When I really got into writing code (big projects, or for work), I really started using libraries. For so many problems, there was already a library that would help me with it. From doing maths fast with numpy to padding strings with left-pad, there was almost always a library that could help. Even now half the time you want to integrate your app with some other application it ships its API as a small library of useful functions. As much as I do like writing code to solve difficult problems, the project manager in my head is telling me “don’t reinvent the wheel”, so naturally I use a lot of libraries.
My favorite libraries were always the ones that were nice to me. They would let me pass in data in lots of ways and specify tons of options.

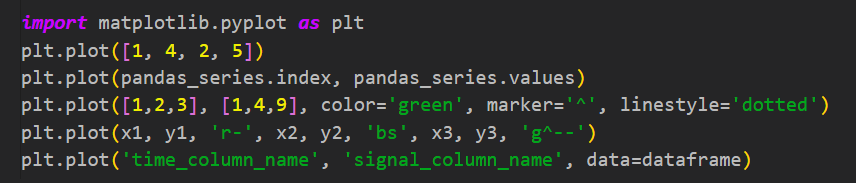
They would check lots of things for me often, and early in their call stack so that when I inevitably did something wrong, the error message could contain lots of contextual information. Sometimes they’d even tell me what code to run!

I was taking all this in. And of course, I would also learn how all this is best done by reading the libraries’ code. I might read it to solve a particularly tricky bug, to get around some poor documentation, or perhaps just out of curiosity. There in the open source I could see just how library code looks, and it looks a certain way:

