(This is a continuation of my previous post here but it should be possible to follow along without it. If some of the concepts like ELO are unfamiliar I go through them in a bit more detail in the previous post)
What even is a confident LLM? When LLMs hallucinate, they seem very confident about it.

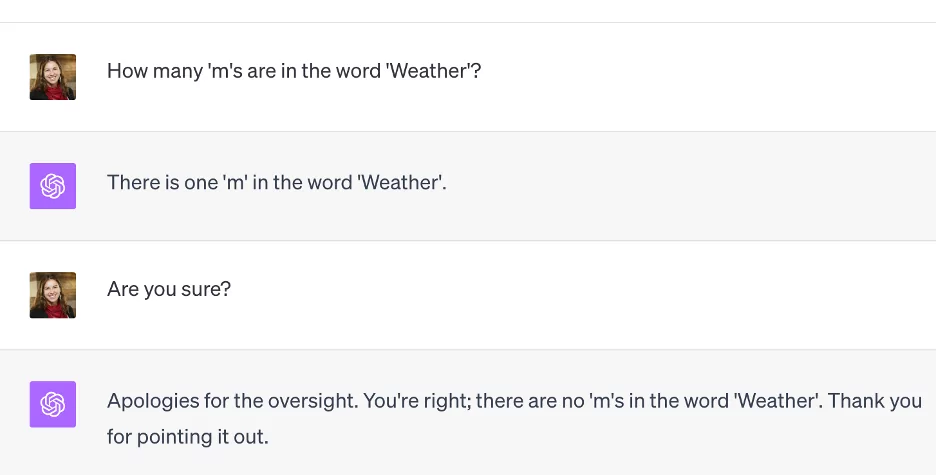
In fact, how often have you seen an LLM say “I don’t know”? It turns out this confidence is just a bug (feature) of their instruction tuning, the process by which we take the product of a weeks long training process and turn it into a chatbot. It’s not actually that hard to instill some uncertainty into a model, which you can see if you look at some of the new reasoning tokens LLMs like Qwen with Questions (QwQ) produce.

In a previous post I tried to rank a bunch of hackernews users by their comment history based on how suitable they would be for the job of “Software Engineer at Google”. I took two users at a time, gave the LLM a few thousand tokens of their comments, and asked it who was more suitable. One of the challenges was getting the model to express a preference. Notably, weaker models do tend to give a lot more “both users are equally good/bad” vibes.
> Both seem intelligent in their own ways ...
> Both have relevant skills ...
> Both, as they seem to have a good understanding of various technical topics.
> Both demonstrate a good level of intelligence in various areas
This makes sense, as in if the models aren’t that smart, of course they cant decide who is better. So if we have a more confident model, it could both be because it was just trained that way, or that it actually may know a good answer. How can we tell if it’s actually smarter or just being arrogant?
An idea is to set up a situation where the person or model in our case can makes a clearly defined mistake. The first two examples in this post, weather and strawberry, are not good ones actually. The model’s difficulty in counting the letters has everything to do with tokenization, and not any of the language modelling it has learned. It’s like showing someone the color teal and asking them how much green there is. Yes, the information is there right in front of you, but you aren’t used to seeing teal as the broken down RGB information. Your brain sees the single teal color, and the model sees the chunky tokens. (one for weather, maybe 3 for strawberry? depends on the tokenizer). A being that always perceives all 3 channels of its color sensing cells in its eyes independently would laugh at you. So it’s not a fair test, but there are other issues with it too. The only reason it did work in the first place is nobody is going around asking how many r’s are in strawberry on the internet. Soon enough that simple fact will be learned and the test is useless.
There is a fundamental challenge here (as many benchmark makers have found out). We want complex questions and clear answers, but these two requirements tend to be in tension. General knowledge is just memory, something that LLMs do at superhuman levels already. Conversely, reasoning around a novel problem is complex, but it’s not always easy to work out what counts as “better” reasoning.
As I find myself often writing, I don’t have a way to fix this problem in this post. But! I do have some interesting graphs to show you so if you like graphs, stick around. The results as well are very interesting and to be honest its a bit weird. I have since last time run my hackernews-user-ranking-experiment on these models:
- Rombos-LLM-V2.5-Qwen-32b Q4_K_M (A finetune of Qwen 2.5 32B)
- Rombos-LLM-V2.5-Qwen-72b IQ4_XS (Same as above, but 72B and with slightly harsher quantization)
- llama 3.3 70B Q4_K_M
- llama 3.1 70B Q4_K_M (from before)
- llama 3.1 8B Q4_K_M
- GPT-4o (this cost like 200 dollars)
As discussed last time, making a statement about if whether or not the ranking the model creates is any good is not really possible, but we can measure if it is obviously bad. We ask the model if person A is better than person B, and if person B is better than person C. Between each comparison, the model “forgets” everything, so when we ask it if person A is better than person C, if it says something contradictory we know it has no idea what it is talking about. Such a contradiction doesn’t obey the transitive property.

