(This was originally written as an assignment for my masters studies, I thought it might be interesting, read at your own risk etc.)
A lot has been written about the history of artificial intelligence and so there won’t be much new things I can add. In general I find it hard to write summaries of what I’ve read, since usually someone smarter and more experienced has done a better job already; simply knowing that is enough to slow the process of writing down significantly. However, I can still try my best to do this and and focus on the parts I find the most interesting. I’ll try and make this easier for myself by talking about the history of artificial intelligence from the perspective of Rich Sutton’s “The Bitter Lesson” [1] which,
[…] is based on the historical observations that:
- AI researchers have often tried to build knowledge into their agents
- this always helps in the short term, and is personally satisfying to the researcher, but
- in the long run it plateaus and even inhibits further progress, and
- breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning.
Broadly, I believe this phenomenon explains the cyclical nature of the artificial intelligence field, the various “AI Winters” that have occurred. To justify that, we’ll have to take a closer look at the various developments over time and see if they fit with the theory.
A Brief Definition
The bitter lesson is about the whole field of “AI”, and specifically how the subsets, of brute force search and machine learning, have come to out compete other methods. Perhaps the best way to illustrate the definition of these terms is to use this venn diagram from Ian Goodfellows Deep Learning [2]

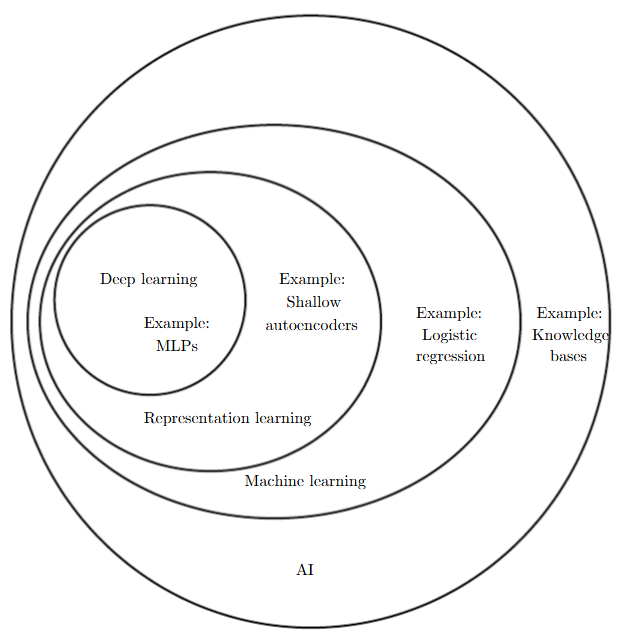
Where search methods would still fall outside the category of machine learning, sitting alongside knowledge bases. This also quite conveniently follows the pattern of the bitter lesson, where as we go further towards deep learning, more computation invariably is the cost of obtaining greater generalization.
Where to even start
I want to finish with Large Language Models, so let’s start with the advent of Natural Language Processing (NLP). Early language models in the 1950s began with machine translation, and were structured as knowledge bases. That is, they had a fixed set of words that they knew, they knew what those words were in another language, and they had some rules to shuffle around or add modifications to the words. There is no learning process here, just human experts trying to code a machine to turn one set of text into another. Not only was this not very good, there was not much advancement for decades. Google translate was using a slightly more advanced method, statistical machine translation, but its performance was still sub-par. Then, in 2016, they switched to a deep learning based approach. [3]
Ok we’ve gone too fast, perhaps NLP wasn’t the place to start. But it does hint at the fact that although dealing with language was something researchers wanted to do very early on, the field was not doing much for a long time. This is common for many application areas. Initially, a few smart minds come up with some half decent expert knowledge based approach to a problem. That approach is iterated on for a number of years until some novel method is applied to the problem, massively outperforming what came before, at which point the problem is “solved”. How long it takes form the start to the finish is not something that is easily apparent. The AI springs (and winters) come about when the success of such a new method convinces people that this new method is the way forward for many things (the spring), only to then later be disappointed that it was not nearly so universally applicable (the winter).
Let’s take a look at some more of the history. Perhaps the first case of a problem being completely “solved” is the aptly named Logic Theorist and its successor the General Problem Solver. Such an optimistic name comes from the idea that, if a problem could only be described in a Well Formed Formula (WFF) then all problems can be solved by the General Problem solver. The solver is able to reliably and accurately solve such problems, so in some sense it is perfect for the job. However, it turns out that formulating WFFs is a significant part of the challenge. A similar logic based system encompassing all human knowledge was developed called Cyc, with its own language CycL that would be able to infer things about the real world given a ruleset for how everything worked. Unfortunately, when given a story about a man named Fred who was shaving in the morning, it asked weather Fred was still a person while shaving. It did this because, since people don’t have electrical parts, and FredWhileShaving contained electrical parts (an electric razor), they would not be a person anymore [2].
