribute from rich to poor. Fund carbon capture or sea cleanup or other ways of taking care of our earth, and you trade off consumption for taking care of earth and limiting how much we extract from it.
I haven’t run the numbers, but probably the smoothest operation (in terms of not causing crashes and shocks to the economy) is to use VAT incomes for such earth maintenance at the same level as the pigouvian LVT floor. So if you spend 100$ on carbon capture, it would be smartest to get 50$ from the land base rate and 50$ from the VAT.
What does this all mean?
We live off of our earth, and yet our economy lives off of us (mostly, 8 to 1 ish). Technology makes living off our land better, and yet, our economy only sees that when our labor and our machines are linked. Machines doing the physical, and us doing the cognitive, was a pretty good deal. A tight link. But technology always advances, and as its capabilities become more uniform again, the link erodes, and our economy loses sight of the thing we actually live off of, the land. We can balance this properly. Tax land and we give it value, the economy sees it, uses it properly. We then can lift our true minimum income above subsistence, by adding the proceeds to our wage. Tax consumption and we put a price on it, reigning it in, which we can do directly with VAT or indirectly with a floor on land taxes, paid not to people to consume but to protecting land (or us, in other ways). Otherwise, pay that money out to people, and pay it uniformly, because the economy is already doing the job of setting wages. If we want, we can redistribute further, from the more capable to those less so. That I leave up to you though, and if we can work in this new model of the economy, for once in our history that can be a fair debate rather than an impossible one.
The floor in the LVT is what allows us to say “Our earth has some intrinsic value to us, even if the economy can’t see it”. The UBI allows us to say “a person has some intrinsic value to us, even if the economy can’t see it”. We can do without these concepts if we have some other link to our land, but technology doesn’t guarantee us that link, and I’d argue it’s currently removing it. Technology giveth, and technology taketh away, if you’ll allow me to be a bit poetic.
I’m still working on the theory, mostly to put numbers on it so it isn’t just me waving my hands about. Some of the numbers already exist here:
Labor pressures causing market distortion and a minimally invasive solution. – Wilsons Blog
Disclaimer on AI use: I did not use any AI to write this piece, although some spelling checks I did get from Claude. I’ve also gone back and forth with Claude many times to check sources, refine points, and find the core of the idea prior to sitting down and writing this. The linked post above uses AI much more, both to write, and compute the various graphs.
Footnotes:
- I have a tangential thought that is bold and inflammatory and so I put it here in a footnote, since I haven’t fully thought it through. This dynamic is why redistribution amongst labor can never work as we would like it to. In a hypothetical pure labor linked economy, with no automation link, the minimum wage will always be at subsistence, i.e there must always be someone who lives at the level of subsistence if all our money is labor linked. If you try and raise up the poorest you can only ever do it temporarily, and you drag down our mean. In that setup, inequality between people is the only way for anyone to be above subsistence. Linking this to automation, if automation makes our capabilities more uniform, it pushes everyone towards subsistence regardless of what human->human redistribution systems we have. Perhaps that is why redistribution has seen such pushback in the last 50 years. Paradoxically, perversely, to raise the mean humans standard of living you can use inequality, and the lowest person will always be at subsistence. The only exceptions to this are the mechanics of ownership, and hopefully, our solution. ↩︎
- Patents and copyright are an interesting case. In theory, they allow you to collect value from an idea for some amount of time after the public receives it. The reason they exist is because ideas are otherwise extremely easy to steal. Although duplicating an idea costs nothing, it did cost something to come up with in the first place, at minimum, subsistence. The cost was paid before the thing came into being, and if it is copied on day one, the creator pays that cost and receives nothing in return. One alternative resolution is our UBI. An author can write if that is what brings them joy, and a UBI lets them do that without worrying (as much) if their idea will be stolen. But for a billion dollar investment, a UBI just cannot cover it. Since we cannot foresee the value of an idea prior to it hitting the market, and the idea could be readily stolen, we likely still need patents and copyrights. Setting the right time limit is hard but important. Too short and someone else taking the idea is rent seeking. Too long and holding on to the idea is rent seeking. In a perfect world they would last for as long as it takes to exactly offset the cost paid, but that balance is not something the economy can easily find for us. As a fun aside, this dynamic is currently hitting Anthropic and OpenAI pretty hard. Model weights are just numbers. If you could hold them all in your head, I could call it an idea. That’s why they have been so easy to distill, and arguably patent law should have protected the AI labs. The real ownable thing is, surprise surprise, the datacenters, the land the datacenters are on, the energy sources to supply the datacenters. Even if AI ends up being worth a bajillion dollars, my money is not on the people who only have an idea and no patent. Although I do feel a little sorry for them. ↩︎
- These arrows, from high incomes to low, are usually what we talk about when we talk about taxes and benefits. Even when we talk about wealth and profit taxes, we are mostly talking about this. It’s a centuries long debate, and to be honest I believe footnote 1 is the reason why we never resolved that debate, and if we do not increase the non labor-linked money flow, why we never can resolve that debate. ↩︎
- According to Korinek and Stiglitz we could actually go below subsistence, and that’s true but it’s important to describe what that looks like. It can’t actually go below subsistence if defined as “you die”. Instead, if the economy could not pay me enough for me to support myself, rationally I would just drop out of the economy. The thinking is this: in theory, if I tried hard enough, I could go into the woods and live off the land. That would be my subsistence. A rational agent who’s labor provided to the economy is worth less than subsistence to the economy doesn’t stay in the economy, they become unemployed. In practice this looks like becoming a dependent usually, in particular because I can actually provide my value to, say, my mum. Economics would tell us that that is impossible, in such a scenario my mum would pay someone else to do it better, but economics can’t see the value I personally have to my mum, as her child and family, so she takes care of me even if the economy never would. ↩︎
- The reinstatement effect and augmentation are the same. They only appear different because the former creates a new job seemingly out of nowhere. In some pure sense though, that job always existed, it was just economically underwater, not augmented enough to employ anyone. Augmentation improves until suddenly the job description comes into being. I could babble about programming languages and carve algorithms into tablets a thousand years ago, it’s just nobody would pay me for it. Soon nobody will pay me for it once again. ↩︎