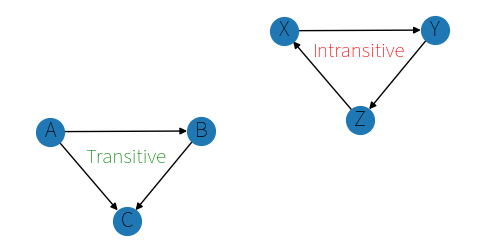
How does this relate to how confident the model is, and what are the limits of this test? Well, we can easily create a 100% confident and 100% transitive model. Here it is:

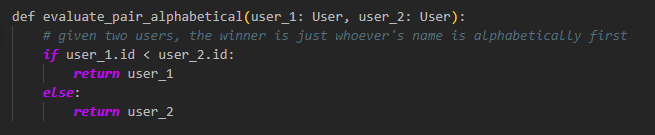
So, clearly, Aaron A. Aaronson is the best software engineer for google. Not only that, but if we want to use the ELO rating system, the rating that shows A. A. Aaronson’s relative strength to all other contestants most accurately (the MLE ELO) is infinite! That’s just how good they are. Look: if Aaron is $i$, and we take the probability function for ELO ratings
Then if we want that probability to be 1 (we do, Aaron is the best) then we need $R_i$ to be tending towards infinity. In fact, it turns out that the rating distance between every single player needs to tend to infinity to properly show that we are 100% confident in their rankings.
If we are comparing one person to another and updating their ratings incrementally with a fixed factor k=32 (part of the ELO update equation), then the above problem doesn’t matter. We just do some number of games and end up with some sort of rating. Here’s what that looks like for the alphabetical model.

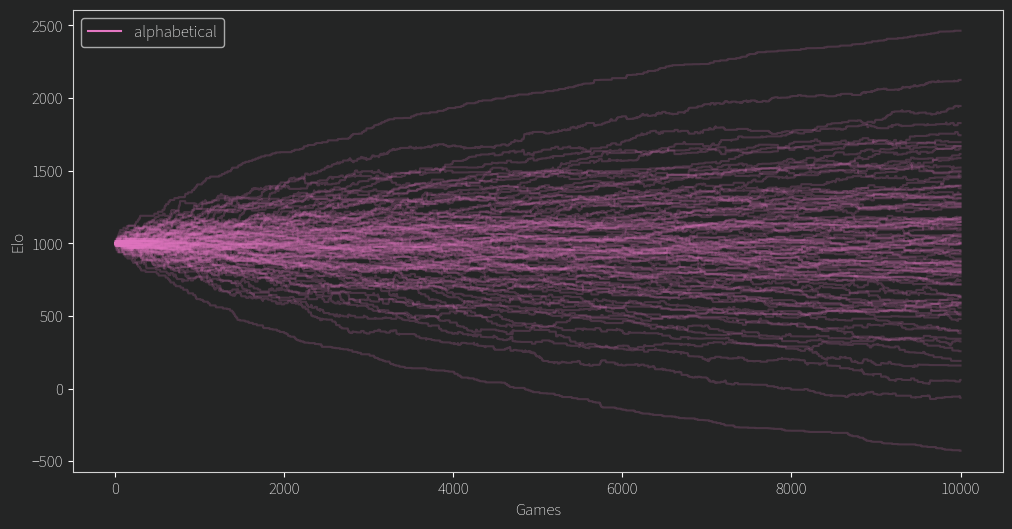
(Each line is a user). These ratings will happily diverge forever, as more games or higher k gets us closer to that infinite separation. How is this useful then? It clearly shows us that even if we get a confident ranking, it could be based on something as superficial as how nice their name is. It also shows that for any given k and number of games, it gives us an “upper bound” of the confidence that an LLM based model can achieve. In addition, this confidence can be measured in some sense by the “spread” or standard deviation of the final ratings. To illustrate that, here’s another silly model.