The original problem continues to be solved by the descendents of the Logic Theorist, in languages like prolog and theorem provers like lean, but overconfidence in how this same method might be applied elsewhere has led to disappointment. It was hardly applicable to many areas, yet still, the method of knowledge bases continued to be applied through projects like Cyc which were pursued for decades (whose target problem to solve was essentially common sense, we’ll return to that later).
Other developments were happening in the field of AI that would lay the groundwork for today’s AI spring. In 1957, the perceptron was the first model that looked somewhat similar to the neural networks of today. Although modern neural nets are champions of the idea that models should be able to learn for themselves without human meddling, the perceptron did not fully embrace that. It took many inspirations from the human vision system, incorporating features that later neural nets would do away with, such as feedback circuits (even if those would make a comeback in the form of RNNs). While brain systems are a good source of inspiration, becoming too attached to them can lead to higher complexity systems with diminishing returns in performance. The complexity is also a barrier to more significant changes that might allow for breakthroughs. This is one of the components of the bitter lesson and is why new developments often come from newcomers to the problem area (at the annoyance of those already heavily invested in their chosen method)
After the failure of the perceptron came one of the more significant AI winters. Overpromising and underdelivering led to significant skepticism in the field. Even though we now know they did make a comeback, the few researchers who continued working, with what little funding was available, are owed a great deal of credit for continuing. As fields mature it can often become harder for newcomers to enter them, especially with very different ideas, and it wasn’t guaranteed that these dormant methods would ever come back. Indeed, with todays extremely deep and dense fields, there is more reason than ever to try and bring ideas into new domains, something that happens seemingly more rarely. Partly this may be due to the complexity of the problems we now tackle and the requirements put on modern researchers.
Around the 80’s another nature-inspired method was developed. Not a model in this case, but a method of training, reinforcement learning, although it was formulated much earlier. Reinforcement learning is based on the idea that both exploration and exploitation are important. That is, a model may explore strategies that it does not necessarily know the value of or even think is a bad idea, but then can learn from the outcome of this exploration, rather than always choosing strategy it believes is currently optimal. Classically, reinforcement learning is extremely computationally costly, in that often many simulation steps need to be taken before any reward is given, and a model may spend significant time without much improvement. Because of this, it is often augmented by heuristics, or sub goals as defined by a human. We’ll return to this in a bit.
Another good example of the bitter lesson is the next challenge, chess. Like with most problems AI researchers set out to tackle, many said it was impossible. More interestingly though, even within the pursuit of the chess engine, ideas were split as to the best approach. For every researcher, there was a certain amount of time one could spend finding new heuristics to improve the quality of move selection, or one could spend that time optimizing the depth of search. Expert systems not that dissimilar from knowledge bases were initially somewhat successful, but deeper search methods won out in the end, with of course the assistance of newer, more powerful hardware. What is notable here is that, in contrast to the bitter lesson, expert systems are making a sort of a comeback. Modern computer chess tournaments put limits on the compute time available to the algorithms such that optimizations to strategy are once again worthwhile. However, it is worth noting though that this is an artificial limitation, and it was without these limitations that Deep Blue beat Kasparov in 1997. In that sense, the original problem was still solved by force, not formulas.
Around the same time, we get other non neural machine learning methods that begin to have some successes. In computational biology, Hidden Markov Models (HMMs) were being used to predict how proteins would fold. This was in many respects not an expert system. Seemingly having learned from The Bitter Lesson, The Folding@home project aimed to utilize many at-home idling compute resources to simulate possible protein folding [4]. It has been active for many years and did produce some significant results. Other groups pursued similar simulation methods to protein folding. However, around 2020 an Alphabet research group produced AlphaFold, a deep learning based neural network that could predict how a protein should fold. It outperformed other methods by quite a wide margin, and shows us that the bitter lesson is not just about leveraging computation, but also how well that computation scales.
If we return to search, games such as go have also been solved, in this case by the same team as that which made AlphaFold. AlphaGo has some search techniques, but also leverages a deep learning neural net called a ResNet, the same as AlphaFold. In the original Bitter Lesson, Rich Sutton identifies both search and deep learning as generalizing well, however, it might be the case that even search may be outdone by deep learning methods. It does not seem infeasible that if we were to return to chess, we may be able to create chess algorithms that, given enough compute, could outperform existing search based models. This is not necessarily the case: In even simpler games such as tic-tac-toe, where all possible game states are enumerable in memory, perfect play is already known and there is no model that could do better (with the exception of faster play). If this theoretically optimal play that chess can have is already in reach of search algorithms, then there is nothing that a deep learning algorithm could gain.