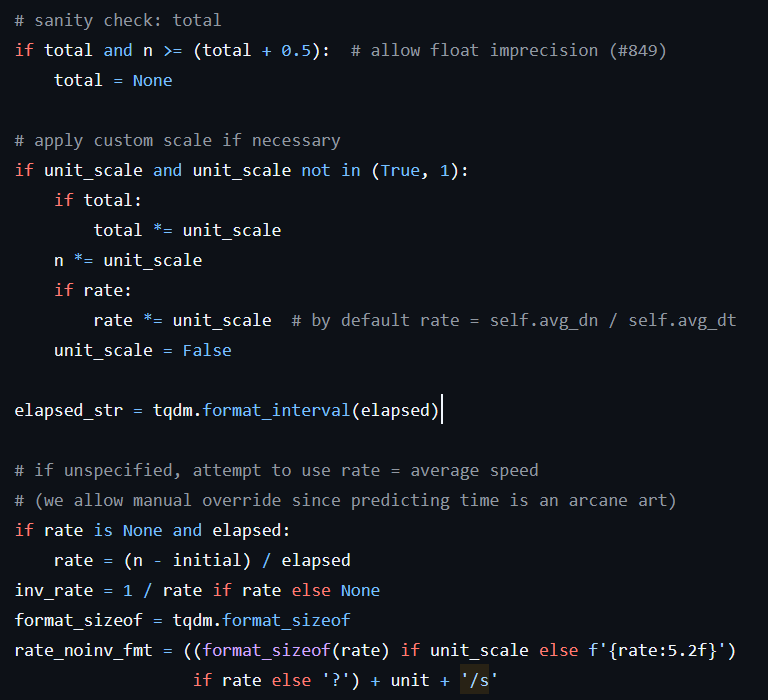

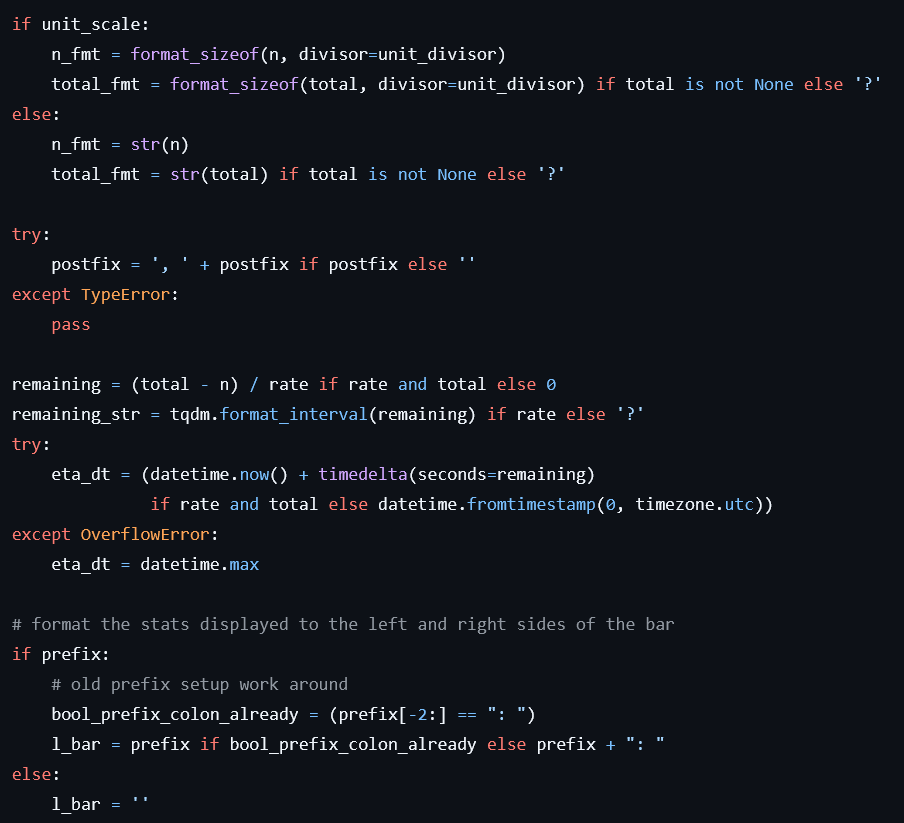
(This is the first bit of case handling in tqdm, a library that creates a little progress bar for your for loops.) Look at that! Check everything! Some if statements here, some type conversions there, exception handling, default values and assumptions galore. Don’t get me wrong, this is good code! Never have I been upset with the behavior of tqdm, it’s great. It works, it allows me to override what I need to, it gracefully handles what details it cannot work out itself.
So what’s a young coder such as myself to do? All these libraries I love have shown me the path forward. Sure, it’s a little extra work, but we do that work now to save us time in the future, no? Of the little other code I’m exposed to, it’s all bad and hard to read and so why not take inspiration from what is, to the untrained eye, the only way to write good stuff? We’re not building exactly the same type of programs as a library, but I’m still writing stuff that other devs will use and that’s kind of like a library. The choice seems obvious.1
Libraries have an unfair advantage in this clash of perceptions though. Two of them, in fact.
- They have hundreds if not thousands of users. These users will test edge cases for you, finding bugs faster. The ones you end up using in particular are popular just because they survived when other competing libraries didn’t. As such, it almost doesn’t matter how hard the library was to write or even maintain, the quality of the product is what won out.
- They are overrepresented. How many of the lines of code in the world are in libraries, compared to how much of the code you have seen or interact with? This is a selection bias, most similar to the friendship paradox. They have many users, so many people have interacted with more library codebases than simple chance would allow.
It’s not just me. Over and over I see people leave university and their small script projects and start asking “what does real good code look like” and this is the direction they go.
But let’s say instead you’ve read this and think, OK, fine, most code isn’t like a library. But shouldn’t it still aspire to the same standard? It’s GOOD CODE!
YAGNI and YAGWI
The obvious first criticism is You Aren’t Gonna Need it (YAGNI). Those libraries are like that because disparate users really do have different use cases and even a small convenience can matter a lot if it affects many people. A few dozen people in your team including yourself just aren’t as important. Once your code is in production maybe that assertion you made really doesn’t serve much of a purpose. Sure, down the line it will probably need to be maintained and that assertion might make it easier to catch some edge case, but it’s not as likely as you think.
But there’s another reason: You Aren’t Gonna Want it. This means that writing library code may lead to a codebase as a whole that is actually worse, harder to maintain. What we are partially talking about here is the robustness principle: “be conservative in what you do, be liberal in what you accept from others”. Specifically, about being liberal in what you accept. People have already written about how it isn’t always a good idea, but the gist of it is that when you allow for lots of different options and inputs, people are going to use them, and then you need to support them all, and that’s more effort than it is worth. If one of your colleagues asks “hey can you have the code take two lists instead of a dict I can’t be bothered to make it a dict” just say no. Their convenience is not worth it, at least not yet. Sometimes, sure, you’ve gotten the same unreadable error for the 20th time? Catch it earlier and make it readable. But the key is to build things when you truly need them. One day, if your code really solves some hard problem in a beautiful way, you can turn it into an actual library and distribute it to the world! By then, I assume you know what you are doing anyway.
So what does good code look like?
That’s pretty hard to answer. Lots of things matter for good code, this post is more about what not to do. But the core idea that “not writing library code” points to is: simplicity is valuable. We already mentioned YAGNI as a general concept but there are more good blog posts out there of things you can think about.
Let’s get more abstract
I want to put code on a spectrum, that ranges from “active” to “inactive”. Inactive isn’t the best name (sorry), it’s not meant to mean code that isn’t running or in use, it’s just not active.
There are two ways code can be “active”:
- It’s being heavily maintained. New features, significant bug fixes, refactoring and the like. This is what we might call “active development”, it’s what we think about most naturally.
- It’s regularly being called in a lot of new places. The code itself may not be changing much, but many developers are interacting with it for the first time, putting it through its paces regularly.
(There is arguably a third way, where users are putting code through its paces as they use an app in myriad ways, but for the purposes of this discussion it isn’t relevant)
The more active your code is, the more it will benefit from looking like library code. public facing actual library code is extremely active.
In general, code transitions over time from active to inactive. Unless you are actually writing a library, at first the code itself will no longer be under active development, and then later the code that uses your code won’t be under active development. At that point it begins to become inactive. Given that natural transition from active to inactive, in some sense, it might be optimal for code to start out as library code and slowly transition to being simple, static, no error checking and no frills code. Intuitively this makes sense: while people are developing on your code, give them nice error messages if they use your thing wrong. As soon as the program at large is “done” (insofar as that is possible for any code, another topic) then that input checking code doesn’t have as much value, perhaps less value than its cognitive weight. Actually doing this isn’t realistic though. We’re going to write it one way and that’s going to stay, or even go in the opposite direction as it accrues new frills and features. Oh well.
I didn’t have much more to add to that, it was just a final thought. Thanks for reading this, I hope it resonated a bit or at least was somewhat interesting.
- There is also something to be said of straight complexity. Libraries are hard to read, because the do tend to be big. Lots of code, complex architectures and structures, the works. But If they are doing it, and they are popular and have great programmers maintaining them, why shouldn’t we all do the same? ↩︎