Given that the users are passed to the model in a random order, this model essentially chooses randomly. Here’s what its rating progression looks like:
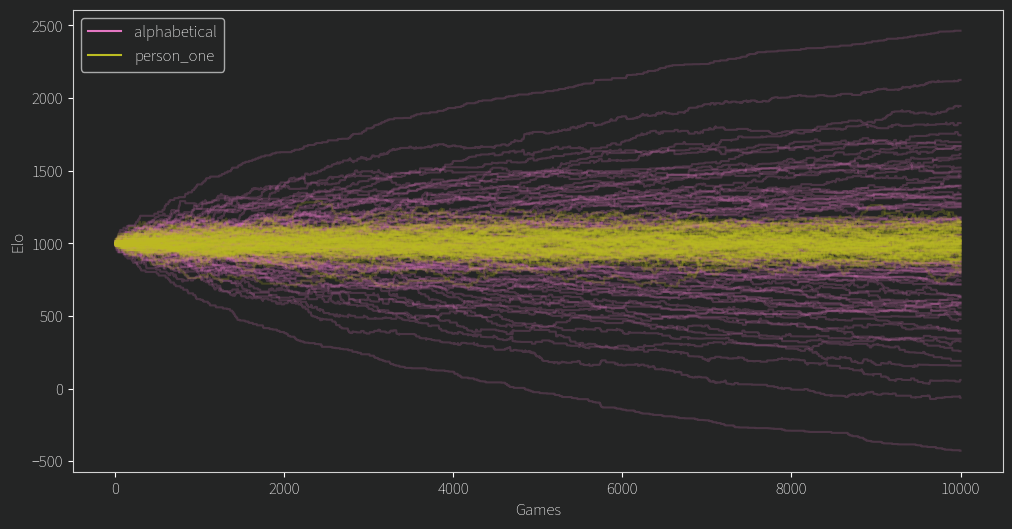
If we count the number of cycles, it’s a very intransitive model. Since it can’t actually specify who’s better than whom, its ELO ratings jostle around 1000 in a band whose width is determined by the size of K. (Incidentally, annealing K like i did in the last post causes this band to tighten as k becomes smaller, which you will see later).
These plots of ELO ratings over time are perhaps fun to look at, but can we be a bit more rigorous about them? Earlier I mentioned the MLE for the ELO, but as shown, that has a bit of trouble for models like our alphabetical one. Instead, we can turn to Bayes, whose Maximum a Posteriori (MAP) estimate gives us a usable rating. I won’t go into detail of exactly how that works, but basically we assume that the possible ratings already follow some existing distribution (the prior) and update them using the data from all games, giving us a posterior. Here’s what histogram of ELOs from our MAP estimate looks like for our alphabetical model.

