Last year I created a fun little experiment where I asked a bunch of LLMs to rank 97 hackernews users using their comment history based on whether they would be good candidates for the role of “software engineer at google”. (yes yes, seems silly I know, you can read part 1 and part 2 but they are long).
In it, I had a persistent problem of bias. I had arranged the comments in an interleaved fashion like this:
Person one: What makes you think that?
Person two: When I was a lad I remember stories of when...
Person one: Great post! I particularly like the things and stuff
...
The users aren’t responding to each other, that’s just how I arranged the comments in the prompt. I didn’t give the model the users names for obvious reasons. Then the model says who it prefers, and using many pairwise comparisons we can come up with a ranking (similar to the way chess rankings work). However, I noticed an odd bias. Even though which user was named “Person one” in the prompt was random, the model still preferred whoever got the name “Person one” slightly more often than not (or for some models, preferred “Person Two”). This is dumb. There is no reason to prefer them for being called “Person One”. It should be considering things like, would they be a good colleague etc. In the end, I evaluated all my models across all 8000 games each played, including some dummy models like one that always chooses “Person One” and one that alphabetically ranks the users. I then compared the ratio of “Person One” as it converged across the games played. Here’s what that looks like:


The models should hover around that white dashed line. But they don’t. This isn’t just bad luck. The two tailed p-value is vanishingly small after 8000 games for this sort of result (except for the alphabetical model, understandably).
This was very frustrating and I tried a number things to reduce the bias (messing around with prompt formulation etc), but couldn’t get it much better. No matter. I pressed on and found interesting results anyways and wrote about them. The bias wasn’t that bad and, since the order was randomized, it becomes random error, diluted by a larger and larger number of games.
That bring us to today and as-yet unfinished work where I’m asking people (real ones, I promise) to rank TTS voices based on attractiveness.
What better way to do ranking than pairwise comparisons, I thought?
Guess what.
Go on. Guess.

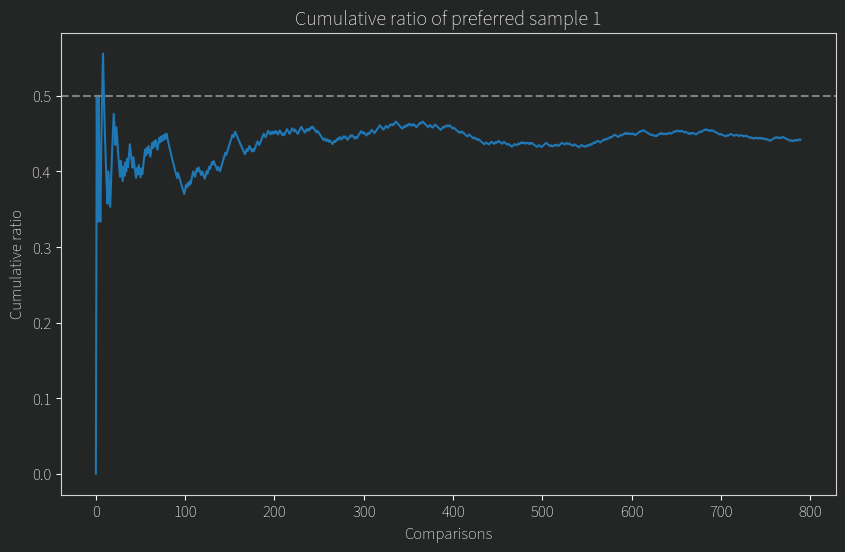
Surprising? Ok, maybe not in retrospect. So what if humans who can’t distinguish two TTS voices have a bias toward the sample presented to them on the right hand side of the screen. Indeed, “preferring stuff on the right hand side” has even been studied [1].
And, I’ll admit, the TTS voices do sometimes sound pretty similar.
Still, to me, this is a little bit cathartic because a) I was quite frustrated by the LLM bias and b) some commentators also said this invalidates the results, which hurt a little. Of course, this bias is still bad, and highlights the need to have things like large sample sizes and randomization. I won’t go much further and get too abstract here, but if there’s another, broader takeaway you could have, it’s that a lot of the safeguards and policy we have to manage humans own unreliability may serve us well in managing the unreliability of AI systems too. Maybe. We’ll have to see.