Computer vision also had similar such developments over the last decades. Early computer vision systems competing in the Imagenet competition used feature selection, another method by which pesky human interpretation is forced into our models, under the belief that this will lead to better outcomes. This involved devising algorithms that would detect edges, contours and colours in an image and feed that into a statistical or regression based model. In contrast, AlexNet, a Convolutional Neural Net submitted to the competition in 2012 significantly improved on the best scores of previous models in the competition. Although its convolutional system also did some similar edge and feature detection on input images, the model selected those convolutions itself, rather than with the guidance of an expert. Its architecture was able to identify features such as faces in its output mappings without any help, meaning during training the model not only worked out that faces were important but also developed a set of weights to detect faces without there being any feature or label for faces in the dataset at all.
This has been a bit all over the place so let’s summarize a bit at this point before we talk about the present and future.
- The bitter lesson tells us that improvements in computation will mean computationally infeasible (but better scaling) methods will win out over expert-written ones.
- Search may actually not be an equal to deep learning in terms of how well it generalises.
If we are looking for models that generalize, none may generalize better than Large Language Models. The case of the aforementioned Cyc system would hardly be a problem for a modern LLM. For the problem of common sense, apart from notable edge cases, LLMs eclipse all other attempts at their task. Not only that, but they are passably able to tackle many of the aforementioned problem areas. Vision nets can be attached to LLMs to make them multimodal, and now are not only able to classify contents of images, but reason about them (to the extent that they are able to reason at all). Similarly, LLMs can play chess [5], although not all that well. Conversely, problems that are outside of human reach are equally out of reach of LLMs. They can’t protein fold, decode encryption cyphers, and aren’t even that good at SAT solving. In this sense, they seem to generalize In the same dimensions as humans do albeit to somewhat different scales. I think that many of the things remaining things that humans have to do that we are trying to replace with AI systems may ultimately be replaced by LLMs, and the existing attempts to automate them will fall foul of a new, improved, bitter lesson.
But, how? Earlier we brought up reinforcement learning and I believe it can be an important next step. LLMs as of today are trained with a simple goal of predicting the next token in a string of tokens. When fine tuning a method called RLHF or reinforcement learning with human feedback is used. However, this is barely reinforcement learning. The issue is that once again subjective human judgment is allowed to creep into the value function of the learning process. Humans chose a preference from one ore more prompts, and then the model is trained to produce one prompt and not the other [6]. Ideally, reinforcement learning would have the LLM complete tasks with clear success and failure states. It is however likely that this could be massively computationally inefficient. Consider a task that we might want an LLM to do, say, run a business. Many RL systems would simulate a world in which the agent would act such that many RL iterations can be done quickly, however, the real world nature of the task we now want LLMs to do, like running a business, would likely suffer significantly if we attempted to simulate it (the complexity of the simulation would suffer from the same problems as Cyc). As such, we would have to actually put the LLM out into the world, have it run a business for a bit, wait for it to go bankrupt, and only then can we give it the reward (punishment) it deserves. That would likely involve going through all it’s actions and marking them down, training it not to say things like that. This, implemented how I’ve described it, would almost certainly not work, but it may be the best way of avoiding human subjectivity from getting in the way.
These agentic-LLMs are already in the works (sans RL). I think that pursuing them is a next step in LLM use. LLMs have developed a sophisticated worldmodel and a fact database far in advance of any human. What is lacking now is their ability to reason, act, and learn from those actions, which is unlikely to be achieved with more token tuning.
All this is but a small part of the long and storied history of trying to get machines to think. We have (and almost certainly will continue to) put significant effort into getting them to think like we do, rather than spending time developing ways that they can think for themselves. Thankfully, the bitter lesson is there to encourage us to not impart to much of our own ideas into the models we produce (and some biases I’m sure we’d all be glad to omit). Some things we will not escape, LLMs have shown to pick up on much of the stereotyping and trends present in the data they consume, but it would be good to not accidentally put more in.
Use of LLMs
Apart from helping a couple times with finding a few more examples, I didn’t use LLMs to generate this text. You may notice that it is a little less “professional” sounding than an academic text might usually be, and this is intentional. Although I can (begrudgingly) write more formally, I find that doing so makes it feel like what i am writing is more like what an LLM might produce. It isn’t just the use of “big words”, flowery language, and other features of LLM-ese, but that since it isn’t the “real voice” inside my head it isn’t really authentic. I’m modulating my writing to sound a certain way, and it makes writing harder. This is a feeling I’ve had even before LLMs came along, but is even more pronounced now. I hope you can forgive it.
References
- Rich Sutton. (2024) The Bitter Lesson. Retrieved December 17, 2024, from http://www.incompleteideas.net/IncIdeas/BitterLesson.html
- Ian Goodfellow and Yoshua Bengio and Aaron Courville. (2016) Deep Learning. MIT Press, http://www.deeplearningbook.org
- Joe Sommerlad. (2024) Google Translate: How does the multilingual interpreter actually work? | The Independent | The Independent. Retrieved December 17, 2024, from https://www.independent.co.uk/tech/how-does-google-translate-work-b1821775.html
- https://foldingathome.org/
- https://dynomight.net/chess/
- https://x.com/karpathy/status/1821277264996352246