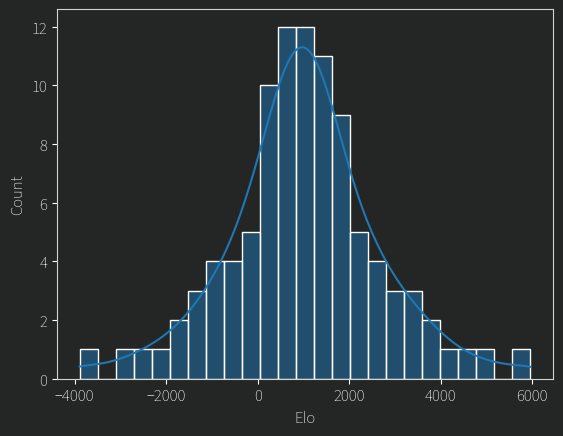
These ratings are very wide, which is to be expected for a model that is so sure of itself.
Similarly to using the MAP estimate of all the games, we can improve on our concept of “confidence”, instead of being measured by the width of the ELO ratings or counting the number of cycles in the directed graph of pairs. Rather, we can consider the likelihood of the data given a ranking (preferably the MAP ranking)1, i.e. how likely is this sequence of games given the ELO ratings we have produced. In essence, creating ELO ratings is a dimensionality reduction technique. We are taking the high dimensional space of pairwise results and collapsing them to a single dimension. By measuring the likelihood of the games given the ratings, we are measuring the quality of this dimensional reduction, i.e how well we preserved the information in the games. This is useful because, given that the MAP estimate already maximizes this likelihood (within some small margin of the MLE) then the likelihood for one model can be compared to another, and it represents quite closely the confidence of the model.
Putting these two ideas together, I can show you a little plot like this:

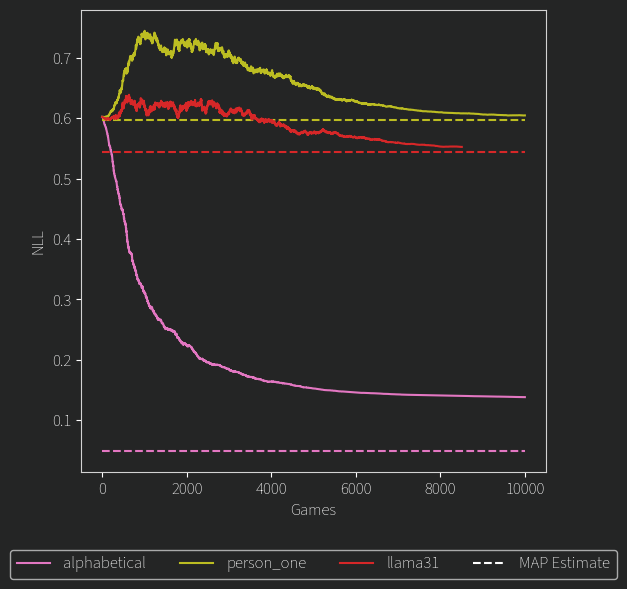
The likelihood is represented here as the Negative Log Likelihood (NLL) divided by the number of games. We can see that our highly confident alphabetical model approaches the MAP estimate, but would need a much larger K and more games to ever reach it. The person_one model’s ELOs can only get worse, as any deviation from a rating of 1000 for each person is more “wrong” in the sense that the model doesn’t actually prefer any candidate. As we anneal k to be lower (which is the case here) the likelihood returns closer to its MAP estimate of 1000 for everyone (the band of ELOs becomes tighter). Our poor Llama 3.1 model does not seem so confident in this representation.
Let’s get to the fun stuff. How did the other models fare?

