The recent release of DeepSeek-R1 made a pretty big splash, breaking into the mainstream news cycle in a way that the steady model releases we’ve had for a couple years now did not do. The main focuses of these stories were that 1. it was cheap and 2. it was chinese, forcing the market to reconsider some of it’s sky-high valuations of certain tech stocks. However, there are other interesting things to consider.
What I was impressed by are the different ideas tested in the R1 paper. Epoch AI has an extremely good writeup that made it far more digestible for me, noting that there were a number of architectural improvements they’ve contributed (over multiple papers, not just R1). Many of these improvements are “intuitive in hindsight”, but I want to talk about one of the methods they use in particular. DeepSeek-R1 was trained by using a reinforcement learning algorithm which started with their classic style model, DeepSeek-V3. They gave it math and coding problems with exact solutions, encouraged it a tiny bit to reason (essentially to make sure it used the [think] and [/think] tokens), and then gave it a reward when it got the right answer. As one hackernews commentator put it “The real thing that surprises me (as a layman trying to get up to speed on this stuff) is that there’s no “trick” to it. It really just does seem to be a textbook application of RL to LLMs.”
One of the key challenges with this is having those exact solutions. Largely, we can only choose problems that have solutions you can compare against or check rigorously. For maths, it might be a number. For code, it may need to pass a runtime test. This is good but you can imagine a huge number of reasoning tasks (perhaps the most interesting ones) that don’t have clear answers. How best to run a particular business? What architecture, language and patterns should we use for a software project? What is the path forward for reasoning in LLMs? These are all questions you could ask deepseek, but how would you know what reward to give it? Well, what if we got deepseek to do it. Ask it, “How good is this answer?”
You can’t ask a model to train itself!
In the DeepSeek-R1 paper they write “We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline” Which is, indeed, a challenge. We’ve talked a lot about how slop proliferating on the internet could lead to a poisoning of LLM training data. We’ve seen how models, even if they know they are wrong, can end up going in circles trying correct themselves. What could the models possibly teach themselves that which they don’t already know? Here are the two key challenges with this idea.
- The model can’t teach itself new facts. If it doesn’t know something, judging its own reasoning process isn’t going to magically introduce those facts. It also can’t (in a simple implementation) test ideas to produce new facts.
- The model might collapse or reward hack. This might mean that if the reward step begins to reward something meaningless like niceness, the model will just become nicer, not smarter.
The first is not actually that big of a deal. DeepSeeks own research shows that most of the necessary facts are already present in the model, and what it needed was a training process to recall, consider, and reason around the facts it already knows.
The second challenge is much more interesting. If you start with a somewhat competent model, you might expect that it would view a “nice” but poorly reasoned answer poorly, since it has low informational content. One would hope that this would only improve the scrutiny the model would give to answers over time. To reward hack, the model would have to engage in poor reasoning, since in the question we asked, we “wanted” a sincere answer. We as humans can look at two chains of thought and roughly say which contains substantively better reasoning. If the model can do the same, it might just be able to continue getting better at this. What I’m trying to get at is that there may be a “collapse threshold”

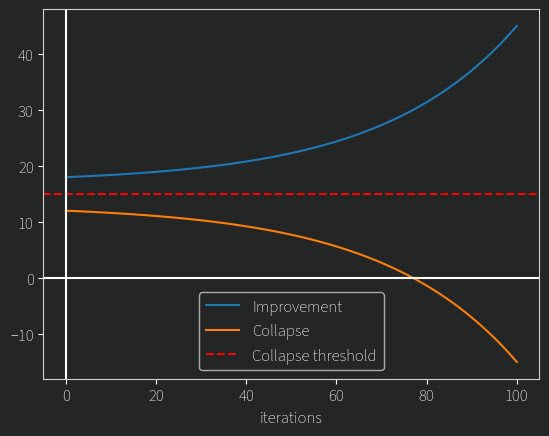
If the model starts out competent enough, it may be able to over time RL its way to being even better at reasoning, on basically any problem we give it.
Another important component that may make this work better is inference time compute. OpenAIs o3 has different compute levels corresponding to how much compute the model is given, essentially how long it is allowed to think for. You reasonably could give the reward step more compute than the problem step, on the basis that then you are trying to distill better reasoning into fewer reasoning tokens. This is very similar in idea to distillation of big models into smaller ones, but instead it is distilling long inference compute into short inference compute.
This will most likely reach some diminishing returns, unlike the naive graph I have, but we could augment the process with the ability to test. Lots of reasoning steps, both in solving and reward stages, could be “tested”, in that the model may want to search something or run some code. That may prove prohibitively slow, I’m not sure, but that might be mitigated by just asking the model to only reward tests that are necessary, and then both the problem and reward stages should end up learning to be lean in their usage of tests. It also still hinges on the model having a good intuition of what necessary searches means.
I’ve no idea if any of this actually works, I’ve only trained a few little toy models myself, and I’ve seen firsthand how they can collapse in all sorts of ways, but I do think ideas like this are worth trying. These are the ideas that are outside the reach of most research because they are premised on the fact that we can iterate on a huge and already very capable model. If it does work though, I do think it could lead to some significant improvements.