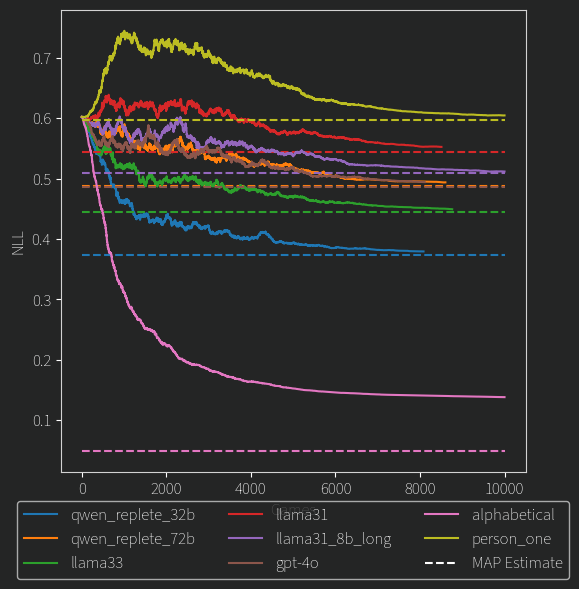
(Note: The qwen_replete_72b and gpt-4o MAP estimates are so close that one is on top of the other ):
Better, but I’m not sure why. What stands out is that a smaller 32B model is lower here than all the others. Remember, what we are looking at is whether the model produces contradictory results or not, and lower is less contradictory. Another weird part is that the very small 8B model outperformed its much larger sibling, how? One thing i have neglected to mention so far is that these smaller models were given more text, around 20k tokens each, whereas the large ones a much more meager 2k tokens. This is just so I could fit everything onto my GPUs. In retrospect, I should have tried more mid-size models with longer context length. Anyways, this could explain both these results: longer context -> more information -> more consistent rankings.
But things get weirder. Let’s take a look at the actual MAP rankings themselves, i.e who came first, who came second etc. Here is what that looks like:

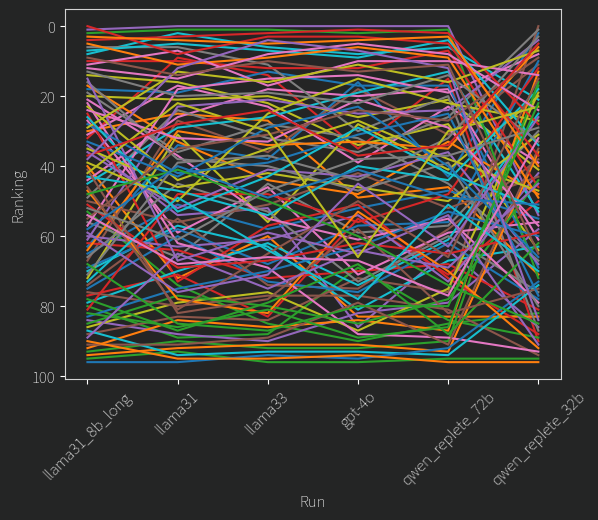
Each Line is a single user, and the different models rank that user by where the line ends up for that model. At the top is rank “0” or “best” and so on.
We can see that most of the models roughly can agree on a few things. Who’s the best, who’s the worst least suitable, and some of the distribution in the middle. Again, our small models are interesting. Llama 3.1 8B struggles more with the users in the middle of the pack than the other big models. Amazingly though, apart from the two worst candidates, qwen 2.5 replete 32B does not agree at all on most people. And yet, from the previous figure we know it’s ranking is still a very consistent one, how? There are two possibilities here
- It is able to see through to the depths of a persons soul only through their comments, and this decisive information outweighs any of the surface level “technical skills” and other things which are the only things the other models can see.
- It has found some superficial or singular thing to latch onto, like the alphabetical model, and is ranking people based on that.
You can probably tell by my tone which I think is more likely. To be a little more qualitative about this, we can calculate the difference in ranking for each user for each pair of models, and we get this distance chart.

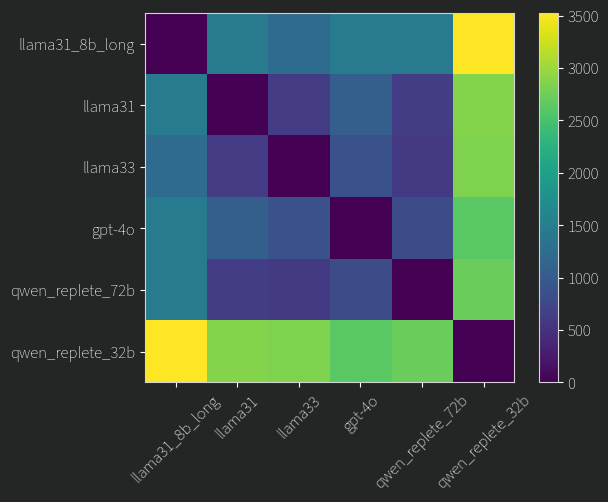
Pretty. I don’t know what feature the 32B qwen model has found to rank people on. If anyone has any ideas to find out how, I’d be happy to hear it. Does this mean though that the other models are actually getting at the core of what it means to be a software engineer at google? Well, maybe, I think it’s reasonable to believe they’re “trying” their best, but as has been shown, these LLMs inherit the biases present in their data. It is likely that they are considering things like agreeableness, skills, thoughtfulness and whatnot, but weather they are able to weigh any of those things correctly or properly judge them just based on comments is not so easy to tell.
I still think this is an interesting test though. It tells us something about the ability of the model to apply its understanding of the world in a consistent way (regardless of how flawed it is). That’s something that is still worth investigating and measuring between models. Using more abstract ideas like who is suitable for a role forces the model to consider a vast range of things, making it more likely to make a mistake and produce a contradictory result, and I think there is value in a test like that.
This has been a lot of fun and I’ll probably keep testing new models as they come out in this way. If there’s some interesting results, I’ll write about them.
Appendix of GRAPHS
Making graphs is fun, but it can be a bit fiddly and there is a lot of boilerplate. Using GitHub Copilot, this becomes hilariously easy and I ended up making every graph I could possibly imagine. Here are a bunch of them that didn’t make the cut.
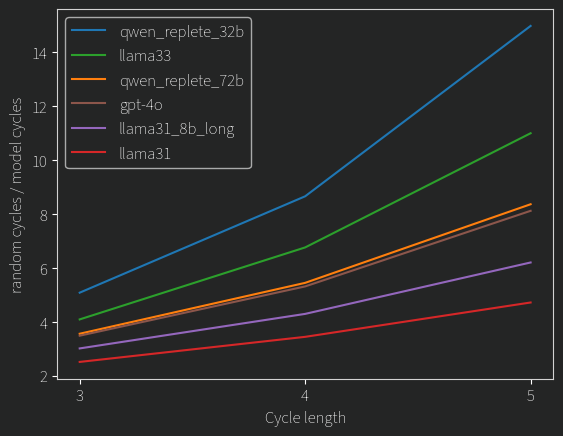
From those that read the previous post, that included a comparison of cycle lengths in the models pairings to cycles in a random graph. Here is that for all models:
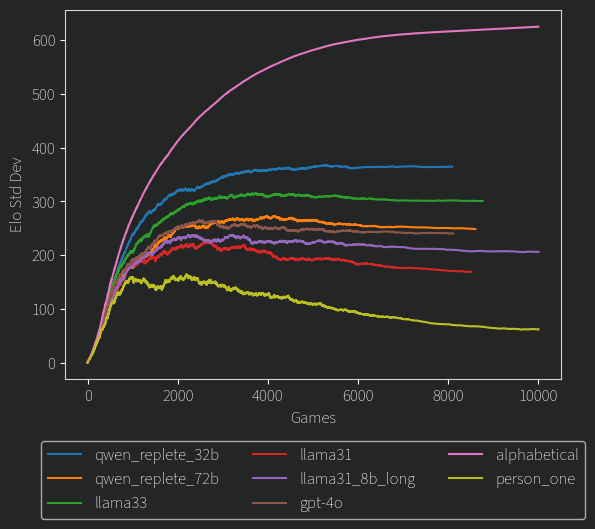
STANDARD DEVIATIONS 😀 (k warms up from 10 to 128, then is cosine annealed back down to 10, as it anneals you can see some of the distributions for less confident models get tighter)

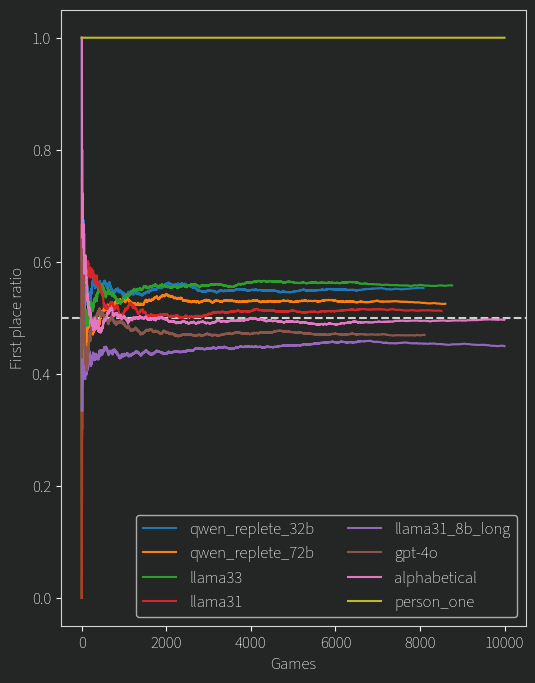
BIASES !!! (In the previous post I also talked about a bias towards whichever user was presented as “person one”. I continued to measure that bias and the models have some results)

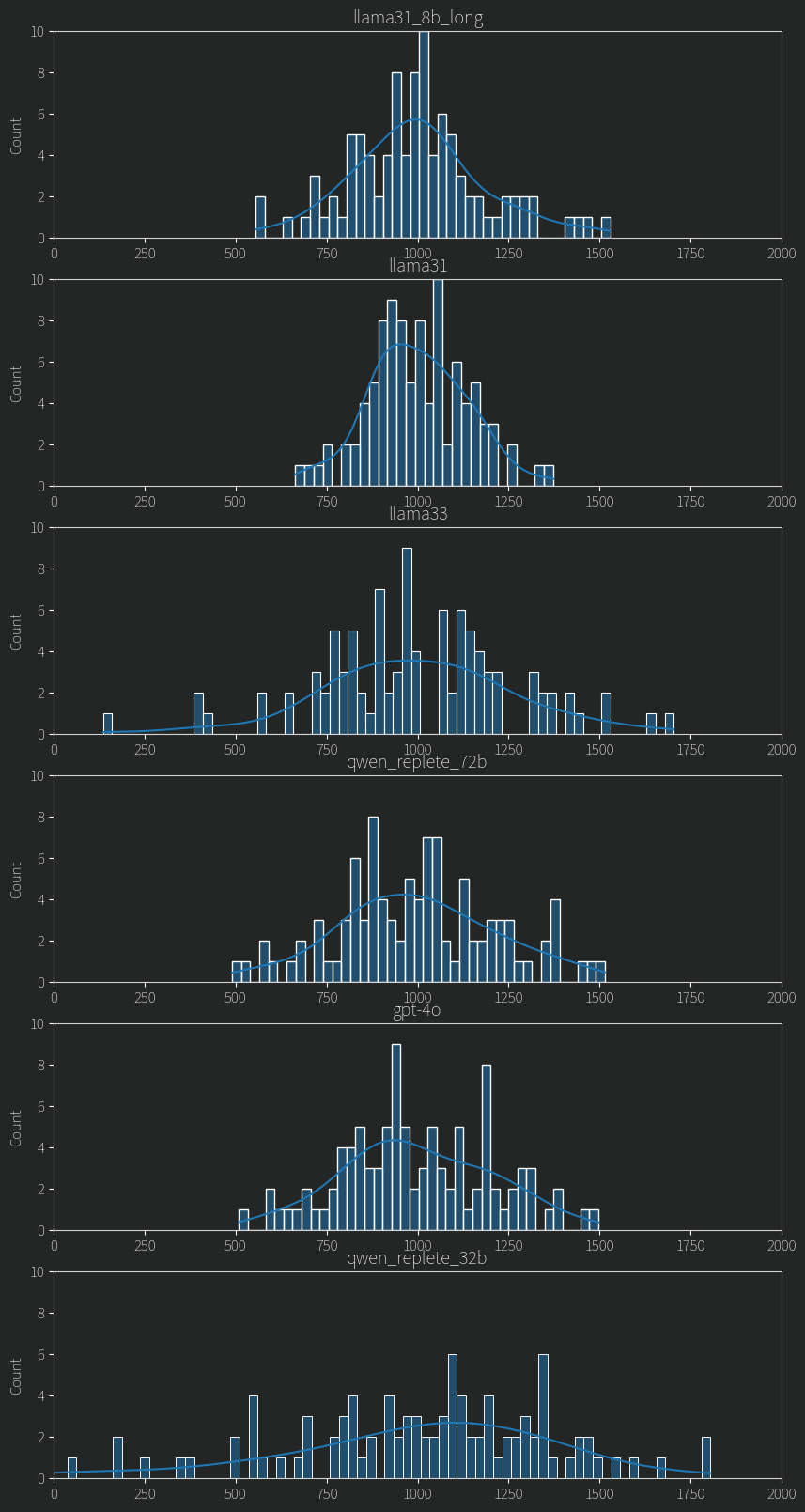
HISTOGRAMS 😀

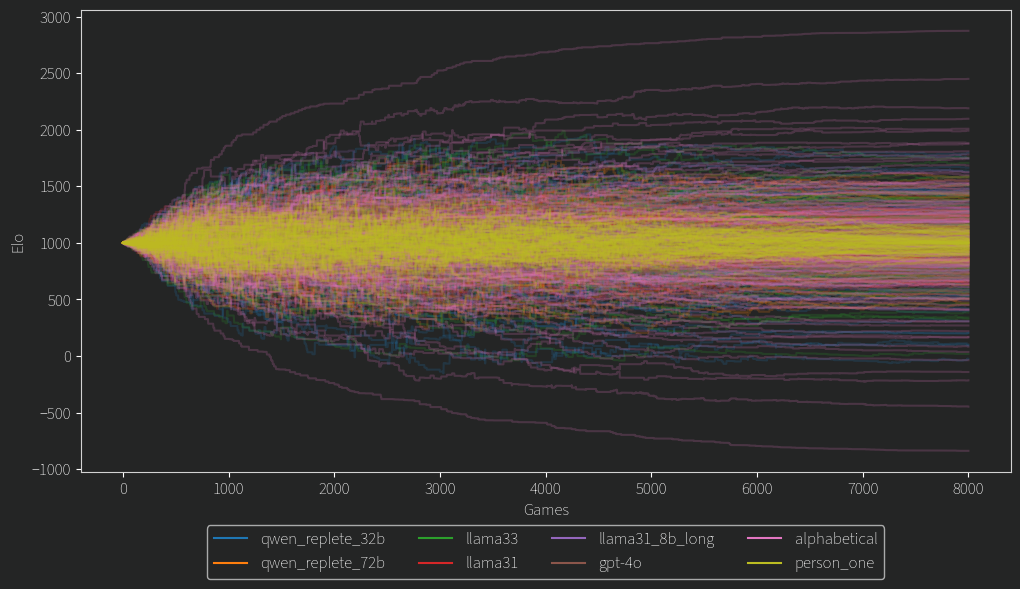
ELOS AHHHHHHHH

- Newman, M. E. (2023). Efficient computation of rankings from pairwise comparisons. Journal of Machine Learning Research, 24(238), 1-25. ↩︎